DB
1. 단일(행) (반환)함수
1. 날짜 (처리)함수
-- ------------------------------------------------------
-- (0) 현 Oracle 서버의 날짜표기형식(DATE FORMAT) 설정확인
-- ------------------------------------------------------
-- Oracle NLS: National Language Support
-- 오라클의 년도표기 방식 (page 41 ~ 42 참고)
-- ------------------------------------------------------
DESC nls_session_parameters; -- 이 테이블을 통해 오라클 년도표기방식 확인 가능
-- 아래의 SQL 문장을 SQL*Developer 에서도 수행해 볼 것!
SELECT
*
FROM
nls_session_parameters; -- NLS_DATE_FORMAT 항목
SELECT
sysdate
FROM
dual;
-- ------------------------------------------------------
-- * To change Oracle's default date format
-- ------------------------------------------------------
-- Oracle SQL*Developer 에서도 수행해볼 것!
-- ------------------------------------------------------
ALTER SESSION SET NLS_DATE_FORMAT = 'RR/MM/DD';
SELECT
-- sysdate
current_date
FROM
dual;
ALTER SESSION SET NLS_DATE_FORMAT='YYYY/MM/DD HH24:MI:SS';
SELECT
-- sysdate 이거 대신 아래것을 써야한다. 다른나라의 cloud DB설치시 그 나라를 기준으로 시스템 시간을 제공한다.
current_date
FROM
dual;
-- ------------------------------------------------------
-- (1) 날짜 (처리)함수 - SYSDATE
-- ------------------------------------------------------
-- DB서버에 설정된 날짜를 반환
-- ------------------------------------------------------
SELECT
sysdate
FROM
dual;
-- * 날짜 연산 (page 43참고)
-- (1) 날짜 + 숫자: 날짜에 일수를 더하여 반환
-- (2) 날짜 - 숫자: 날짜에 일수를 빼고 반환
-- (3) 날짜 - 날짜: 두 날짜의 차이(일수) 반환
-- (4) 날짜 + 숫자/24: 날짜에 시간을 더한다
SELECT
sysdate AS 오늘,
sysdate + 1 AS 내일, -- 현재날짜 + 하루
sysdate - 1 AS 어제 -- 현재날짜 - 하루
FROM
dual;
SELECT
last_name,
hire_date,
sysdate - hire_date, -- 현재날짜 - 채용일자 = 기간(일수)
(sysdate - hire_date) / 365, -- 근속기간(일수) / 365 = 근속년수(소숫점포함)
trunc( (sysdate - hire_date) / 365 ) AS 근속년수
FROM
employees
ORDER BY
3 DESC;
-- ------------------------------------------------------
-- (2) 날짜 (처리)함수 - MONTH_BETWEEN
-- ------------------------------------------------------
-- 두 날짜 사이의 월수를 계산하여 반환
-- ------------------------------------------------------
SELECT
last_name,
hire_date,
months_between(sysdate, hire_date) AS "근속월수(소숫점포함)",
trunc(months_between(sysdate, hire_date)) AS "근속월수",
trunc(months_between(sysdate, hire_date) / 12) AS "근속년수"
FROM
employees
ORDER BY
3 DESC;
-- 날짜함수는 정말 중요 두 날짜를 연산한다는 것은 어떤 것인지 알아야함-- ------------------------------------------------------
-- (3) 날짜 (처리)함수 - ADD_MONTHS
-- ------------------------------------------------------
-- 특정 개월수를 더한 날짜를 계산하여 반환
-- 음수값을 지정하면 뺀 날짜를 반환
-- ------------------------------------------------------
SELECT
sysdate AS 오늘,
add_months(sysdate, (80-28)*12) AS 남은인생,
add_months(sysdate, 1) AS "1개월후 오늘", -- 현재날짜 + 1개월
add_months(sysdate,-1) AS "1개월전 오늘" -- 현재날짜 - 1개월
FROM
dual;
-- ------------------------------------------------------
-- (4) 날짜 (처리)함수 - NEXT_DAY
-- ------------------------------------------------------
-- 명시된 날짜로부터, 다음 요일에 대한 날짜 반환
-- 일요일(1), 월요일(2) ~ 토요일(7)
