Abstract
This technical report presents the training methodology and evaluation results of the open-source multilingual E5 text embedding models, released in mid-2023.
이 기술 보고서는 2023년 중반에 공개된 오픈소스 다국어 E5 텍스트 임베딩 모델의 훈련 방법론과 평가 결과를 제시합니다.
Three embedding models of different sizes (small / base / large) are provided, offering a balance between the inference efficiency and embedding quality.
추론 효율성과 임베딩 품질 간의 균형을 제공하는 세 가지 크기(소형/기본형/대형)의 임베딩 모델이 제공됩니다.
The training procedure adheres to the English E5 model recipe, involving contrastive pre-training on 1 billion multilingual text pairs, followed by fine-tuning on a combination of labeled datasets.
훈련 절차는 영어 E5 모델의 방식에 따르며, 10억 개의 다국어 텍스트 쌍을 이용한 대비 사전학습과 그 후의 라벨링된 데이터셋 조합을 이용한 미세 조정을 포함합니다.
Additionally, we introduce a new instruction-tuned embedding model, whose performance is on par with state-of-the-art, English-only models of similar sizes.
또한, 유사한 크기의 최신 영어 전용 모델들과 동등한 성능을 가진 새로운 지침 튜닝 임베딩 모델을 소개합니다.
Information regarding the model release can be found at https://github.com/microsoft/unilm/tree/master/e5
모델 공개에 대한 정보는 https://github.com/microsoft/unilm/tree/master/e5 에서 확인할 수 있습니다.
1. Introduction
Text embeddings serve as fundamental components in information retrieval systems and retrieval-augmented language models.
텍스트 임베딩은 정보 검색 시스템과 검색 기반 언어 모델에서 기본 구성 요소로 작용합니다.
Despite their significance, most existing embedding models are trained exclusively on English text (Reimers and Gurevych, 2019; Ni et al., 2022b,a), thereby limiting their applicability in multilingual contexts.
그 중요성에도 불구하고, 대부분의 기존 임베딩 모델은 영어 텍스트만으로 훈련되어 다국어 환경에서의 적용 가능성이 제한됩니다.
In this technical report, we present the multilingual E5 text embedding models (mE5-{small / base / large}), which extend the English E5 models (Wang et al., 2022).
이 기술 보고서에서는 영어 E5 모델(Wang et al., 2022)을 확장한 다국어 E5 텍스트 임베딩 모델(mE5-{소형/기본형/대형})을 소개합니다.
The training procedure adheres to the original two-stage methodology: weakly-supervised contrastive pre-training on billions of text pairs, followed by supervised fine-tuning on small quantity of high-quality labeled data.
훈련 절차는 본래의 두 단계 방식에 따르며, 수십억 개의 텍스트 쌍을 이용한 약지도 대비 사전학습 후, 소량의 고품질 라벨링 데이터로 감독 미세 조정을 수행합니다.
We also release an instruction-tuned embedding model mE5-large-instruct by utilizing the synthetic data from Wang et al. (2023).
또한, Wang et al. (2023)의 합성 데이터를 활용하여 지침 튜닝 임베딩 모델인 mE5-large-instruct도 함께 공개합니다.
Instructions can better inform embedding models about the task at hand, thereby enhancing the quality of the embeddings.
지침은 임베딩 모델이 주어진 작업을 더 잘 이해하게 하여 임베딩 품질을 향상시킬 수 있습니다.
For model evaluation, we first demonstrate that our multilingual embeddings exhibit competitive performance on the English portion of the MTEB benchmark (Muennighoff et al., 2023),
모델 평가에서는 먼저 우리 다국어 임베딩 모델이 MTEB 벤치마크의 영어 영역에서 경쟁력 있는 성능을 보임을 입증하고,
and the instruction-tuned variant even surpasses strong English-only models of comparable sizes.
지침 튜닝 모델은 유사한 크기의 강력한 영어 전용 모델을 능가하기도 합니다.
To showcase the multilingual capability of our models, we also assess their performance on the MIRACL multilingual retrieval benchmark (Zhang et al., 2023) across 16 languages and on Bitext mining (Zweigenbaum et al., 2018; Artetxe and Schwenk, 2019) in over 100 languages.
모델의 다국어 성능을 보여주기 위해, 16개 언어의 MIRACL 다국어 검색 벤치마크(Zhang et al., 2023)와 100개 이상의 언어를 포함한 Bitext 마이닝(Zweigenbaum et al., 2018; Artetxe and Schwenk, 2019)에서의 성능을 평가했습니다.
