Aggregation 프레임워크
데이터를 집계하는데 사용되는 프레임워크이다.
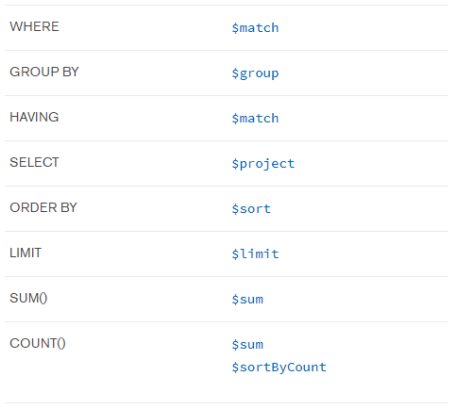
RDB의 select문의 여러 절들과 비슷하다.
document들은 여러 단계의 파이프라인을 거쳐 집계된다.

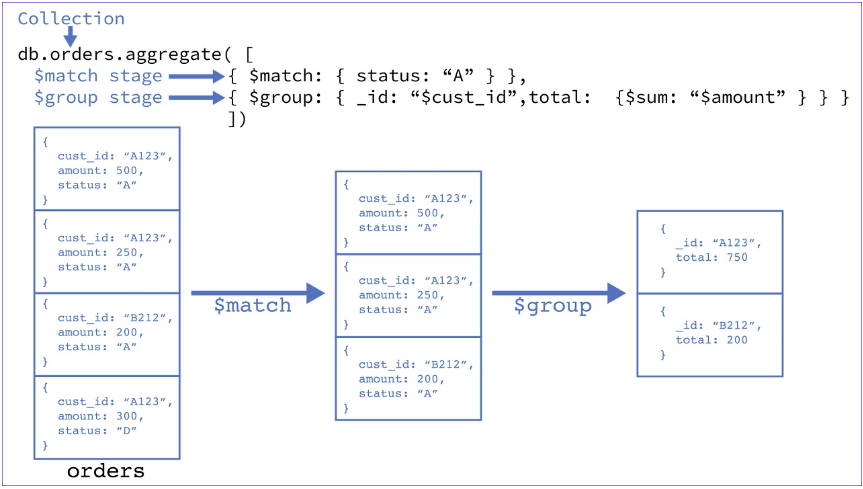
aggregate()
파이프라인을 생성하는데 사용된다.
stage의 순서를 어떻게 구성하느냐에 따라 성능에 영향을 많이 미친다.
pipeline stages
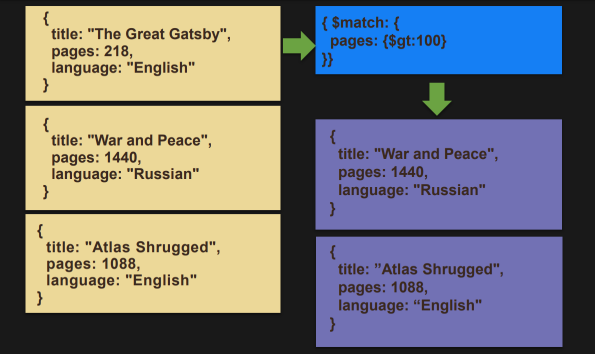
$match
- 조건에 만족하는 document를 필터링한다.
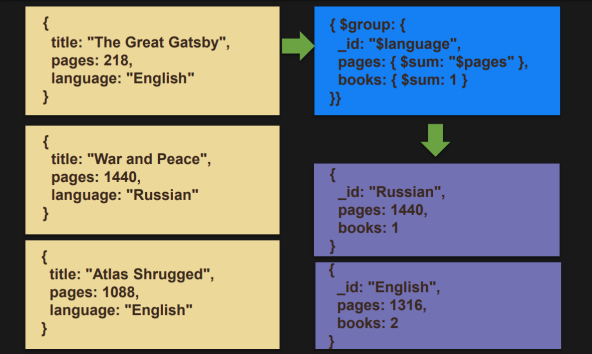
$group
- document들을 그룹핑하고 집계 연산을 수행할 수 있다. 이때, _id에 그룹핑을 할 기준 필드를 써줘야 한다.
사용 가능한 집계 연산으로는 $max, $min, $avg, $sum, $addToSet, $push, $first, $last가 있다.
language를 기준으로 그룹핑하고 pages에는 총 페이지 수를 더하여 저장하고, books는 한 document 당 1로 지정하여 총 document의 갯수를 세어 저장한다.