-- ------------------------------------------------------
-- NEXT_DAY(date1, {'string' | n})
-- ------------------------------------------------------
SELECT
last_name,
hire_date,
-- 최초로 돌아오는 금요일에 해당하는 날짜 출력
next_day(hire_date, 'FRI'),
-- next_day(hire_date, '금'), -- ORA-01846: not a valid day of the week
-- 최초로 돌아오는 금요일에 해당하는 날짜 출력
next_day(hire_date, 6)
FROM
employees
ORDER BY
3 desc;-- ------------------------------------------------------
-- (5) 날짜 (처리)함수 - LAST_DAY
-- ------------------------------------------------------
-- 지정된 월의 마지막 날짜 반환
-- 윤년 및 평년 모두 자동으로 계산
-- ------------------------------------------------------
-- LAST_DAY(date1)
-- ------------------------------------------------------
SELECT
last_name,
hire_date,
-- 채용일자가 속한 그 달의 마지막 날짜 반환
last_day(hire_date)
FROM
employees
ORDER BY
2 desc;
SELECT
last_name,
hire_date,
-- 입사일 기준, 5개월 후의 돌아오는 일요일의 날짜 반환
next_day(add_months(hire_date, 5), 'SUN')
-- ORA-01846: not a valid day of the week
-- next_day(add_months(hire_date, 5), '일')
FROM
employees
ORDER BY
2 desc;
-- ------------------------------------------------------
-- (6) 날짜 (처리)함수 - ROUND
-- ------------------------------------------------------
-- 날짜를 가장 가까운 년도 또는 월로 반올림하여 반환
-- ------------------------------------------------------
-- ROUND(date1, 'YEAR') : 지정된 날짜의 년도를 반올림(to YYYY/01/01)
-- ROUND(date1, 'MONTH'): 지정된 날짜의 월을 반올림(to YYYY/MM/01)
-- ------------------------------------------------------
SELECT
last_name,
hire_date,
-- 채용날짜의 년도를 반올림(to YYYY/01/01) ->년도가 오르거나 내리면 월과 일이 초기화
--해당 년도의 7월1일 기준으로 절반을 넘었는지 못넘었는지 /윤년일때는 6월 30일
round(hire_date,'YEAR'),
-- 채용날짜의 월을 반올림(to YYYY/MM/01) -> 월이 오르거나 내리면 일이 초기화
--해달 월의 절반을 넘었는지 못넘었는지
round(hire_date,'MONTH')
FROM
employees;
-- ------------------------------------------------------
-- (7) 날짜 (처리)함수 - TRUNC
-- ------------------------------------------------------
-- 날짜를 가장 가까운 년도 또는 월로 절삭하여 반환
-- ------------------------------------------------------
-- TRUNC(date1, 'YEAR') : 지정된 날짜의 년도를 절삭(to YYYY/01/01)
-- TRUNC(date1, 'MONTH'): 지정되 날짜의 월을 절삭(to YYYY/MM/01)
-- ------------------------------------------------------
SELECT
last_name,
hire_date,
-- 채용날짜의 년도를 가장 가까운 년도로 절삭(to YYYY/01/01)
trunc(hire_date, 'YEAR'),
-- 채용날짜의 년도를 가장 가까운 월로 절삭(to YYYY/MM/01)
trunc(hire_date, 'MONTH')
FROM
employees;
2. 변환 (처리)함수
-- ------------------------------------------------------
-- Oracle Type Conversions (Chapter03 - page 52 참고)
-- ------------------------------------------------------
-- 1. 자동 형변환 (묵시적 형변환) - Promotion
--
-- <NUMBER> <--> <CHARACTER> <--> <DATE>
--
-- 2. 강제 형변환 (명시적 형변환) - Casting
--
-- (1) <NUMBER> -- TO_CHAR --> <CHARACTER>
-- <CHARACTER> -- TO_NUMBER --> <NUMBER>
-- (2) <CHARACTER> -- TO_DATE --> <DATE>
-- <DATE> -- TO_CHAR --> <CHARACTER>
-- (3) <NUMBER> -- X --> <DATE>
-- <DATE> -- X --> <NUMBER>
