데이터베이스 생성
use 데이터베이스이름만약, 기존에 해당 이름에 해당하는 데이터베이스가 있으면 해당 데이터베이스 사용.
없으면 새로 생성. 새로 생성됐을 때, 비어있으니 보이진 않음. 데이터를 넣어야 보인다.
현재 사용중인 데이터베이스
db
현재 생성된 데이터베이스 확인
show dbs비어있는 데이터베이스는 목록에 표시되지 않는다.
데이터베이스 삭제
해당 데이터베이스로 이동해서 (use 명령어)
db.dropDatabase()
컬렉션 생성
- 도큐먼트 삽입 시 자동 생성
해당 데이터베이스로 이동해서 (use 명령어)db.컬렉션_이름.insert({key : "value"}**참고로 insert()는 레거시 함수로, 지금은 insertOne(), insertMany()를 쓴다.
2. 명시적으로 생성
해당 데이터베이스로 이동해서 (use 명령어)db.createCollection(“컬렉션_이름")
현재 데이터베이스에 생성된 모든 컬렉션 확인
show collections
collation
문자열이 비교되고 정렬되는 규칙을 정의한다. mongoDB 기본은 UTF-8이다.
capped collection
크기가 고정된 컬렉션
컬렉션 생성
db.createCollection("컬렉션_이름", {capped : true, size : 사이즈})컬렉션 크기가 size보다 커지면 오래된 순으로 삭제되고 새로운 document가 삽입된다.
size + max
db.createCollection("컬렉션_이름", {capped : true, size : 사이즈, max : 도큐먼트_수})최대 바이트 수를 size로 지정하고, 최대 도큐먼트 수를 max로 지정한다.
max 옵션은 document의 최대 갯수를 지정한다.
document 갯수가 max를 넘으면 오래된 순으로 삭제되고 새로운 document가 삽입된다.
만약, size가 10000이고 max가 1000이면, 컬렉션의 크기가 10000바이트를 초과하지 않으면서 최대 1000개의 document를 저장할 수 있다.
컬렉션이 capped 컬렉션인지 확인
db.컬렉션_이름.isCapped()
컬렉션을 capped 컬렉션으로 변경
db.runCommand({"convertToCapped" : "컬렉션_이름", size : 사이즈})
capped 컬렉션의 옵션 변경
db.runCommand({"collMod" : "컬렉션_이름", cappedSize : 사이즈}) db.runCommand({"collMod" : "컬렉션_이름", cappedMax : 사이즈})
컬렉션 삭제
db.컬렉션_이름.drop()
1개 document 삽입
db.컬렉션_이름.insertOne({"key1" : "value", "key2" : "value"})value에서는 ""를 무조건 써야한다.
여러개 document 삽입
db.컬렉션_이름.insertMany(
[
{"key1" : "value", "key2" : "value"},
{"key1" : "value", "key2" : "value"},
{"key1" : "value", "key2" : "value"}
]
)조회
db.컬렉션_이름.find().pretty()를 하면 들여쓰기를 해줘서 좀 더 가독성 있게 출력한다.
time series collection
시계열 데이터(시간의 흐름에 따른 변화를 분석하는 데이터)를 저장한다.
- 장점 :
- 시계열 데이터의 작업 복잡도가 낮아진다
- 쿼리 효율성이 높아진다
- 디스크 사용량이 적다
- 탐색을 위한 입출력이 적다
- WiredTiger(몽고디비 기본 스토리지 엔진)의 캐시 사용량이 증가한다
디스크보다 캐시에 데이터를 저장함으로써 속도가 빨라진다
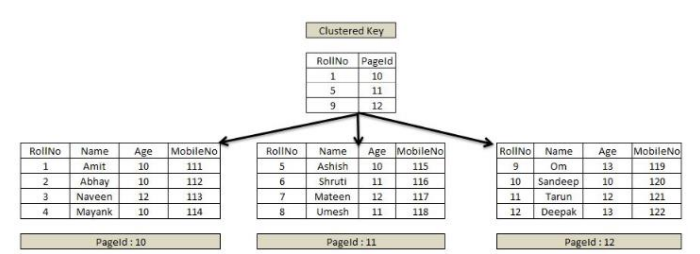
clustered collection
데이터의 논리적인 그룹을 형성하여 인덱스를 생성하고 물리적으로 분산하여 저장한다.
- 장점 :
- 삽입, 업데이트, 삭제 쿼리 성능이 향상된다
- 저장 공간이 절약된다
- 보조 TTL 인덱스가 불필요하다

Record What I Learned