(2021)Generative Adversarial Registration for Improved Conditional Deformable Templates
Paper Review
0. Abstract
Deformable templates는 medical image registration, segmentation, population analysis 등에 중요하게 사용된다. 현재 사용되는 전통적인 방법과, deep learning 기반의 template construction은 일반적인 objectives를 사용하며 주로 blurry하고 해부학 관점에서 부정확하다.
본 논문에서는 학습 시, adversarial game 방법을 적용하여 좀 더 사실적인 template를 생성하였고 condition을 주어 확률 분포를 학습함으로 그에 따른 맞춤 template를 생성하도록 하였다.
1. Introduction
Population study 관점에서 이상적인 template은 특정한 sub-popluation에 biased되지 않은 template을 말한다. 하지만 단 하나의 template은 다양한 population의 structural을 모두 담을 수는 없다.
본 논문에서는 이를 고려해 continuous, categorical attributes에 따른 conditional template estimation을 제안하였다. 핵심 insight는 templatereal image 방향으로 registration accuracy를 높여, 생성된 template의 distribution을 real image의 distribution에 transform 했을 때 무엇이 real image의 distribution인지 구분하지 못하도록 학습이 되는 것이다.
Adversarial objectives는 hight-frequency detail을 살려주는 역할을 한다. 하지만 3D volume으로 GAN을 학습하는 것을 매우 어려운데, 이를 해결하기 위해 적절한 extensive optimization, architectural schemes, augmentation strategies, conditioning mechanisms를 적용하였다.
본 논문의 주요한 contribution은 다음과 같다.
- Deformable template generation, registration에 generative adversarial approch를 처음으로 적용하였다.
- 다양한 challening datasets에 conditional templates를 생성해 보았다.
- Centrality, interpretability 측면에서 template construction methodologyies의 엄청난 발전을 이루었다.
2. Related work
최근에 전통적인 방식과 달리 spervised 학습 방식의 deformable image registration이 제안 되었으며 동시에 unsupervised 학습 방식도 제안 되었다. 이를 통해 flexibility와 inference performance 측면에서 많은 향상이 있었다.
앞서 generative adversarial registration을 적용한 연구들도 있었지만 본 논문의 접근 법은 registration 뿐만 아니라 template에도 초점을 두고 있다는 점에서 다르다.
전통적인 template estimation 방법은 aligne된 images의 평균을 구한 후 post-processing과 sharpening을 적용하기 때문에 존재할 수 없는 어색한 구조를 생성할 수 있고 다양한 populations를 반영하지 못한다는 단점이 있다.
3. Methodology
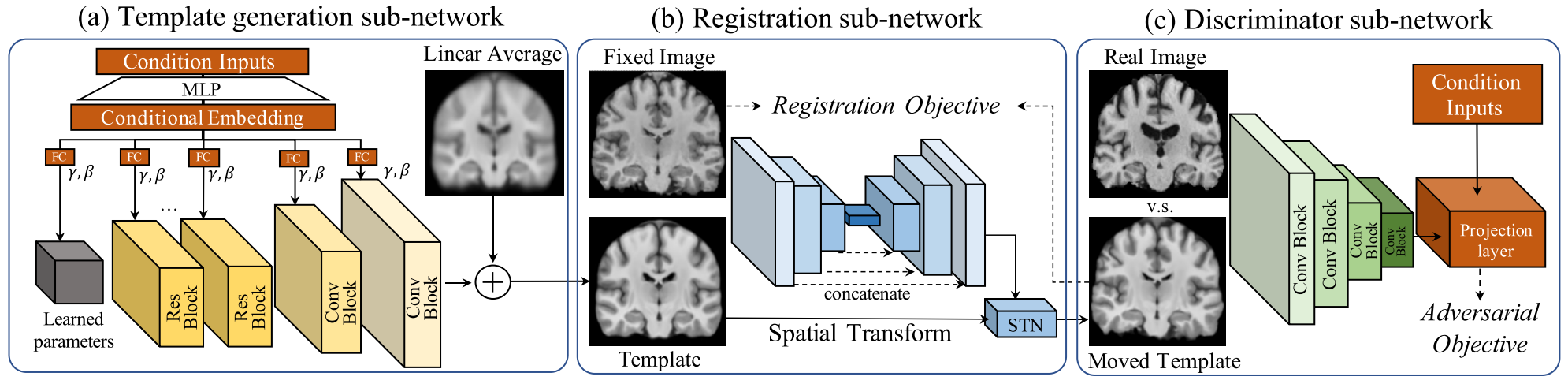
위 그림에서 generator (a), (b)는 conditional template를 synthesize하고 fixed image에 deform하는 network이다. Deform된 template는 discriminator (c)로 전달되어 판단된다.