-- -------------------------------------------------------- ------------------------------------------------------
-- (0) 자동 형변환 (Promotion) 예
-- ------------------------------------------------------
-- 문자타입(CHARACTER) --> 숫자타입(NUMBER)
-- ------------------------------------------------------
DESC employees;
SELECT
last_name,
salary
FROM
employees
WHERE
salary = '17000';
-- ------------------------------------------------------
-- (4) 변환 (처리)함수 - TO_CHAR
-- ------------------------------------------------------
-- 1. 날짜 데이터를 문자 데이터로 변환
-- 예: TO_CHAR( hire_date, 'YYYY' )
--
-- 2. 숫자 데이터를 문자 데이터로 변환
-- 예: TO_CHAR( 123456, '999,999' )
-- ------------------------------------------------------
-- ------------------------------------------------------
-- 1. 날짜 데이터를 문자 데이터로 변환
-- 예: TO_CHAR( hire_date, 'YYYY' )
-- ------------------------------------------------------
SELECT
to_char(sysdate, 'YYYY/MM/DD,(AM) DY HH24:MI:SS') AS sys날짜,
to_char(current_date, 'YYYY/MM/DD,(AM) DY HH24:MI:SS') AS 현재날짜
FROM
dual;
SELECT
last_name,
hire_date,
salary
FROM
employees
WHERE
to_char(hire_date, 'MM') = '09';
SELECT
to_char(sysdate, ' YYYY "년" MM "월" DD "일" ') 날짜 -- ""없으면 오류난다 넣어줘야 한다.
-- to_char(sysdate, ' YYYY "y" MM "m" DD "d" ') 날짜2
FROM
dual;-- ------------------------------------------------------
-- 2. 숫자 데이터를 문자 데이터로 변환
-- 예: TO_CHAR( 123456, '999,999' )
-- ------------------------------------------------------
-- 1) 숫자 출력형식
SELECT
to_char(1234, '99999') AS "99999", -- 9: 한 자리의 숫자 표현 ->1234
to_char(1234, '099999') AS "099999", -- 0: 앞부분을 0으로 표현 ->001234
to_char(1234, '$99999') AS "$99999", -- $: 달러 기호를 앞에 표현 -> $1234
to_char(1234, '99999.99') AS "99999.99", -- .: 소수점을 표시 -1234.00
to_char(1234, '99,999') AS "99,999", -- ,: 특정 위치에 , 표시 -> 1,234
to_char(1234, 'B9999.99') AS "B9999.99", -- B: 공백을 0으로 표현 ->1234.00
to_char(1234, 'B99999') AS "B99999", -- B: 공백을 0으로 표현 -> 1234 왜 안될까?
to_char(1234, 'L99999') AS "L99999" -- L: 지역 통화(Local currency) -> ₩1234
FROM
dual;
-- 2) 화폐 출력형식
SELECT
last_name,
salary,
to_char(salary, '$999,999') 달러,
to_char(salary, 'L999,999') 원화 --> 클라우드의 위치여부에 따라 해당 나라 기호로 나옴
FROM
employees;
-- ------------------------------------------------------
-- (4) 변환 (처리)함수 - TO_NUMBER
-- ------------------------------------------------------
-- 문자 데이터를 숫자 데이터로 변환
-- ------------------------------------------------------
SELECT
to_number('123') + 100, -- 강제형변환 (Casting) : *Recommended*
'456' + 100, -- 자동형변환 (Promotion) : Decommended
to_char(123) || '456', -- 강제형변환 (Casting) : *Recommended*
123 || '456' -- 자동형변환 (Promotion) : Decommended
FROM
dual;
-- ------------------------------------------------------
-- (4) 변환 (처리)함수 - TO_DATE
-- ------------------------------------------------------
-- '날짜형태'의 문자 데이터를 날짜 데이터로 변환
-- ------------------------------------------------------
-- 1) To change Oracle's default date format
-- * Oracle SQL*Developer 에서도 수행해볼 것!
