SVM (Support Vector Machine)
Hyperplane
- p차원에서 hyperplane은 p-1차원에서의 평평한 어핀 공간(2차원-> 직선, 3차원 -> 면)
- 의 normal vector는 hyperplane과 orthogonal(수직) 방향을 의미


- hyperplane 위의 점 :
- 점과 선 사이의 거리 :
- 한쪽 : , 다른쪽 :
Separating Hyperplane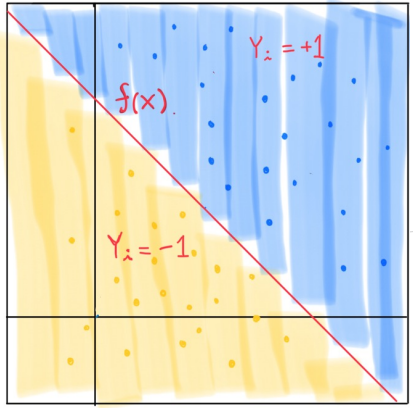
- 인 점들과 인 점들을 분류
- for all i
- 은 separating hyperplane을 의미
Maximal Margin Classifier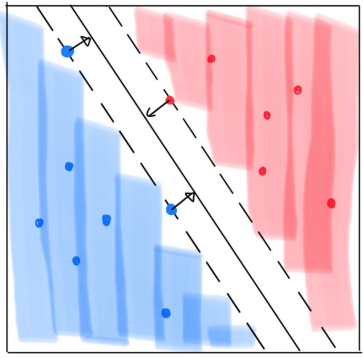
-
모든 Separating hyperplane중에서, 이진 클래스 사이의 gap 또는 margin을 최대로 만들어주는 것을 찾음
-
결정 경계에 영향을 미치는 샘플들을 서포트 벡터(support vector)라고 부름
-
max M(Margine)
-
최적화를 통해서 최대 마진을 가지는 결정 경계 찾기
-
모든 데이터에 대한 각각의 마진은 결정된 max M보다 크거나 같다.
-
subject to for all
-
subject to
-
-
를 이용해서 크기를 control 가능하므로 의 크기 중요성이 떨어짐
-
로 표현 가능
-
subject to
-
= 로 표현 가능
-
--> 수학적으로 계산(미분)의 편리성을 위해서 제곱후 2로 나눠준 형태로 변형
-
=
라그랑주 승수법(lagrange multiplier method)
- 제약식이 있는 최적화 문제를 라그랑주 승수 항을 추가해, 제약이 없는 문제로 바꾸는 방법
- 원초 문제(primal problem)
- , subject to
- 라그랑주 승수 벡터 와 를 도입해 라그랑주 함수 을 만듦
- 를 라그랑지 듀얼 함수라고 부름
- 편미분의 결과가 0이 되는 지점에서 최소값을 가짐
- 로 대입 및 전개
- --> u와 v만을 이용하여 식을 표현
Duality gap
- 를 최대화하는 것은 과 가까워지는 것
- 둘 사이의 gap을 통해서 표현
- 둘 사이의 gap이 존재하면 weak dual, 존재하지 않으면 strong dual()
라그랑주 듀얼 문제(lagrange dual problem)
- 최소화 문제를 최대화 문제로 바꾸어 풂
- subject to
Slater's condition
- subject to
- ------------
- 조건 1: Primal problem이 convex
- 조건 2: There exists at least one strictly feasible
- 조건 1과 2를 만족하면 strong duality를 만족함
KKT Condition
- strong duality의 문제(Slater's condition 만족)에서는 다음의 명제를 만족함
- are primal and dual solutions
and satisfy the KKT conditions - Stationarity 조건:
0 ==>
- Stationarity 조건:
- Complementary slackness 조건:
for all i
ll
- Complementary slackness 조건:
Maximal Margin Classifier
- subject to
for all i =1,..., N
Dual form
- =
subject to - By Stationary condition (in KKT condition),
, - 따라서, ,
subject to for i = 1...N- KKT 조건의 Complementary slackness condition에 의하면