이 framework는 end-to-end 방식으로 학습이 되며 registration accuracy와 template realism을 높이기 위해 regularized regiration, adversarial cost를 적용하였다.
3.1 Template Generation Sub-netowrk
Conditional 또는 unconditional training인지에 따라 architecture가 다르다.
Unconditional training인 경우, template resolution의 절반인 randomly-initialized parameter array를 convolutional decoder에 입력으로 넣어 output을 얻은 후에 linear average image에 더해 unconditional template를 얻는다.
Conditional training인 경우 주어진 condition vector 와 th layer와 th channle에 해당하는 feature map 를 다음과 같이 조합한다.
, 는 로 부터 학습된 scale, shift parameters이며 4개의 MLP를 지나 conditional embedding 후에 생성된다.
이 구조의 이점은 첫 번째로 모든 layer에 condition을 줌으로 다양한 datasets에 잘 맞고 좀 더 정확한 templates를 생성할 수 있게 된다.
두 번째 이점은 MLP를 거쳐 channel-wise scalars가 생성되어 process가 진행되기 때문에 의 dimension에 영향을 적게 받아 학습이 수월하다.
3.2 Registration Sub-network
본 논문에서는 Discriminator로 local patch기반의 PatchGAN을 사용하였다. 주어진 neroimage volume이 이라면 discriminator는 의 receptive field를 갖는다.
Conditional templates의 경우 discriminator는 주어진 continuous, categorical covariates에 따른 real images, synthesized images를 구분하도록 학습이 된다. discriminator를 conditioning하기 위해서, 본 논문에서는 최신 GAN 논문들에서 주로 사용하는 projection 방법을 사용하였다. 식은 아래와 같다.
는 input, 는 condition, 는 network의 output이다. 는 학습된 parameter이며 는 의 embedding matrix이다. 는 의 scalar function이다.
그러나 위 식은 categorical, continuous attributes를 동시에 적용할 수 없다는 문제가 있어 continuous, categorical attributes가 conditional independence하다는 가정 아래에 다음과 같이 식을 구성하였다.
, subscripts는 categorical, continuous attributes를 의미한다.
3.3 Loss Function
Generator는 image matching term, smoothness와 centrality term, adversarial term으로 구성된 objective를 사용한다.
Matching을 위해서는 squared localized normalized cross-correlation (LNCC) objective를 사용한다.
Deformation regularization을 위해서는 다음 식을 따른다.
는 voxels, 는 spatial displacement, , 를 나타낸다.
Adversarial term은 generator와 discriminator를 학습하는데 사용이 되며 least-squares GAN의 objective를 따른다.
전체 loss는 아래와 같이 요약된다.
이
,
3.4 GAN Stabilization
GAN을 안정적으로 학습하기 위해선 더 작은 image resolution, 더 큰 batch size, 더 큰 network, 더 많은 sample이 필요하다. 하지만 neroimage는 큰 volume을 갖고 있으며 GPU memory가 제한되어 batch size를 크게 설정할 수 없으며 작은 사이즈의 network를 사용할 수 밖에 없다. 게다가 학습을 위한 sample은 medical imaging 연구들을 보면 대게 몇 백개의 scans만 사용을 하고 있는 것이 현실이다.
