DB
GROUP BY 절
Basic syntax)
SELECT [단순컬럼1, ] .. [단순컬럼n, ] [표현식1, ] .. [표현식n, ] 그룹함수1, 그룹함수2, ... 그룹함수n FROM table [ GROUP BY { 단순컬럼1, .., 단순컬럼n | 표현식1, .., 표현식n } ] [ HAVING 조건식 ] [ ORDER BY caluse ];
주의할 점1:
GROUP BY뒤에, Column alias or index 사용불가!!! - 묶을 컬럼 명만 적어라
주의할 점2:
GROUP BY뒤에 명시된 컬럼은,
SELECT절에 그룹함수와 함께 사용가능!!
주의할 점3:
ORDER BY절의 다중정렬과 비슷하게, 다중그룹핑 가능
주의할 점4:
WHERE 절을 사용하여, 그룹핑하기 전에, 행을 제외시킬 수 있다!!
주의할 점5:
HAVING 절을 사용하여, 그룹핑한 후에, 행(X)이 아니라, 그룹(OK)을
제외시킬 수 있다!!
주의할 점6:
WHERE 절에는 그룹함수를 사용할 수 없다!!
*주의할 점7:
GROUP BY 절은 NULL 그룹도 생성함!!
부서별 GROUP BY - 부서를 묶음으로 평균월급을 구한다.
SELECT
department_id AS 부서번호, -- 그룹생성 단순컬럼
avg(salary) AS 평균월급 -- 각 그룹마다 적용될 그룹함수
FROM
employees
GROUP BY
department_id -- NULL도 그룹으로 생성 (*주의*)
ORDER BY
1 ASC;부서별 GROUP BY - 부서를 묶음으로 최소월급과 최대월급을 구한다.
SELECT
department_id AS 부서번호, -- 그룹생성 단순컬럼
max(salary) AS 최대월급, -- 각 그룹마다 적용될 그룹함수1
min(salary) AS 최소월급 -- 각 그룹마다 적용될 그룹함수2
FROM
employees
GROUP BY
department_id -- OK
-- 1 -- X
-- 부서번호 -- X
ORDER BY
1 ASC;
-- department_id ASC;
-- 부서번호 ASC;다중컬럼 GROUP BY - 입사 연도별로 그룹을 묶고 월급의 합을 나타낸다.
SELECT
to_char( hire_date , 'YYYY' ) AS 년, -- 다중그룹생성 표현식1
to_char( hire_date , 'MM') AS 월 , -- 다중그룹생성 표현식2
sum(salary) -- 각 그룹마다 적용될 그룹함수
FROM
employees
GROUP BY
to_char( hire_date , 'YYYY'), -- 다중그룹생성 표현식1 ->먼저 그룹핑 된 것이 나타내어진다.
to_char( hire_date , 'MM') -- 다중그룹생성 표현식2
ORDER BY
년 ASC;
--- 내가 생각하기에는 예제보다는 이렇게 조회하는게 더 유의미 해보인다.
SELECT
to_char( hire_date , 'YYYY' ) AS 년,
avg(salary)
FROM
employees
GROUP BY
to_char( hire_date , 'YYYY')
ORDER BY
년 ASC;
HAVING 조건식
GROUP BY 절에 의해 생성된 결과(그룹들) 중에서, 지정된 조건에
일치하는 데이터를 추출할 때 사용
(1) 가장 먼저, FROM 절이 실행되어 테이블이 선택되고,
(2) WHERE절에 지정된 검색조건과 일치하는 행들이 추출되고,
(3) 이렇게 추출된 행들은, GROUP BY에 의해 그룹핑 되고,
(4) HAVING절의 조건과 일치하는 그룹들이 추가로 추출된다!!!
이렇게, HAVING 절까지 실행되면, 테이블의 전체 행들이, 2번의
필터링(filtering)이 수행된다.
( WHERE절: 1차 필터링, HAVING절: 2차 필터링 )
각 부서별, 월급여 총계 구하기 -- 기본적인 HAVING사용
SELECT
department_id, sum(salary) -- 4th.
FROM
employees -- 1st.
GROUP BY
department_id -- 2nd.
HAVING
sum(salary) >= 90000 -- 3rd.
ORDER BY
1 ASC; -- 5th.각 부서별, 직원수 구하기 -- HAVING절에 다양한 조건
SELECT
department_id,
count(department_id)
FROM
employees
GROUP BY
department_id -- NULL 그룹도 생성됨을 기억할 것!!!
