빅데이터시스템설계
1.[빅데이터시스템설계] What is Big Data
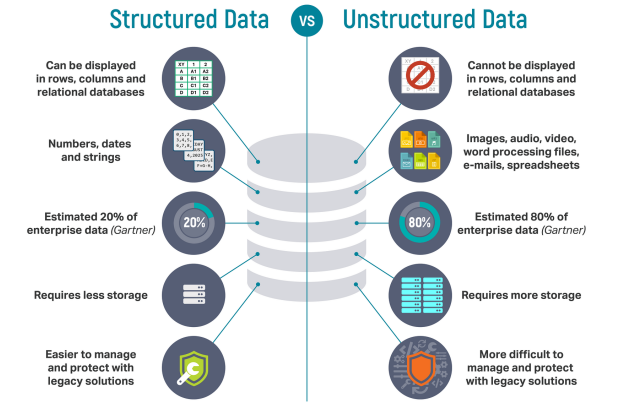
이 두 단어는 종종 혼동된다. 둘은 같은 단어가 아니다. 데이터는 관찰과 실험 등을 통해 얻은 현상의 문서화된 결과이다. 한마디로 단순 사실이다. 정보는 데이터를 가공, 분석하여 특정한 의미를 부여한 지식이다.예를 들면, 당일의 기온이 35도라 하자. 이 35도라는 것
2.[빅데이터시스템설계] Big Data Storage
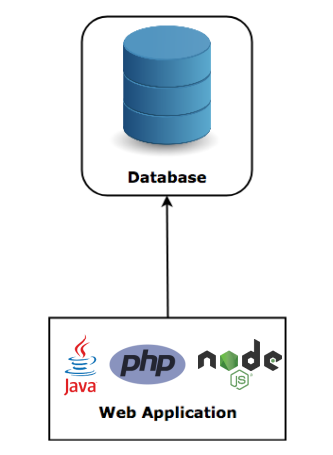
Scale-Up에 해당한다. 하나의 기기에 내장된 DB에 데이터를 저장하는 방식으로, RDB는 데이터의 관계를 테이블로 정의하기 때문에 RDB에 적합한 방식이다. 물론, 최근에는 RDB도 Decentralized로 구축하는 추세이다. Scale-Out에 해당한다. 여러
3.[빅데이터시스템설계] mongoDB 구성
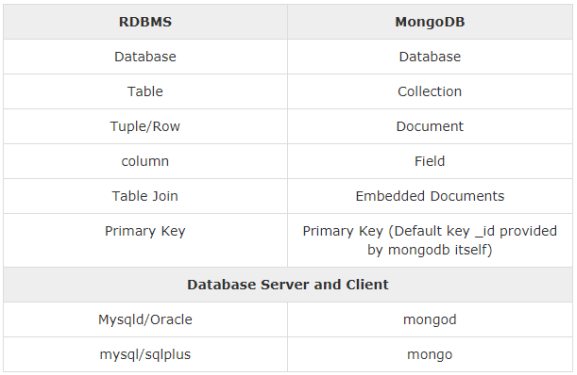
database : 말 그대로 데이터베이스 컨테이너이다. 내부에 컬렉션을 가진다. collection : 관련성 있는 도큐먼트들이 모인 집합이다. document : key-value들의 집합이다. 동적 스키마로, 정해진 구조가 없다. MongoDB는 정해진 조인이 없
4.[빅데이터시스템설계] 컬렉션 다루기
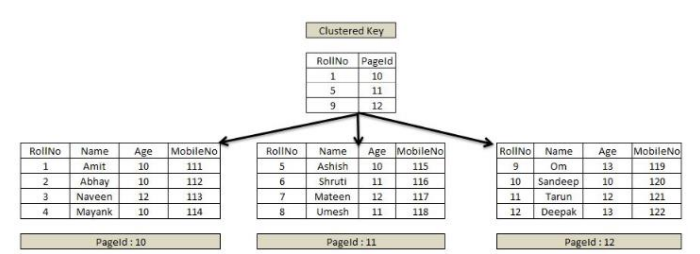
만약, 기존에 해당 이름에 해당하는 데이터베이스가 있으면 해당 데이터베이스 사용. 없으면 새로 생성. 새로 생성됐을 때, 비어있으니 보이진 않음. 데이터를 넣어야 보인다.비어있는 데이터베이스는 목록에 표시되지 않는다. 해당 데이터베이스로 이동해서 (use 명령어)도큐먼
5.[빅데이터시스템설계] 기본 쿼리
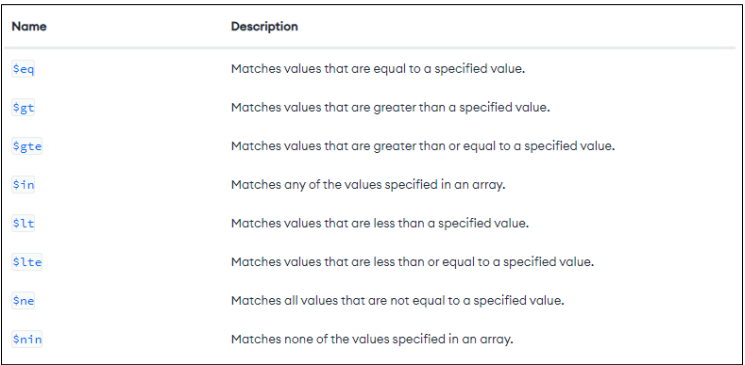
\*\*query : 조건 / projection : 필드 선택형식 필드명 : {비교\_연산자 : 값}$eq : ==$gt : > $gte : >=$lt : <$lte : <=$ne : !=$in : 해당 필드에 각 값들 중 하나라도 들어있는 document
6.[빅데이터시스템설계] 중급 쿼리

array 전체가 정확히 일치하는 document 조회array에 해당 값이 포함되는 document 조회\-> tags에 red가 포함된 4개 document 조회array의 인덱스로 접근하여 조회 array의 인덱스로 접근하여 조회 (여러개 조건으로)array에서
7.[빅데이터시스템설계] Aggregation

데이터를 집계하는데 사용되는 프레임워크이다. RDB의 select문의 여러 절들과 비슷하다. document들은 여러 단계의 파이프라인을 거쳐 집계된다. 파이프라인을 생성하는데 사용된다. stage의 순서를 어떻게 구성하느냐에 따라 성능에 영향을 많이 미친다.조건에 만
8.[빅데이터시스템설계] Indexing

특정 필드를 정렬하여 조회 성능을 높일 때 사용되는 기능이다. mongoDB에서는 B-Tree를 사용한다. 모든 리프 노드는 같은 레벨에 있다. 컬렉션 크기가 작을 때업데이트, 삽입이 빈번할 때 null값이 많은 필드한개의 필드로 인덱싱한다.기본적으로, 모든 컬렉션은