본 논문에서는 GAN을 안정적으로 학습하기 위해 spectral normalization을 모든 layer에 적용한 1-Lipschitz constraint을 강제함으로 안정적인 학습을 하고 generator로의 gradient feedback이 수월하게 되도록 하였다. 또한 gradient penalty를 discriminator에 주어 안정적인 학습을 도왔다. 마지막으로 제한된 데이터에서 discriminator는 overfitting이 발생하기 쉬운데 real images와 synthesized images에 differentiable augmentation을 discriminator 학습 시에 적용하여 이를 해결하였다.
4. Experiments
4.1 Datasets
1) dHCP
29 ~ 45주 신생아의 neuroimage dataset이다. 558 scans의 T2w MR images로 구성되어 있으며 주어진 affine template에 align되어 있다. Training, validataion, testing은 458, 15, 85 scans로 나뉜다.
2) Predict-HD
Huntington’s disease (HD)가 있는 subjects와 건강한 대조군으로 구성된 dataset이다. HD는 단계적으로 진행되는 신경 퇴행성 질환으로 운동 조절, 인지 기능을 퇴화 시킨다.
본 논문에서는 나이와 HD의 존재 여부에 따라 나눠서 template를 만들었다.
388명의 subjects의 1117 scans T1w MR로 구성되어 있으며 MNI에 affined 되었다.
Segmentation map은 semi-automatically하게 Neuromorphometrics template로 부터 얻었다. Training, validataion, testing은 897, 30, 190 scans로 나뉜다.
3) FFHQ-Aging
70,000개의 실제 face images를 포함하는 dataset이며 나이, 성별 및 안경 착용 여부에 해당하는 label을 제공한다. 학습 시, images의 크기를 로 조정하고 나이, 성별, 안경 착용 여부를 condition으로 사용하였다.
4.2 Baselines and Evaluation Strategies
Constructed templates를 평가하는 것은 어렵다. 예를 들면 weak deformation regularization은 templates과 target images의 정확한 mathcing을 기대할 수 있지만 해부학 측면에서 불가능한 결과를 생성한다. 반면에 strong regularization은 자연스러운 결과를 얻지만 align이 상대적으로 잘 되지 않는다.
본 논문에서는 생성된 templates이 높은 sharpness, 정확한 alignment와 자연스러운 deformation을 갖고 있다고 가정하고 평가한다. 평가 항목은 다음과 같이 정의된다.
- Template에서 target image로 transform 된 segmentation labels의 average dice coefficients
- Mean determinant of the Jacobian matrix 인 경우, local folding of the deformation field 인 경우, smooth local deformation
- Average deformation norm 값이 작을 수록 template의 centrality가 좋다.
- Moving average of deformation 값이 작을 수록 template의 centrality가 좋다.
4.3 Implementation Details
Batch size는 3D neuroimages 1, 2D planar images는 32로 설정했다.
regularization 이외에 hyperparmaeter는 dataset마다 모두 동일하다.
공정한 평가를 위해서 모든 datasets는 VXM의 architecture와 hyperparameters를 따른다.