-- HAVING
-- count(salary) >= 6 -- 1st. filtering (for groups).
-- HAVING
-- salary >= 3000 -- XX: 각 그룹에 대해, 단순컬럼들만 사용불가
-- HAVING
-- department_id IN (10, 20) -- OK: GROUP BY절에 나열된 단순컬럼들은 사용가능
-- HAVING
-- department_id > 10 -- OK: GROUP BY절에 나열된 단순컬럼들은 사용가능
HAVING
department_id IS NULL -- OK: NULL 그룹도 있음을 기억할 것!!
ORDER BY
1 ASC;각 부서별, 월급여 총계 구하기 -FROM>WHERE>GROUP BY>HAVING>SELECT>ORDER BY순서에 맞춰 실행
SELECT
department_id,
sum(salary)
FROM
employees
WHERE
salary >= 3000 -- 1st. filtering (for records).
GROUP BY
department_id
HAVING
sum(salary) >= 90000 -- 2nd. filtering (for groups).
ORDER BY
1 ASC; 자바
반환타입과 매개변수에 따라 함수적 인터페이스명이 다르다
이미 선언된 함수적인터페이스 종류에 따라 람다식만 이용해서 구현해라
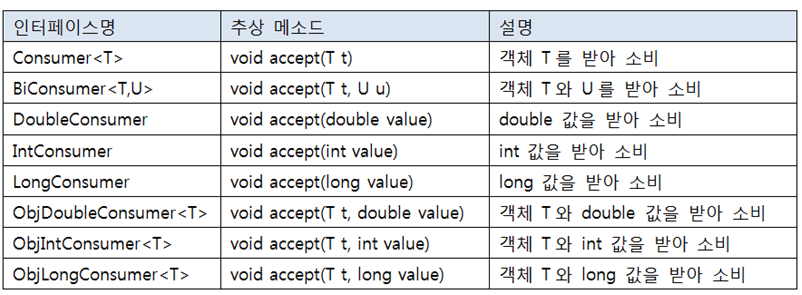
1)~Consumer
~Consumer : 매개값만 있고 반환타입이 없는 추상메서드를 가진 함수적 인터페이스
-매개변수를 받아서 알아서 사용하라/ 소비로직
메소드는 accept(~,~)
-----어떤 컨슈머가 어떤 매개변수를 얼만큼 받는지랑 메소드가 무엇인지 기억하라!-----
public class ConsumerExample {
public static void main(String[] args) {
Consumer<String> consumer = t -> System.out.println(t + "8");
consumer.accept("java");
BiConsumer<String, String> bigConsumer = (t, u) -> System.out.println(t + u);
bigConsumer.accept("Java", "8");
DoubleConsumer doubleConsumer = d -> System.out.println("Java" + d);
doubleConsumer.accept(8.0);
ObjIntConsumer<String> objIntConsumer = (t, i) -> System.out.println(t + i);
objIntConsumer.accept("Java", 8);
}
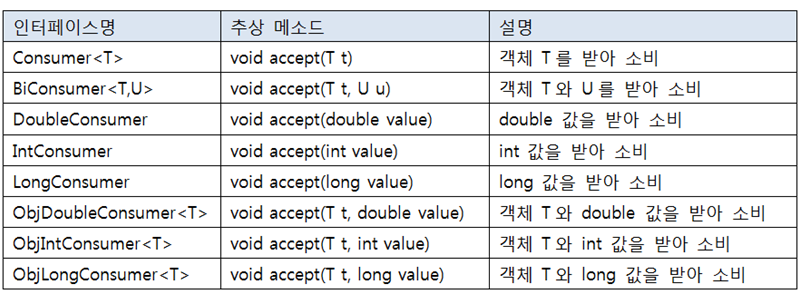
}2)~Supplier
~Supplier : 매개값은 없고 리턴값만 있는 추상메서드를 가진 함수적 인터페이스
메소드는 get~()
--------람다식으로 어떤 값을 반환해줄지 정하는 것이다!-------
public class SupplierExample {
public static void main(String[] args) {
IntSupplier intSupplier = () -> {
int num = (int) (Math.random() * 6) + 1;
return num;
};
int num = intSupplier.getAsInt();
System.out.println("눈의 수: " + num);
}
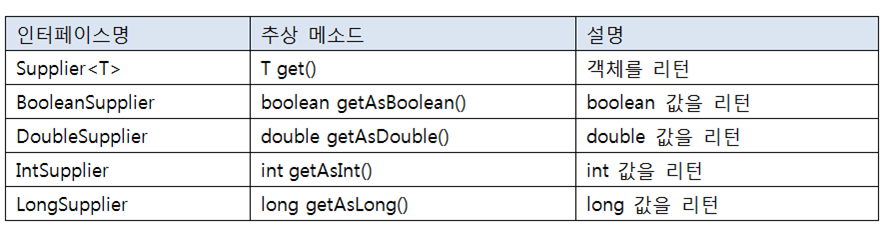
}3)~function
~function : 매개값과 리턴값이 있는 추상메서드 (타입을 바꾸어준다.)