2. Training Methodology
Weakly-supervised Contrastive Pre-training
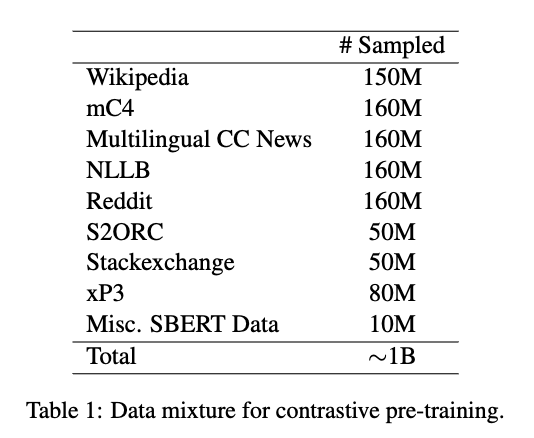
In the first stage, we continually pre-train our model on a diverse mixture of multilingual text pairs obtained from various sources as listed in Table 1.
1단계에서는 다양한 출처(표 1 참조)에서 수집한 다국어 텍스트 쌍을 혼합하여 모델을 지속적으로 사전학습합니다.
The models are trained with a large batch size 32k for a total of 30k steps, which approximately goes over ∼ 1 billion text pairs.
이 모델들은 배치 크기 32k로 총 30,000 스텝 동안 훈련되며, 약 10억 개의 텍스트 쌍을 처리합니다.
We employ the standard InfoNCE contrastive loss with only in-batch negatives, while other hyperparameters remain consistent with the English E5 models (Wang et al., 2022).
우리는 오직 배치 내 부정 예시만을 사용하는 표준 InfoNCE 대비 손실 함수를 적용하며, 다른 하이퍼파라미터는 영어 E5 모델(Wang et al., 2022)과 동일하게 유지합니다.
Supervised Fine-tuning
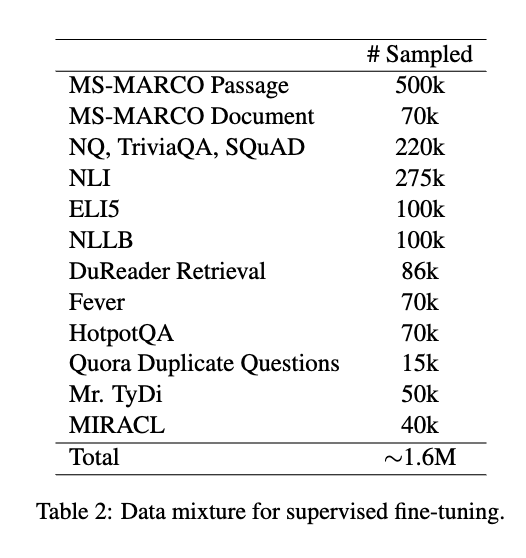
In the second stage, we fine-tune the models from the previous stage on a combination of high-quality labeled datasets.
2단계에서는 이전 단계에서 훈련된 모델을 고품질 라벨링 데이터셋 조합을 이용해 미세 조정합니다.
In addition to in-batch negatives, we also incorporate mined hard negatives and knowledge distillation from a cross-encoder model to further enhance the embedding quality.
배치 내 부정 예시 외에도, 채굴된 어려운 부정 예시와 크로스 인코더 모델로부터의 지식 증류를 활용하여 임베딩 품질을 더욱 향상시킵니다.
For the mE5-{small / base / large} models released in mid-2023, we employ the data mixture shown in Table 2.
2023년 중반에 공개된 mE5-{소형/기본형/대형} 모델에는 표 2에 명시된 데이터 조합이 사용됩니다.
For the mE5-large-instruct model, we adopt the data mixture from Wang et al. (2023), which includes additional 500k synthetic data generated by GPT-3.5/4 (OpenAI, 2023).
mE5-large-instruct 모델에는 Wang et al. (2023)에서 사용된 데이터 조합을 채택하였으며, 여기에는 GPT-3.5/4(OpenAI, 2023)가 생성한 추가 50만 개의 합성 데이터가 포함됩니다.
This new mixture encompasses 150k unique instructions and covers 93 languages.
이 새로운 데이터 조합은 15만 개의 고유 지침을 포함하고, 93개 언어를 포괄합니다.
We re-use the instruction templates from Wang et al. (2023) for both the training and evaluation of this instruction-tuned model.
이 지침 튜닝 모델의 훈련과 평가 모두에 Wang et al. (2023)의 지침 템플릿을 재사용합니다.
3. Experimental Results
English Text Embedding Benchmark
영어 텍스트 임베딩 벤치마크

Multilingual embedding models should be able to perform well on English tasks as well.
다국어 임베딩 모델은 영어 작업에서도 좋은 성능을 보여야 합니다.
In Table 3, we compare our models with other multilingual and English-only models on the MTEB benchmark (Muennighoff et al., 2023).
표 3에서는 MTEB 벤치마크(Muennighoff et al., 2023)에서 우리의 모델을 다른 다국어 및 영어 전용 모델과 비교합니다.
