.png)
DNN loss 조건
Train data에서의 Loss 총합은 개별데이터 loss 합과 같아야 한다.
DNN 출력 값으로 loss 계산하고 중간 단계에서 하지 않는다.
Maximum-Likelihood 관점에 따라
정확한 y값보다 y를 평균으로하는 분포를 찾고 싶다.( 분포 파라미터를 찾고 싶다.)
2가지 가정
- 모든 데이터가 독립적이다.
- 각각의 데이터가 동일한 분포를 가진다.(보통 가우시안 or 베르누이로 정의한다.)
가우시안 분포로 정의할 경우 M-L의 관점에서 MSE식이 도출된다.
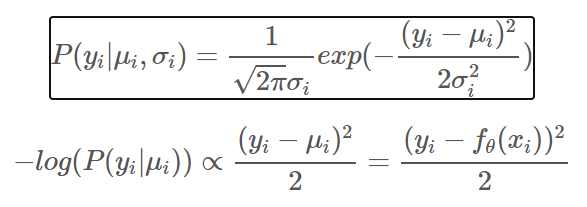
베르누이 분포로 정의할 경우 M-L의 관점에서 CEE식이 도출된다.
.png)

NLP Researcher : https://hyukhunkoh-ai.github.io/