Tree-based Methods
- 예측을 위해 여러 region으로 stratifying or sementing 하는 방법론
- 회귀와 분류 모두에서 사용 가능
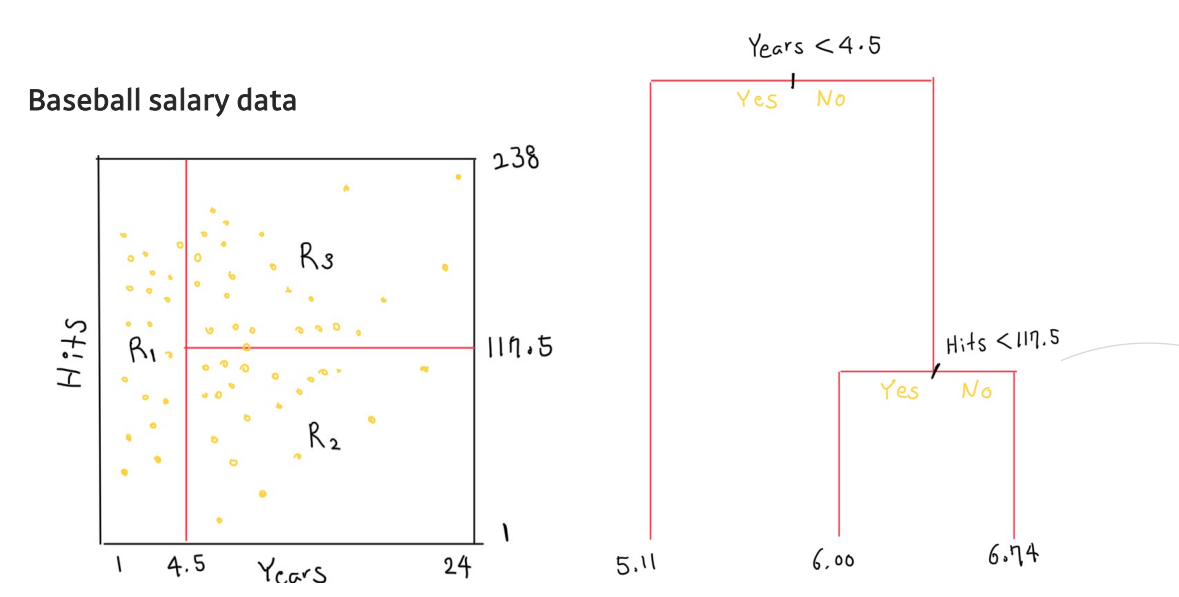
- 연차와 안타수를 통해서 구역을 나누고, 이를 트리형태로 나타냄
- 트리 함수를 쓰는 이유?
- 해석력 --> 구역을 복잡하게 만들지 않고 직사각형의 형태로 보기 쉽게 나타냄
용어 정리
- Terminal nodes : 결정 트리로 나뉘어진 Region, leaf라고도 표현 --> 트리의 마지막 부분들
- 결정 트리는 terminal node가 아래에 오도록 upside down 형식으로 그림
- Internal nodes : predictor space가 나뉘어지는 부분 --> 쪼개지는 부분들
회귀 결정 트리
- 결정 트리는 predictor space를 보통 사각형 또는 box 형태로 나눔
- 이는 예측 모델의 간단성과 해석의 용이함을 위한 것
회귀 결정 트리는 RSS(residual sum of squares)를 최소화하는 boxes 를 찾는 것이 목적
--> RSS : MSE와 비슷하지만 평균을 내는 것이 아닌 다 더해주는 형태의 Loss Function - J개 만큼 Region으로 결정트리 형성
- Region 안에 있는 데이터들의 평균과 데이터의 제곱의 합을 통해서 Loss 계산
Greedy Algorithm
- Greedy tree-building
- (전체 input space)를 시작으로 다음의 과정을 반복함
- RSS를 최대로 감소시키는 를 찾음
- RSS를 최대로 감소시키는 를 찾음
- Splittingpoint s를 기준으로 region을 새롭게 정의
Greedy tree-building
- Greedy 방식은 일정 기준(각 region에 5개 이하의 샘플) 만족 시 멈춤
- 모든 가능한 region을 고려하는 것은 계산상 불가능함
- 따라서 Top-down, greedy 방법론(recursive binary splitting)을 사용함
- root에서부터 leaves까지 트리를 생성하기 때문에 top-down이라고 불림
- Greedy라 불리는 이유는, 이전이나 이후 상황이 아닌 딱 현재 상황에서의 best split을 하기 때문
- Terminal node의 수가 많아질수록
- RSS 값이 0으로 수렴
- Over-fitting 이슈 발생(Bias )
- 모델 학습을 위한 computation cost 증가
Over-fitting 방지 idea
- 교차검증(cross validation)을 통해 optimal subtree 찾음
--> 하지만 경우의 수가 너무 많기 때문에, over-fitting을 완벽히 막기 힘듦 - RSS 값이 일정 thresshold 만큼 떨어지지 않으면 tree 성장을 멈춤