ALTER SESSION SET NLS_DATE_FORMAT='RR/MM/DD'; -- 시스템의 날짜 출력 형식을 바꾸는 명령어
ALTER SESSION SET NLS_DATE_FORMAT='YYYY/MM/DD HH24:MI:SS';
SELECT
sysdate
FROM
dual;
-- 2) to_date 응용
SELECT
to_date('20170802181030', 'YYYYMMDDHH24MISS')
FROM
dual;
SELECT
sysdate,
sysdate - to_date('20170101', 'YYYYMMDD') AS 일수, --> 일수 반환
(sysdate - to_date('20170101', 'YYYYMMDD')) /365 AS 년수 -- 년수로 반환
FROM
dual;3.조건 (처리)함수
-- ------------------------------------------------------
-- (5) 조건 (처리)함수 - DECODE
-- ------------------------------------------------------
-- 조건이 반드시 일치하는 경우에 사용하는 함수
-- 즉, 동등비교연산자(=)가 사용가능한 경우에만 사용가능
-- ------------------------------------------------------
-- 문법) DECODE(
-- column,
-- 비교값1, 결과값1,
-- 비교값2, 결과값2,
-- ...
-- 비교값n, 결과값n,
-- 기본결과값
-- )
-- ------------------------------------------------------
SELECT
salary,
decode( -- if
salary, -- column
1000, salary * 0.1, -- if (salary = 1000):
2000, salary * 0.2, -- elif (salary = 2000):
3000, salary * 0.3, -- elif (salary = 3000):
salary*0.4 -- else:
)-- 일치하는 결과 값이 없으면 기본결과값 반환
FROM
employees;
-- 월급여액 별, 보너스 계산하기
SELECT
last_name,
salary,
decode(salary, 24000, salary * 0.3, 17000, salary * 0.2, salary) AS 보너스 -- 실무에서 가로로 쓰는 곳이 많음
--세로가 보기 편하지만 길어지는 단점이 있다.
-- decode(
-- salary,
-- 24000, salary * 0.3,
-- 17000, salary * 0.2,
-- salary
-- ) AS 보너스
FROM
employees
ORDER BY
2 desc;
-- 입사년도별, 사원들의 인원수 구하기
SELECT
count(*) AS "총인원수",
sum( decode( to_char(hire_date, 'YYYY'), 2001, 1, 0) ) AS "2001", -- sum 은 누적
sum( decode( to_char(hire_date, 'YYYY'), 2002, 1, 0) ) AS "2002",
sum( decode( to_char(hire_date, 'YYYY'), 2003, 1, 0) ) AS "2003",
sum( decode( to_char(hire_date, 'YYYY'), 2004, 1, 0) ) AS "2004",
sum( decode( to_char(hire_date, 'YYYY'), 2005, 1, 0) ) AS "2005",
sum( decode( to_char(hire_date, 'YYYY'), 2006, 1, 0) ) AS "2006",
sum( decode( to_char(hire_date, 'YYYY'), 2007, 1, 0) ) AS "2007",
sum( decode( to_char(hire_date, 'YYYY'), 2008, 1, 0) ) AS "2008"
FROM
employees;
-- ------------------------------------------------------
-- (6) 조건 (처리)함수 - CASE -->가독성이 높고 실용적이지만 관례때문에 decode로 씀
-- ------------------------------------------------------
-- 조건이 반드시 일치하지 않아도,
-- 범위 및 비교가 가능한 경우에 사용하는 함수
-- ------------------------------------------------------
-- 문법1) 조건이 반드시 일치하는 경우 (동등비교)
-- CASE column
-- WHEN 비교값1 THEN 결과값1
-- WHEN 비교값2 THEN 결과값2
-- ...
-- ELSE 결과값n
-- END
-- ------------------------------------------------------
SELECT
CASE salary
WHEN 1000 THEN salary * 0.1
WHEN 2000 THEN salary * 0.2
WHEN 3000 THEN salary * 0.3
ELSE salary * 0.4
END
FROM
employees;
-- ------------------------------------------------------
-- 문법2) 조건이 반드시 일치하지 않는 경우 (자유도가 조금 더 높다.)
-- CASE
-- WHEN 조건1 THEN 결과값1
-- WHEN 조건2 THEN 결과값2
-- ...
