[준비물]
- python 실습 환경
- VScode 또는 Jupyter Notebook
- Colab
1. 스크래핑이란?
웹 스크래핑은 웹 페이지를 가져와 HTML 등을 파싱하여 필요한 데이터를 추출해내는 것을 말한다. 크게 보면, 웹 사이트에 존재하는 컨텐츠를 긁어오는 것을 말한다.
웹 크롤링과 혼동할 수 있다. 웹 크롤링은 정보를 추출한다는 점에서 공통점이 있으나, 특정 웹 페이지를 타겟으로 하지 않는다는 점에서 차이가 있다.
웹 크롤링은 웹 페이지를 순회하면서 특정한 데이터를 수집하고, 이를 목적에 맞게 분석 및 저장한다. 웹 크롤링은 보통 '크롤러'라고 불리어지는 프로그램을 사용하여 이루어진다. 웹 크롤러는 보통 URL을 수집하고, 수집된 각 URL에 접근 및 필요한 정보를 추출한다. 이후 추출된 데이터를 가공 및 처리한 후 저장 및 분석하여 목적에 맞게 활용한다. 큰 범위에서 데이터를 수집할 때 사용된다.
검색 엔진을 예로 들어보자.
검색 엔진에 사용되는 웹 크롤러의 경우에는 URL을 수집하고 웹 페이지를 복사하여, 수집한 웹 페이지에 색인(index)을 부여한다.
이처럼 크롤링과 스크래핑은 포함관계에서 차이가 나며, 스크래핑은 크롤링의 하위 집합으로 볼 수 있다. 아래는 chatGPT에게 "스크래핑의 상위 개념이 크롤링이야?" 라고 물어본 후 얻은 답변이다.
- 스크래핑(Scraping)은 크롤링(Crawling)의 하위 집합이라고 볼 수 있습니다. 이 둘은 웹 데이터를 추출하는 데 사용되는 프로세스의 다른 측면을 나타냅니다.
- 크롤링(Crawling): 크롤링은 인터넷을 횡단하여 웹 페이지를 검색하고 데이터를 수집하는 프로세스를 말합니다. 크롤러(웹 스파이더)가 여러 웹 페이지를 자동으로 탐색하면서 URL을 추출하고 해당 페이지의 내용을 수집합니다. 크롤링은 주로 검색 엔진이나 웹 인덱스에서 사용되며, 큰 규모의 데이터 수집이 목적입니다.
- 스크래핑(Scraping): 스크래핑은 특정 웹 페이지에서 원하는 정보를 추출하는 과정을 나타냅니다. 크롤링 이후에는 스크래핑을 통해 추출된 데이터에서 필요한 정보만을 골라내거나 가공합니다. 스크래핑은 보통 HTML 또는 XML 문서에서 데이터를 파싱하고 추출하는 기술을 사용합니다.
- 따라서 크롤링은 여러 웹 페이지를 대상으로 하는 일반적인 데이터 수집 프로세스를 의미하며, 스크래핑은 특정 웹 페이지에서 원하는 정보를 추출하는 구체적인 작업을 가리킵니다. 종종, 크롤링과 스크래핑이 결합되어 사용되어 큰 규모의 데이터를 수집하고 해당 데이터에서 필요한 정보를 추출하는 작업이 이루어집니다.
2. 스크래핑은 어떻게 할 수 있는가?
크롤링을 통해 업무 효율을 향상할 수도 있고, 다양한 용도로 활용할 수 있을 것 같다!
이번 TIL에서는 스크래핑을 어떻게 할 수 있는지에 대해 알아볼 예정이다.
웹 스크래핑을 수행하려면 몇 가지 기본 단계를 따라야 하는데, 아래와 같다.
-
URL 결정:
- 스크래핑하려는 대상 웹 페이지의 URL 결정
-
라이브러리 선택:
- 파이썬에서는 Beautiful Soup, lxml, Requests 등의 라이브러리를 사용하여 웹 스크래핑을 수행할 수 있다.
-
HTTP Request:
- 선택한 라이브러리를 사용하여 대상 웹 페이지에 HTTP 요청을 보내고, 이를 통해 웹 페이지의 소스 코드를 가져올 수 있다.
- 혹시나 HTTP에 대해 모른다면 MDN 문서를 확인하자.
-
페이지 Parsing:
- 가져온 웹 페이지의 소스 코드를 파싱하여 원하는 데이터를 추출한다. 이때 HTML 또는 XML의 구조를 이해하고, 추출하려는 데이터의 위치를 정확하게 찾는다.
-
데이터 추출:
- 파싱한 결과를 기반으로 필요한 데이터를 추출한다. 이때 CSS 선택자나 XPath를 사용하여 특정 요소를 식별한다.
-
데이터 가공:
- 추출한 데이터를 필요에 따라 가공 또는 정제한다.
(공백이나 불필요한 문자를 제거, 형 변환 등)
- 추출한 데이터를 필요에 따라 가공 또는 정제한다.
-
저장 / 활용:
- 추출하고 가공한 데이터를 원하는 형식으로 저장하거나 다른 시스템에 적용한다. 이를 통해 추출한 데이터를 분석, 시각화, 혹은 다른 용도로 활용할 수 있다.
예를 들어, 파이썬에서 Beautiful Soup과 Requests 라이브러리를 사용하여 간단한 웹 스크래핑을 수행하는 코드는 다음과 같다.
import requests
from bs4 import BeautifulSoup
# 대상 웹 페이지의 URL
url = "https://example.com"
# HTTP 요청을 보내고 웹 페이지의 소스 코드를 가져옴
response = requests.get(url)
html_content = response.content
# BeautifulSoup을 사용하여 HTML을 파싱
soup = BeautifulSoup(html_content, 'html.parser')
# 원하는 데이터 추출 (예: 제목 추출)
title = soup.title.text
# 추출한 데이터 출력 또는 다른 작업 수행
print("페이지 제목:", title)3. 스크래핑을 위한 기본 세팅
위에도 잠깐 설명했지만, 스크래핑을 위한 코드는 다음과 같다.