Our best mE5 model surpasses the previous state-of-the-art multilingual model Cohere-multilingual-v3, by 0.4 points
우리의 최고 mE5 모델은 이전 최신 다국어 모델인 Cohere-multilingual-v3보다 0.4점 더 높은 성능을 보였습니다.
and outperforms a strong English-only model, BGE-large-en-v1.5, by 0.2 points.
또한 강력한 영어 전용 모델인 BGE-large-en-v1.5보다도 0.2점 높은 성능을 기록했습니다.
While smaller models demonstrate inferior performance,
작은 모델들은 낮은 성능을 보이긴 하지만,
their faster inference and reduced storage costs render them advantageous for numerous applications.
빠른 추론 속도와 낮은 저장 공간 요구로 인해 다양한 응용 분야에서 유리합니다.
Multilingual Retrieval
다국어 검색
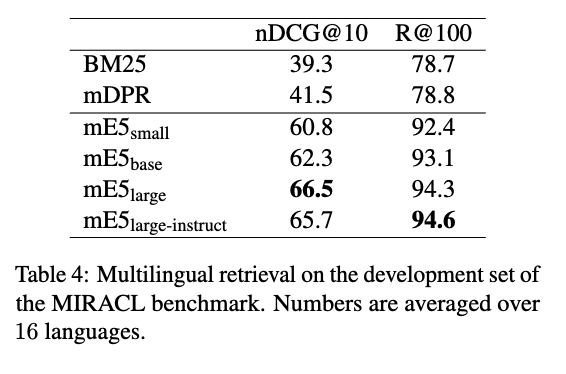
We evaluate the multilingual retrieval capability of our models using the MIRACL benchmark (Zhang et al., 2023).
우리는 MIRACL 벤치마크(Zhang et al., 2023)를 이용해 모델의 다국어 검색 능력을 평가했습니다.
As shown in Table 4, mE5 models significantly outperform mDPR,
표 4에서 보이듯이, mE5 모델은 MIRACL 훈련셋으로 미세 조정된 mDPR 모델보다 확연히 높은 성능을 보였습니다.
which has been fine-tuned on the MIRACL training set, in both nDCG@10 and recall metrics.
mDPR은 MIRACL 훈련셋으로 미세 조정되었음에도 불구하고, mE5는 nDCG@10 및 리콜 지표 모두에서 더 나은 성능을 보였습니다.
Detailed results on individual languages are provided in Appendix Table 6.
각 언어별 상세 결과는 부록의 표 6에 제공됩니다.
Bitext Mining
바이텍스트 마이닝
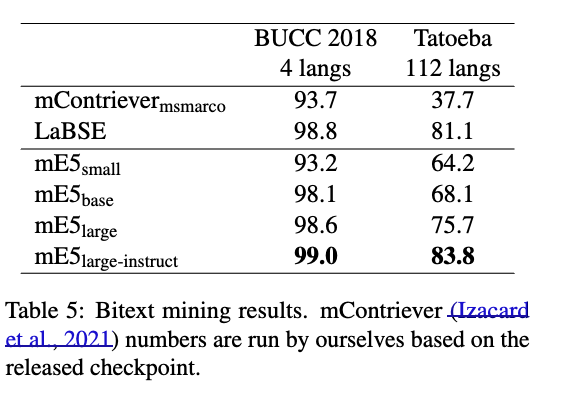
Bitext Mining is a cross-lingual similarity search task that requires the matching of two sentences with little lexical overlap.
바이텍스트 마이닝은 어휘적 유사성이 거의 없는 두 문장을 매칭해야 하는 언어 간 유사도 검색 작업입니다.
As demonstrated in Table 5, mE5 models exhibit competitive performance across a broad range of languages, both high-resource and low-resource.
표 5에서 확인할 수 있듯이, mE5 모델은 고자원 및 저자원 언어 모두에서 경쟁력 있는 성능을 보여줍니다.
Notably, the mE5-large-instruct model surpasses the performance of LaBSE, a model specifically designed for bitext mining,
특히 mE5-large-instruct 모델은 바이텍스트 마이닝을 위해 특별히 설계된 LaBSE 모델의 성능을 능가합니다.
due to the expanded language coverage afforded by the synthetic data (Wang et al., 2023).
이는 Wang et al. (2023)이 제공한 합성 데이터 덕분에 언어 범위가 확장되었기 때문입니다.
4. Conclusion
In this brief technical report, we introduce multilingual E5 text embedding models that are trained with a multi-stage pipeline.
이 간단한 기술 보고서에서는 다단계 파이프라인으로 훈련된 다국어 E5 텍스트 임베딩 모델을 소개합니다.
By making the model weights publicly available, practitioners can leverage these models for information retrieval, semantic similarity, and clustering tasks across a diverse range of languages.
모델 가중치를 공개함으로써, 실무자들은 이 모델들을 다양한 언어에 걸친 정보 검색, 의미 유사도, 클러스터링 작업에 활용할 수 있습니다.