4.4 Results and Analysis

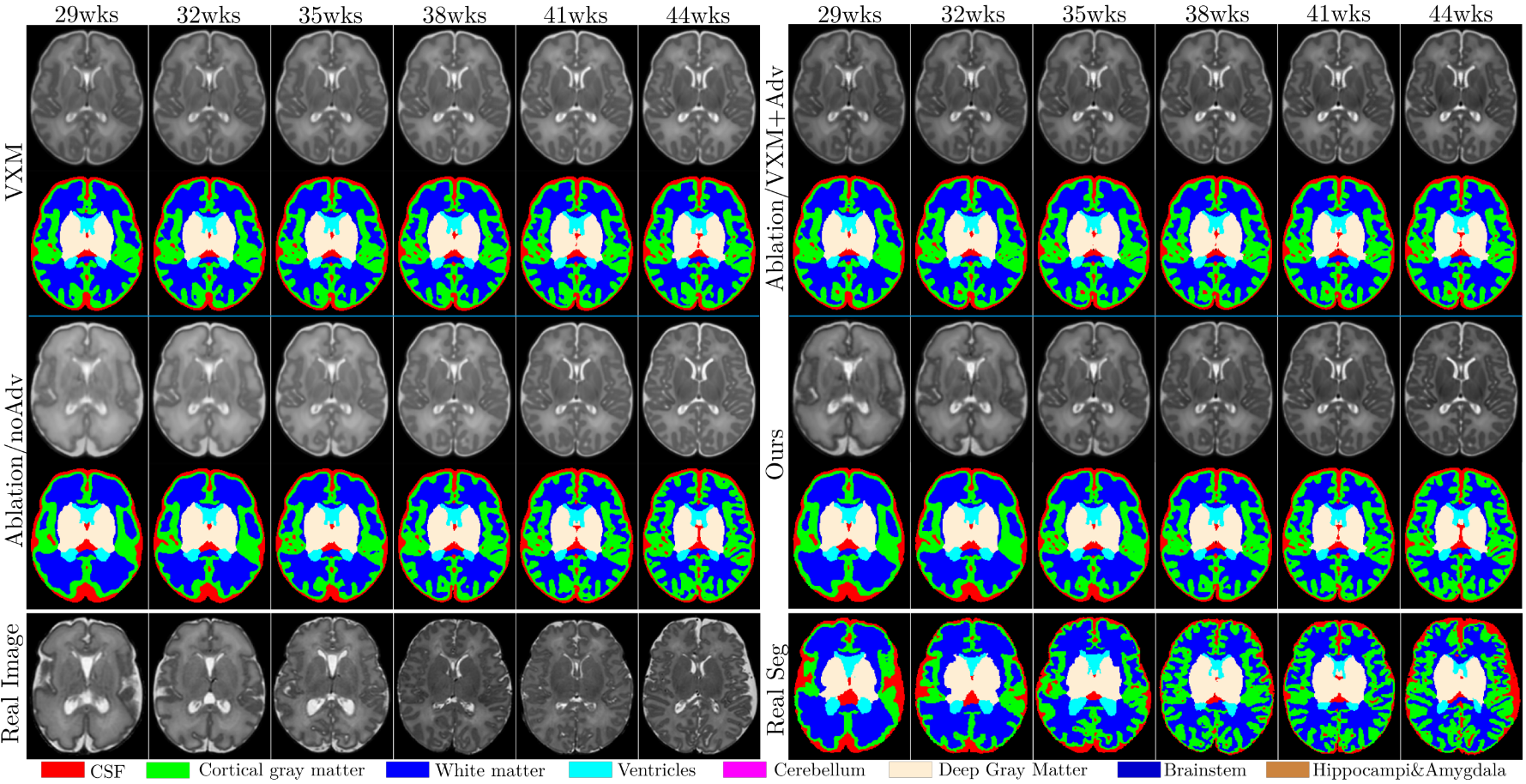
위 그림은 adversarial approach가 해부학적으로 정확한 templates를 생성함을 보여준다.

Anatomical segmentations가 함께 주어진 age-conditional templates이다. 본 논문의 모델이 가장 underlying trends를 잘 따름을 확인할 수 있다.