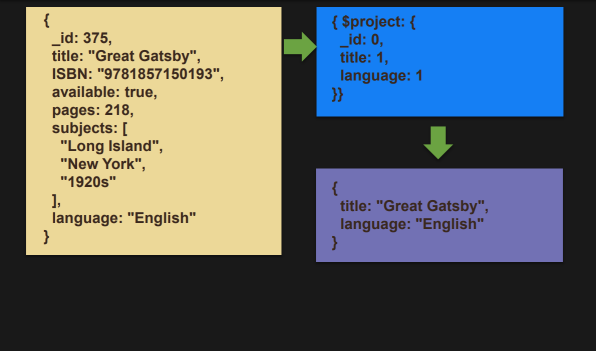
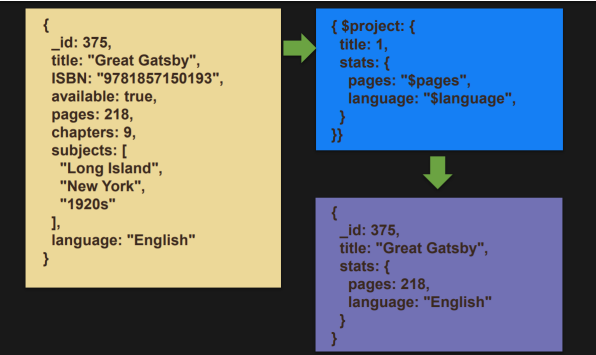
$project
- 필드 값을 다음 단계로 전달한다.
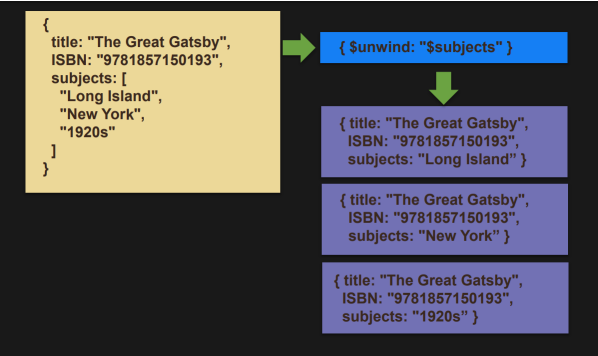
$unwind
- 배열 필드를 기준으로 document를 분리한다. 배열의 크기만큼 document가 생성된다.
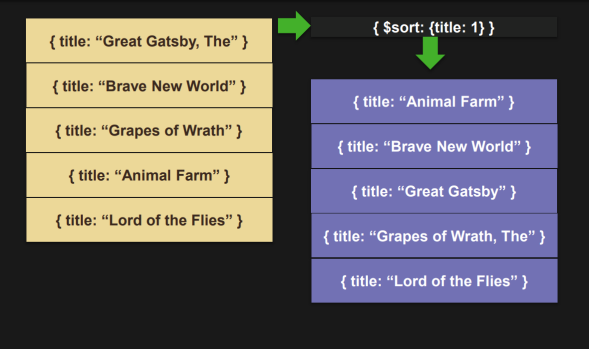
$sort
- 필드를 기준으로 document를 정렬한다. 1은 오름차순, -1은 내림차순이다.
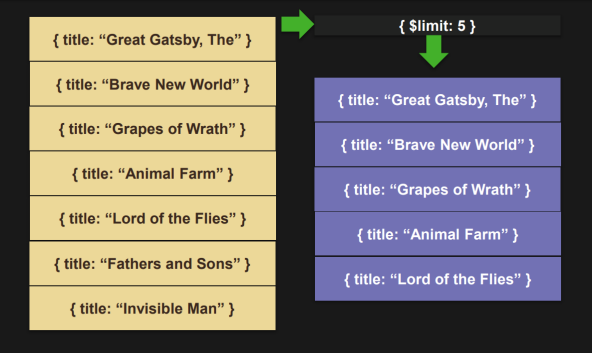
$limit
- document 갯수를 제한한다.
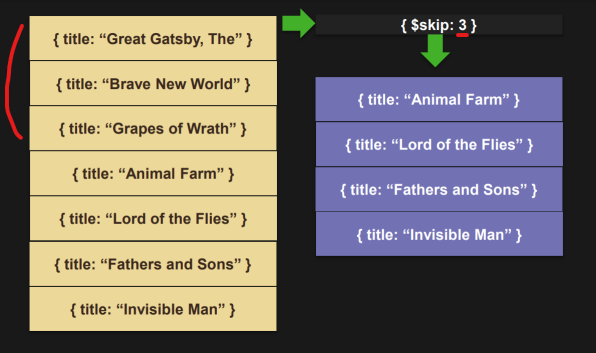
$skip
- 특정 갯수 만큼 document를 건너뛴다.

Record What I Learned