둘 중 하나는 반드시 0 --> --> - 결정 경계에 영향을 미치는 관측치들은 오직 support vector뿐
- 그래서 서포트 벡터 머신(support vector machine)이라 부름
- 값을 옵티마이즈 하려고 하는데 support 벡터가 아닐때는 가 0이 되어 영향 X
- Maximal Margin Classifier를 해결할때, Dual form으로 를 구하고, 2차계획법으로 w와 b를 구해 경계선 구함
Soft Margin Machine
- 선형 경계로는 완벽히 나눌 수 없는 경우 또는 noisy샘플 때문에 비효율적인 경계가 형성되는 경우
- Slack variable 를 도입해 해결
subject to
for all i = 1,...,N
subject to for all i =1, ..., N
By stationary condition(in KKT condition),- , ,
- 따라서,
Hyperparameter C in SVM
- C의 값이 커지면
- 의 영향이 커져 0으로 보내며, 마진의 폭이 줄어듬
- Support vector 수가 줄어들어, 적은 샘플로 결정 경계를 찾음 --> 오버피팅 이슈 가능성
- Bias , Variance
- C의 값이 작아지면
- 의 영향이 작아져 마진의 폭이 커짐
- Support vector 수가 늘어나, 많은 샘플로 결정 경계를 찾음 --> 언더피팅 이슈 가능성
- Bias , Variance
Classification for SVM
- 지금까지 주어진 데이터로 결정 경계 hyperplane을 찾는 과정
- --> 서포트 벡터일때만 가 0이 아니므로 계산량
- 예측값이 0보다 크면 로 0보다 작으면 로 분류
- Support vector만 사용되기 때문에 연산량이 많지 않음
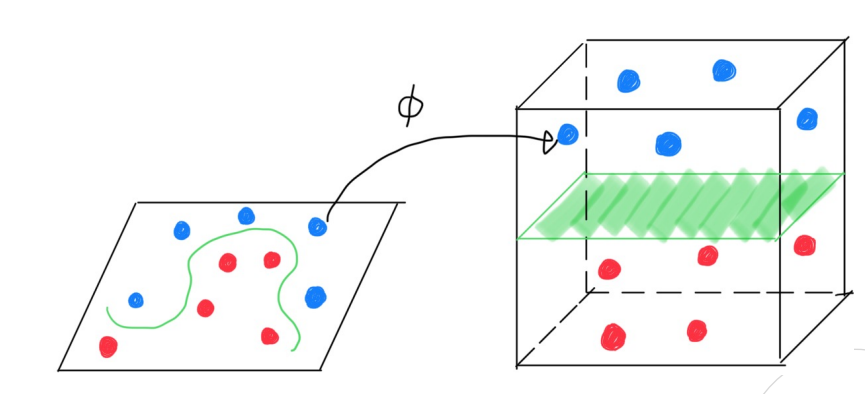
Nonlinear SVM
- Mapping function
- 비선형 구조의 데이터를 높은 차원으로 이동시켜 그 공간에서 분류하고자 함
- Input space에 존재하는 데이터를 feature space로 옮겨주는 mappin
- Mercer's Theorem
- 의 경우 항상 0이상의 값을 지님
- (대칭 행렬 조건)
커널 함수는 두 조건을 만족시켜야함
- (대칭 행렬 조건)
Kernel trick
- 조건을 만족하는 임의의 함수를 모두 커널 함수로 사용
- Linear :
- Polynomial :
- Gaussian :
- Radial :
SVM with kernel trick
-
--> -
--> -
분류시 커널 함수가 사용되므로, mapping function에 대한 정의가 필요 없음
Multiclass SVM
SVM for multiclass
- OVA(One versus All)
- K개의 2-Class SVM을 학습하며 각자의 class와 나머지 클래스로 나눔
- 의 값이 가장 큰 클래스로 분류
- OVO(One versus One):
개의 pairwise classifier(를 학습
Pairwise competition을 가장 많이 이긴 클래스로 분류
SVM vs Logistic Regression
- 클래스가 거의 separable하면, SVM > LR
아닐 경우, LR(with ridge penalty) == SVM --> LR과 L2 정규화 손실함수를 같이 썼을때 성능 같다. - 확률값을 측정하고 싶으면, LR을 사용
- Nonlinear boundary에는, kernel SVM이 계산적인 면에서 더 좋음

Sometimes You gotta run before you can walk.