-- ELSE 결과값n
-- END
-- ------------------------------------------------------
SELECT
salary AS 봉급,
CASE
WHEN salary > 3000 THEN salary * 0.4
WHEN salary > 2000 THEN salary * 0.3
WHEN salary > 1000 THEN salary * 0.2
ELSE salary * 0.1
END AS 보너스
FROM
employees;
-- CASE 함수 (동등조건)
SELECT
last_name,
salary,
CASE salary
WHEN 24000 THEN salary * 0.3
WHEN 17000 THEN salary * 0.2
ELSE salary
END AS 보너스
FROM
employees
ORDER BY
2 desc;
-- CASE 함수 (부등조건)
SELECT
last_name,
salary,
CASE
WHEN salary >= 20000 THEN 1000
WHEN salary >= 15000 THEN 2000
WHEN salary >= 10000 THEN 3000
ELSE 4000
END AS 보너스
FROM
employees
ORDER BY
2 desc;
SELECT
last_name,
salary,
CASE
WHEN salary BETWEEN 20000 AND 25000 THEN '상'
WHEN salary BETWEEN 10000 AND 20001 THEN '중'
ELSE '하'
END AS 등급
FROM
employees
ORDER BY
2 desc;
SELECT
last_name,
salary,
CASE
WHEN salary IN (24000, 17000 , 14000) THEN '상'
WHEN salary IN (13500, 13000) THEN '중'
ELSE '하'
END AS 등급
FROM
employees
ORDER BY
2 desc;2. 그룹 (처리)함수
- 그룹 (처리)함수
- 그룹 (처리)함수는, 1) 여러 행 또는 2) 테이블 전체에 대해,
함수가 적용되어, 하나의 결과를 반환!
그룹 (처리)함수의 구분:
(1) SUM - 해당 열의 총합계를 구한다
(2) AVG - 해당 열의 평균을 구한다
(3) MAX - 해당 열의 총 행중에 최대값을 구한다
(3) MIN - 해당 열의 총 행중에 최소값을 구한다
(4) COUNT - 행의 개수를 카운트한다
1. SUM
-- ------------------------------------------------------
-- (1) 그룹 (처리)함수 - SUM
-- ------------------------------------------------------
-- 해당 열의 총합계를 구한다 (** NULL 값 제외하고 **)
-- ------------------------------------------------------
-- 문법) SUM( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- ------------------------------------------------------
SELECT
sum(DISTINCT salary), --중복은 제거하고 다 더한다.
sum(ALL salary), -- 중복값 허용 봉급을 다 더한다.
sum(salary) -- default
FROM
employees;2. AVG
-- ------------------------------------------------------
-- (2) 그룹 (처리)함수 - AVG
-- ------------------------------------------------------
-- 해당 열의 평균을 구한다 (** NULL 값 제외하고 **)
-- ------------------------------------------------------
-- 문법) AVG( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- ------------------------------------------------------
SELECT
sum(salary),
avg(DISTINCT salary), --중복제거하고 평균을 구함
avg(ALL salary), -- 중복 값 허용 하고 평균을 구한다 .
avg(salary) -- default
FROM
employees;
3. MAX,MIN
-- ------------------------------------------------------
-- (3) 그룹 (처리)함수 - (** NULL 값 제외하고 **)
-- MAX : 해당 열의 총 행중에 최대값을 구한다
-- MIN : 해당 열의 총 행중에 최소값을 구한다
-- ------------------------------------------------------
-- 문법) MAX( [ DISTINCT | ALL ] column )
-- MIN( [ DISTINCT | ALL ] column )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- ------------------------------------------------------
SELECT
max(DISTINCT salary),
max(salary),
min(DISTINCT salary), -- 어차피 최소값 최대값 구하는데 중복 적용 하는게 더 빠르고 좋다
min(salary)
FROM
employees;
SELECT
min( hire_date ),
max( hire_date)
FROM
employees;
4. COUNT
-- ------------------------------------------------------
-- (4) 그룹 (처리)함수 - COUNT >> 조심해야함 그룹핑 했을 때 그 수를 말함
-- ------------------------------------------------------
-- 행의 개수를 카운트한다(* 컬럼명 지정하는 경우, NULL값 제외 *)
-- ------------------------------------------------------
-- 문법) COUNT( { [[ DISTINCT | ALL ] column] | * } )
-- DISTINCT : excluding duplicated values.