--> 다음 성장에서 큰 RSS drop이 일어날 수도 있음
가지치기(pruning) 손실 함수
- 기존의 손실 함수 RSS에 가지치기를 위한 정규화 항을 추가함
- --> 항을 추가하여 정규화
- |T|: 터미널 노드의 개수
- 라면 null 트리 생성(한개의 leaf만으로 구성된 트리)
- 라면, full 트리 생성
- 하이퍼 파라미터는 교차 검증을 통해 구할 수 있음
분류 결정 트리
- 회귀 결정 트리와 매우 유사하지만, RSS의 손실 함수 사용 불가
- 평균값이 아닌 Majority vote를 통해 예측(각 region의 클래스를 뽑음) -->투표와 같음
- 새로운 분류 손실 함수가 필요
classification Loss Function
1. Misclassification rate(classification error rate)
- Region 안의 샘플 중에서 most common class에 포함된 않는 샘플의 수를 계산
- 두 가지 형태의 손실 함수로 표현 가능
- minimize --> 다른 클래스의 개수가 적어지도록 최적화
- minimize
: m-th region에서 k-th class에 해당하는 학습데이터의 비율
- minimize
- 하지만 트리 성장에 있어서 충분히 민감하지 못한 단점
--> SVM의 관점에서 봤을때 둘을 분류를 제대로 하더라도 결정 경계선의 형태를 중요시 여기지 않음
--> Loss 함수에 따라서 미분 변화율이 달라짐
2. Gini index
- K개 클래스의 분산에 대한 관측치
- minimize
: m-th region에서 k-th class에 해당하는 학습데이터의 비율
: 전체 데이터 개수에 대한 region 에 있는 샘플 수의 비율 - 이 모두 0 아니면 1에 수렴할 수록 좋아짐 --> most common class에 대해서는 : 1, else : 0
- Gini index 값이 작으면 single 클래스가 node를 장악한 상황이므로, node purity에 대한 관측치로도 해석 가능
3. Cross-entropy
- Gini index와 매우 유사한 손실 함수클래스의 분산에 대한 관측치
- minimize
(이전 크로스 엔트로피에서는 원 핫 인코딩 된 와 확률 로 나타냈듯)
는 비율이고 확률이라고 볼 수 있으므로 지니 인덱스와 유사한 손실함수
Decision Tree의 장단점
- Pros:
- 모델에 대한 해석과 설명이 쉬움
- 인간의 의사 결정과 매우 비슷한 형태의 모델임
- 시각적으로 보여주기 편리하며, 비전문가도 쉽게 이해 가능
- Cons:
- 다른 회귀, 분류 모델에 비해 예측 성능이 일반적으로 떨어짐
- 하지만 이는 많은 수의 결정 트리의 결과를 종합하는 Ensemble 학습( e.g. Bagging, Boosting)으로 보완 가능함

Sometimes You gotta run before you can walk.