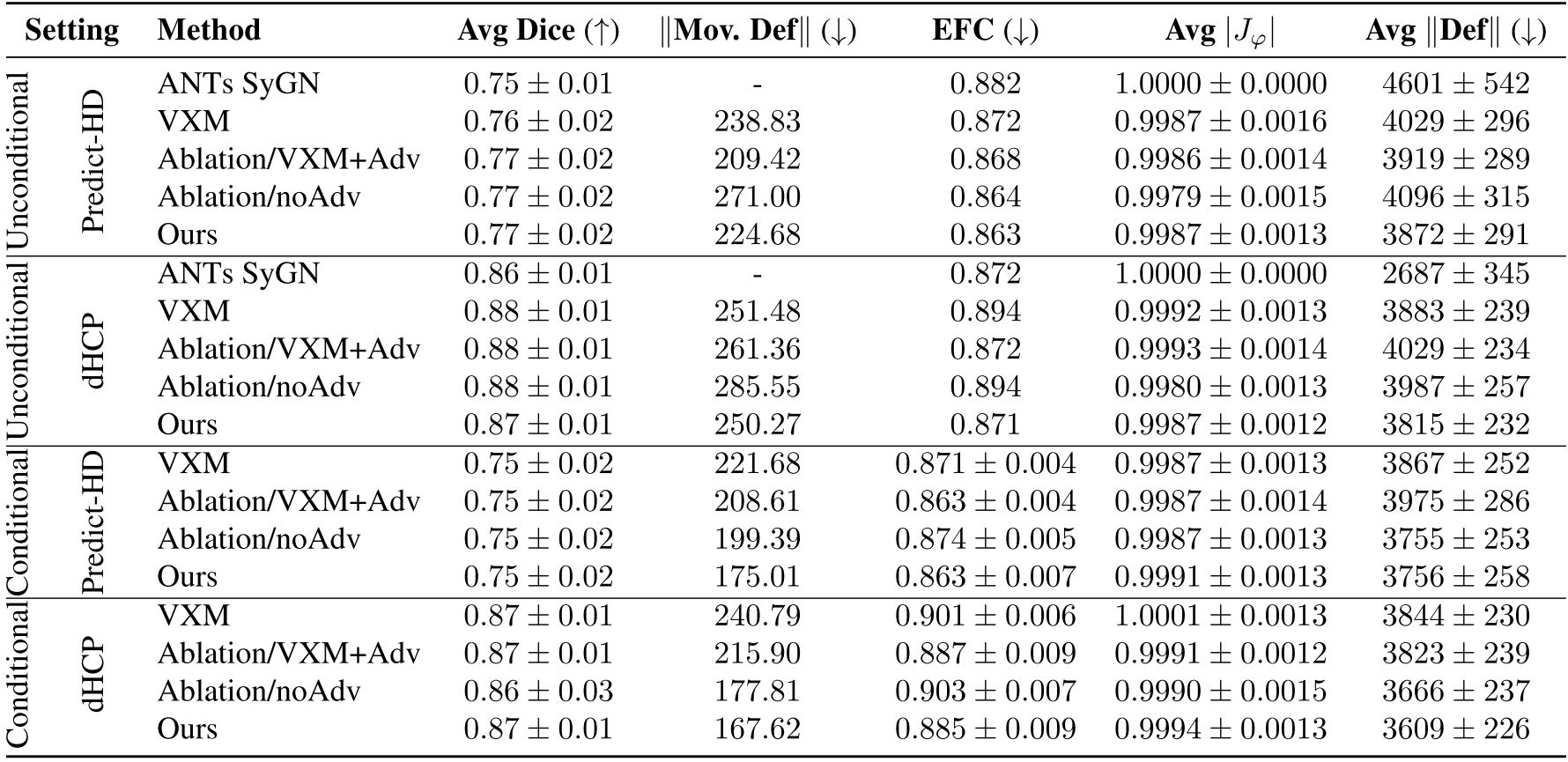
위 표는 정량적 결과를 요약한 것이다. 모든 methods는 비슷한 dice coefficients, smooth deformation ()를 달성하였다. EFC (Temporal Entropy Focus Criteria)는 본 논문의 모델이 가장 좋은 결과를 보여준다.
5. Conclusions
Gradient decent와 deep learning methods를 사용하여 conditional deformable templates를 construction하는 것은 매우 유용한 방법이다. 본 논문에서는 GAN을 활용하여 generative synthesis 방식으로 접근하였다. 그 결과 template는 해부학 적으로 자연스러우며 underlying demographics를 잘 반영한다. 그리고 age가 condition으로 주어졌을 때 lifespans에 따른 templates를 neurodegeneration 없이 잘 생성한다. 마지막으로 본 논문은 neuroimageing 관점에서 작성되었지만 일반적인 imaging modalities에도 적용될 수 있다.