-- ALL : including duplicated values.
-- (if abbreviated, default)
-- ------------------------------------------------------
SELECT
count(last_name),
count(commission_pct)
FROM
employees;
-- 직무의 개수를 구하기
SELECT
count(job_id), --107개
count(DISTINCT job_id) -- 19개
FROM
employees;
-- 해당 테이블의 전체 레코드 개수 구하기 (*주의필요*)
-- NULL값을 포함한 값을가지구 전체를 구하려하지마라! 무조건 기본키를 이용!
SELECT
count(*), -- Decommended ->
count(commission_pct), -- *Causion (removed all NULLs)
count(employee_id) -- *Recommended (Primary Key = Unique + Not NULL)
FROM
employees;
3. 단순컬럼과 그룹함수
- 단순컬럼과 그룹 (처리)함수 - 주의: 함께 사용불가!!!
a. 단순컬럼 : 그룹 함수가 적용되지 않음
b. 그룹함수 : 여러 행(그룹) 또는 테이블 전체에 대해 적용
하나의 값을 반환
셀렉트절에 오는 컬럼은 모든 형태가 같아야한다. 함수든가 단순이던가!!!!
SELECT
max(salary) -- return only 1 value.
FROM
employees;
-- 단순컬럼과 그룹함수 : 함께 사용불가!!!!
-- Error: ORA-00937: not a single-group group function
SELECT -- 셀렉트절에 오는 컬럼은 모든 형태가 같아야한다. 함수든가 단순이던가
last_name, -- return 107 values.
max(salary) -- return only 1 value.
FROM
employees;
자바
설명이 많다... 단순하게 핵심 키워드는
외부클래스, 내부클래스 ,클래스 this를 이용해 접근방법 알아보기, 클로져와 람다 캡쳐링 등
1.함수형 인터페이스 생성
package ex1;
@FunctionalInterface
public interface MyFunctionalInterface {
public abstract void method1();
} // end interface
2. 실행클래스 생성
package ex1;
public class UsingThisEx {
public static void main(String[] args) {
//1. 가장 바깥쪽 클래스의 인스턴스 ( = 객체) 생성
UsingThis outter = new UsingThis();
System.out.println("1. outter >> "+ outter);
// 2. 멤버 클래스의 인스턴스(= 객체) 생성
UsingThis.Inner inner = outter.new Inner(); // ?????
// 3. 멤버클래스에서 생성한 객체의 메소드 호출
inner.method();
} // main
} // end class
3. 중첩클래스 및 내부클래스 안에 람다식과 익명구현객체의 구현
public class UsingThis {
public int outterField = 10;
void instanceMethod() {
String name = "Yoseph"; // 지역변수
class LocalClass {;;} // 지역클래스 (Local class)
}// instanceMethod
//클래스 블록 내부에서 선언된 클래스를 "중첩클래스"라고 하며,
// 이 중첩클래스는 두가지 종류로 구분됩니다:
// (1) 멤버 클래스(Inner Class) : 바깥쪽 클래스의 클래스 블록내에서 선언된 클래스
// (2) 로컬 클래스(Local class) : 바깥쪽 메소드의 블록내에서 선언된 클래스
class Inner{
int innerField = 20 ;
// 모든 지역변수, 매개변수는 JVM Stack Area 영역에 보관 = > 다른 메모리 영역으로
// 옮겨서, "익명구현객체"의 생명주기보다 더 오래 살아남도록 하자!! => HOW??
// 바로 final 키워드를 람다식이 사용하는 지역변수(매개변수)들에만 붙이자!!
// ==> JVM Method Area(Clazz 객체가 보관되는) 상수풀(constant pool)에 보관
// ==> so, JVM의 생명주기와 같게 만들어 버린다!! ==> 이렇게 자바8부터,
// 클로져(Closure) 문제를 해결한다.