파이썬은 굉장히 좋은 라이브러리들을 많이 제공하는데, 스크래핑을 하기 위해 request와 bs4 라이브러리(중 BeautifulSoup)를 import하여 사용해보자.
-
우선, 스크래핑 대상 URL이 필요하다. 예시 URL로 다음을 사용하자.
url = "https://example.com"
-
다음으로는 해당 웹 서버(또는 proxy server)에서 소스코드를 가져오기 위해 해당 URL에 HTTP request를 보내야 한다. HTTP header는 다음과 같다.
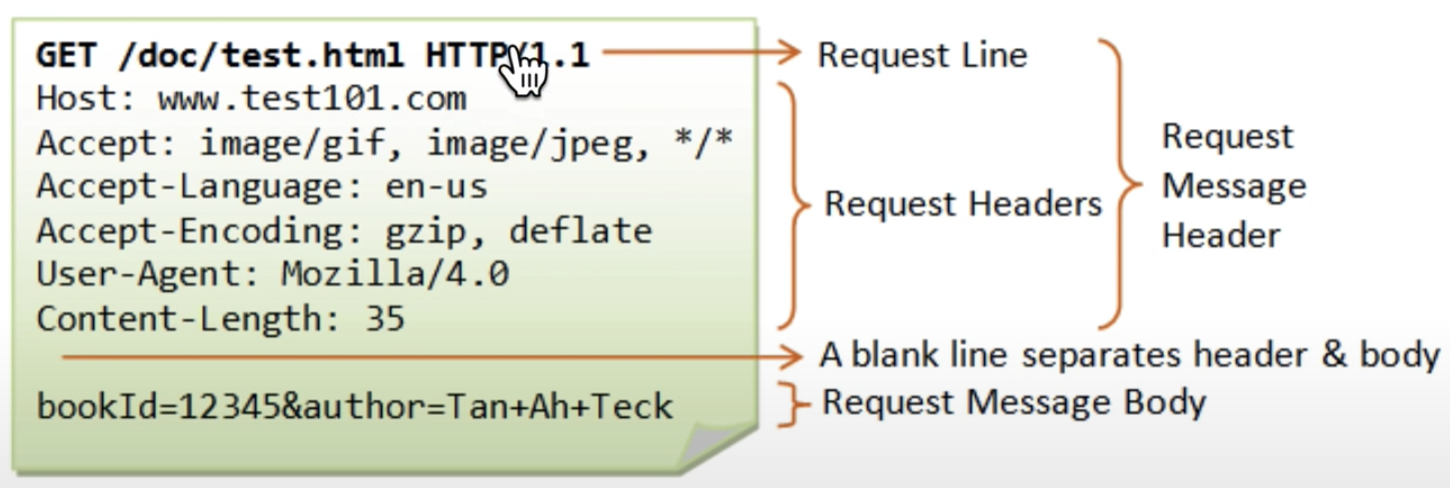
첫 번째 line을 해석하면 다음과 같다.
1. 어떤 방식으로 request할 것인가?
: GET, POST, HEAD, DELET 등이 존재한다. 우리는 서버로부터 무언가를 받고 싶으니, GET method로 request할 것이다.
2. URL
3. HTTP version
이후 아래 라인에는 데이터를 받고자 하는 User Agent의 정보 등이 들어간다. -
Page parsing
: BeautifulSoup의 html parser를 이용해 데이터를 파싱한다. 메소드 사용법에 대해서는 공식 문서를 참고하길 바란다. -
Data processing
: 원하는 형태의 데이터를 추출해낸다.
위의 4단계를 코드로 정리하면 아래와 같다.
# 스크래핑을 위한 라이브러리 import
import requests
from bs4 import BeautifulSoup
# target URL
URL = "https://movie.daum.net/ranking/reservation"
# HTTP request Header값
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# GET method로 HTTP request
data = requests.get(URL, headers=headers)
# server로 부터 받은 data를 parsing
soup = BeautifulSoup(data.text, 'html.parser')
# 원하는 데이터 추출
# selector를 통해 query를 가져와 title에 저장
title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
# query에서 필요한 데이터 추출
print(title.text)4. 주의할 점
인터넷에 있는 자료들을 무작정 긁어와 사용할 수 있을까?
만일 타사의 모든 데이터를 스크래핑하여 클론 코딩하고, 이를 상업적으로 이용한다면 굉장히 큰 문제가 발생할 것이다.
또한 스크랩핑을 시도하면서 상대에게 피해를 입히지 않도록 주의해야하는데, 스크랩핑은 서버와의 통신을 지속적으로 필요로 하여 packet을 반복적으로 주고받게 되기 때문이다. 이러한 일련의 과정을 반복하게 되면 서버에 과부하가 올 수있기에 웹에서는 페이지를 자주 왔다갔다 하면 크롤러라고 판단하여 서버를 차단시킨다.
따라서 기업에서는 이러한 상황을 방지하기 위해 (스크래퍼를 탐지하는) 여러 장치를 설정해놓았다.
robots.txt를 통해 접근범위가 어디까지 가능한지 확인할 수 있다고 하는데, 이에 대해서는 여기 를 참고하도록 하자.
5. Recent Scrapping Tech
우리의 니꼴라스 선생님이 이에 대해 업로드하신 영상이 있는데, 이 영상을 참고하면 좋을 것 같다.
[참고자료]