메소드는 타입명 apply~(~,~)
(매개변수)L value = R value (람다식)
public class FunctionExample1 {
// 학생의 정보를 담는 리스트 / 객체 배열
private static List<Student> list = Arrays.asList(
new Student("홍길동", 90, 96),
new Student("신용권", 95, 93)
);
// 학생의 객체배열을 받아서 문자열로 보여준다.
public static void printString(Function<Student, String> function) {
for(Student student : list) {
System.out.print(function.apply(student) + " ");
}
System.out.println();
}
// 학생의 객체배열을 받아서 인트값으로 반환
public static void printInt(ToIntFunction<Student> function) {
for(Student student : list) {
System.out.print(function.applyAsInt(student) + " ");
}
System.out.println();
}
// 람다식으로 객체의 어떤 정보의 문자열 / 어떤 정보의 int로 보여줄것인지 정의해준다. (매개변수)L value = R value (람다식) 잊지마라
public static void main(String[] args) {
System.out.println("[학생 이름]");
printString( t -> t.getName() );
System.out.println("[영어 점수]");
printInt( t -> t.getEnglishScore() );
System.out.println("[수학 점수]");
printInt( t -> t.getMathScore() );
}
}
public class Student {
private String name;
private int englishScore;
private int mathScore;
public Student(String name, int englishScore, int mathScore) {
this.name = name;
this.englishScore = englishScore;
this.mathScore = mathScore;
}
public String getName() { return name; }
public int getEnglishScore() { return englishScore; }
public int getMathScore() { return mathScore; }
}Break point(중단점) : 프로그램의 실행을 "중지" 시켜라! 라는 의미의 표식
중단점 지정:이클립스 코드입력창 왼쪽 바에 더블클릭하면 동그라미 생김
Perspective(관점):
(1) 특정한 관점으로 만든, 뷰들의 모음
(2) 동일한 자바소스를, 소위 "다면적 또는 다차원" 적으로 보는 방법
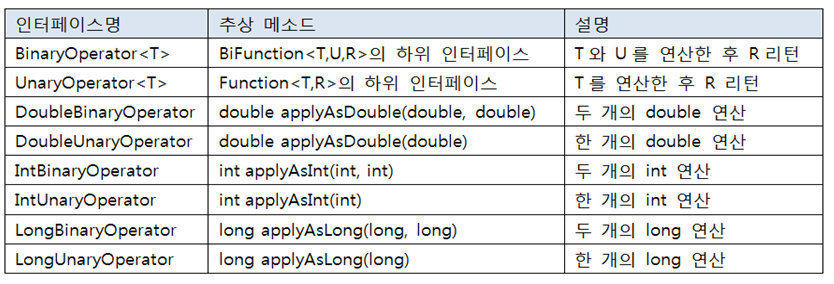
4)~Operator
~Operator: 매개값과 리턴값이 모두 있는 추상메서드를 가진 함수적 인터페이스
- 연산할때 사용하고 그 결과를 리턴할 때 사용
메소드는 타입명 apply~() 또는 ~Function<T,U,R>
public class OperatorExample {
private static int[] scores = { 92, 95, 87 };
public static int maxOrMin(IntBinaryOperator operator) {
int result = scores[0];
for(int score : scores) {
result = operator.applyAsInt(result, score);
}
return result;
}
public static void main(String[] args) {
//최대값 얻기
int max = maxOrMin(
(a, b) -> {
if(a>=b) return a;
else return b;
}
);
System.out.println("최대값: " + max);
//최소값 얻기
int min = maxOrMin(
(a, b) -> {
if(a<=b) return a;
else return b;
}
);
System.out.println("최소값: " + min);
}
}