// 람다식에 사용된 변수는 컴파일러가 알아서 final을 붙혀준다 왜? 클로져 문제를 해결하기위해
void method() {
System.out.println("2. Inner >> "+this);
int age = 23; // 클로져를 야기시키는 변수
// age = 25; >> 런타임 오류가 난다. /즉, final이 자동으로 붙었기 때문에, 변경불가!
// 람다식이 생성한 "익명구현객체" 역시 Heap area 에 생성되는 객체임.
// 이 "익명구현객체"의 "생명주기": GC 될 때 파괴된다.
MyFuncionalInterface fi = () -> {
//Lambda Capturing - 람다 캡쳐링
//메소드 블록내에서 정의 된 지역변수의 사용 => "Closure" 문제를 발생시킨다!
//람다식에서의 생명주기와 다른 재료가 있을때 이 문제를 어떻게 할 것인가?
//clazz 객체에 넣는다! -> Static 영역에 넣어 해결
// System.out.println("age: " + age); // 23
// 멤버 클래스에 선언된 필드를 이름으로 직접 사용
// System.out.println("outterField:" + outterField);
// 가장 바깥쪽 클래스에 선언된 필드를 이름으로 직접사용
// System.out.println("innerField:" + innerField);
//// ----------------
// System.out.println("outterField:" + UsingThis.this.outterField + "\n");
// System.out.println("innerField:" + this.innerField + "\n");
System.out.println("3. lamda 내부의 this>>> "+this);
};// 람다식을 이용한 익명구현객체 생성
fi.method();
System.out.println("3. lamda>>> "+fi);
// -----------------
fi = new MyFuncionalInterface() {
@Override
public void method() {
System.out.println("4. Anonymous " + this);
}// method
}; // 익명구현객체
fi.method();
}// method
}// end class inner
} // end class : UsingThis
4. 람다식과 익명구현객체의 차이에 대한 고뇌의 과정
(1) 먼저 내부클래스에서 람다식과 익명구현객체를 통해 함수형 인터페이스의 참조변수로 객체를 생성하고 this로 이를 내부에서 주소값 참조해봤다.
- Anonymous / ex1.UsingThis$Inner$1@3f99bd52
- lamda 내부의 this / ex1.UsingThis$Inner@28a418fc
- Inner / ex1.UsingThis$Inner@28a418fc

아니 왜.. 참조변수가 아닌 내부클래스 주소를 반환하지??? 람다식 주소는 없지??...
(2) 람다식의 주소가 없어 이를 알아내는 과정을 겪게 되었다...
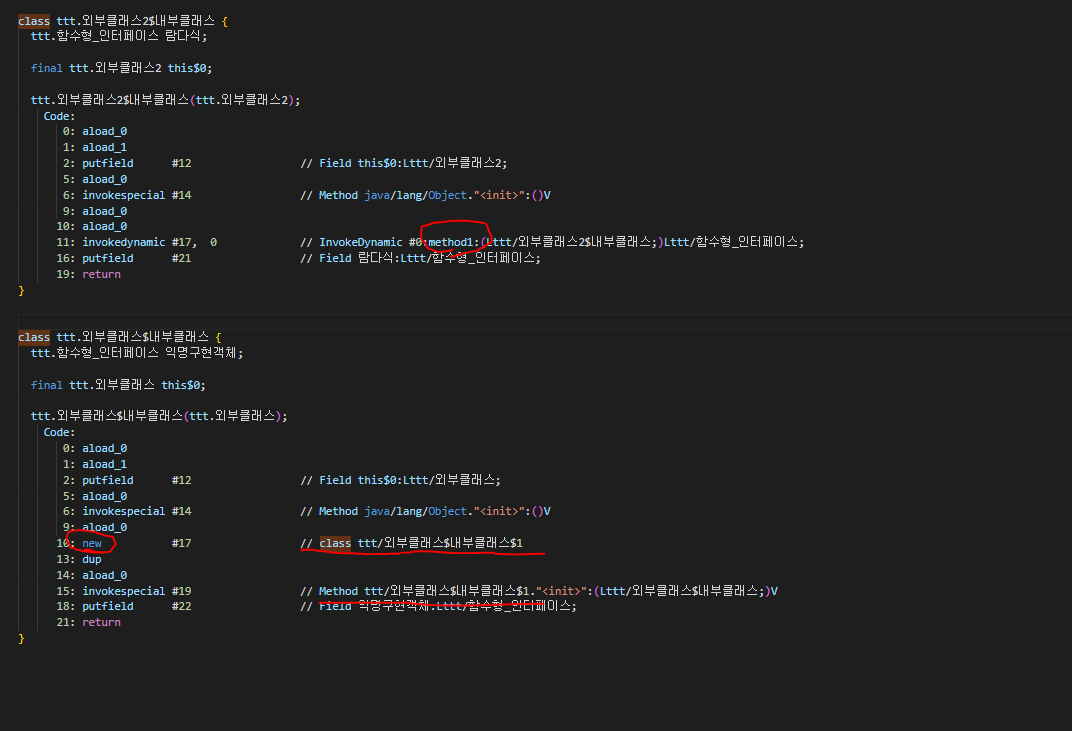
두괄식으로 결론부터는 바이트코드로 읽어보면 람다식으로는 .class 파일이 생성이 안되었고 익명구현객체는 new 연산자 시점부터 형성되었다.
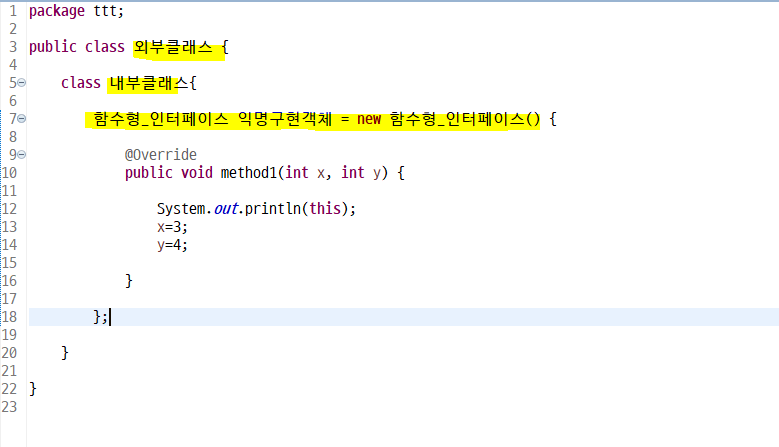
토종 한국인의 이해를 위한 익명구현객체 코드
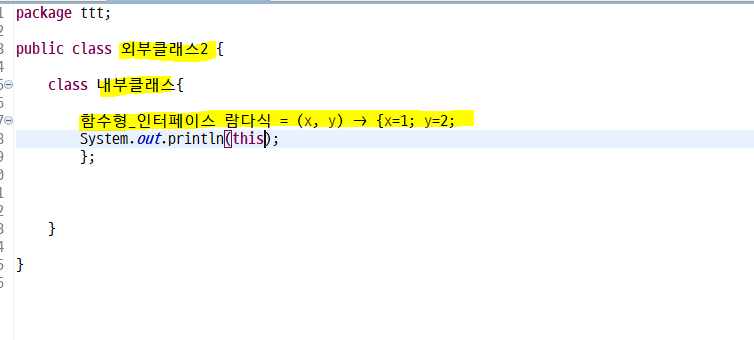
토한이위람코(요즘은 다 줄인다며?)

실제로 class 파일이 형성 되있는 익명구현객체와 달리 람다식은 따로 형성이 안되어 있었고
람다식이있는 내부클래스 용량 = 익명구현객체 클래스파일 + 내부클래스 용량 으로 비슷했다.

!!
참조변수에 데이터는 넣으므로 객체의 주소는 만들어주지만 클래스(파일)을 만들지 않아 this로 반환되는 주소는 없어 메소드의 기능만 한다. 그리고 이러한 람다식이 생겨난 이유는 한번 만들고 안쓰게 되는 클래스가 파일을 계속 만들어내면 어지러워서 그런 거라고 깨달았다.
이 과정을 깨닫기 위해 2시간을 쏟았다.. 수고한 내 자신

필기합격.. 이것으로 위안을 삼는다. 허헣헣
