Text2SQL is Not Enough: Unifying AI and Databases with TAG 논문 번역
ABSTRACT
AI systems that serve natural language questions over databases promise to unlock tremendous value.
데이터베이스 위에서 자연어 질문을 처리하는 AI 시스템은 막대한 가치를 창출할 잠재력을 지니고 있습니다.
Such systems would allow users to leverage the powerful reasoning and knowledge capabilities of language models (LMs) alongside the scalable computational power of data management systems.
이러한 시스템은 사용자가 언어 모델(LM)의 강력한 추론 및 지식 능력을 데이터 관리 시스템의 확장 가능한 계산 능력과 함께 활용할 수 있게 합니다.
These combined capabilities would empower users to ask arbitrary natural language questions over custom data sources.
이러한 결합된 기능은 사용자가 원하는 자연어 질문을 맞춤형 데이터 소스에 대해 자유롭게 할 수 있도록 해줍니다.
However, existing methods and benchmarks insufficiently explore this setting.
하지만 기존 방법들과 벤치마크는 이 설정을 충분히 탐구하지 못하고 있습니다.
Text2SQL methods focus solely on natural language questions that can be expressed in relational algebra, representing a small subset of the questions real users wish to ask.
Text2SQL 방식은 관계 대수로 표현 가능한 자연어 질문에만 집중하며, 이는 실제 사용자가 하고자 하는 질문의 일부에 불과합니다.
Likewise, Retrieval-Augmented Generation (RAG) considers the limited subset of queries that can be answered with point lookups to one or a few data records within the database.
마찬가지로, Retrieval-Augmented Generation (RAG)은 데이터베이스 내의 하나 또는 몇 개의 레코드만 조회해서 답할 수 있는 제한된 범위의 질문만을 다룹니다.
We propose Table-Augmented Generation (TAG), a unified and general-purpose paradigm for answering natural language questions over databases.
우리는 Table-Augmented Generation (TAG)이라는 데이터베이스 위의 자연어 질문에 답하는 통합적이고 범용적인 패러다임을 제안합니다.
The TAG model represents a wide range of interactions between the LM and database that have been previously unexplored and creates exciting research opportunities for leveraging the world knowledge and reasoning capabilities of LMs over data.
TAG 모델은 지금까지 탐구되지 않았던 LM과 데이터베이스 간의 다양한 상호작용을 나타내며, LM의 세계 지식과 추론 능력을 데이터 위에서 활용하는 새로운 연구 기회를 제공합니다.
We systematically develop benchmarks to study the TAG problem and find that standard methods answer no more than 20% of queries correctly, confirming the need for further research in this area.
우리는 TAG 문제를 연구하기 위한 벤치마크를 체계적으로 개발했고, 기존 방식들이 질의의 20% 이상을 정확히 처리하지 못한다는 사실을 발견하여, 이 분야에서의 추가 연구 필요성을 확인했습니다.
We release code for the benchmark at https://github.com/TAG-Research/TAG-Bench.
우리는 벤치마크용 코드를 https://github.com/TAG-Research/TAG-Bench 에 공개했습니다.
1 INTRODUCTION
Language models promise to revolutionize data management by letting users ask natural language questions over data, which has led to a great deal of research in Text2SQL and Retrieval-Augmented Generation (RAG) methods.
언어 모델은 사용자가 데이터를 대상으로 자연어로 질문할 수 있게 함으로써 데이터 관리에 혁신을 가져올 것으로 기대되며, 이는 Text2SQL과 Retrieval-Augmented Generation(RAG) 방식에 대한 활발한 연구로 이어졌습니다.
In our experience, however (including from internal workloads and customers at Databricks), users’ questions often transcend the capabilities of these paradigms, demanding new research investment towards systems that combine the logical reasoning abilities of database systems with the natural language reasoning abilities of modern language models (LMs).
하지만 Databricks 내부 업무나 고객 사례를 통해 본 경험상, 사용자 질문은 종종 기존 패러다임의 한계를 넘어서며, 데이터베이스 시스템의 논리적 추론 능력과 최신 언어 모델의 자연어 추론 능력을 결합한 새로운 시스템에 대한 연구 투자가 필요합니다.
In particular, we find that real business users’ questions often require sophisticated combinations of domain knowledge, world knowledge, exact computation, and semantic reasoning.
특히 실제 비즈니스 사용자의 질문은 도메인 지식, 세계 지식, 정확한 계산, 의미적 추론을 정교하게 조합해야 하는 경우가 많습니다.
Database systems clearly provide a source of domain knowledge through the up-to-date data they store, as well as exact computation at scale (which LMs are bad at).
데이터베이스 시스템은 최신 데이터를 통해 도메인 지식을 제공하고, 대규모 정확한 계산을 수행할 수 있으며, 이는 언어 모델이 잘하지 못하는 부분입니다.
LMs offer to extend the existing capabilities of databases in two key ways.
언어 모델은 두 가지 주요 방식으로 데이터베이스의 기존 기능을 확장할 수 있습니다.
First, LMs possess semantic reasoning capabilities over textual data, a core element of many natural language user queries.
첫째, 언어 모델은 텍스트 데이터에 대한 의미적 추론 능력을 지니며, 이는 많은 자연어 질문의 핵심 요소입니다.
For example, a Databricks customer survey showed users wish to ask questions like which customer reviews of product X are positive?, or why did my sales drop during this period?.
예를 들어, Databricks 고객 설문에서 사용자는 "제품 X의 고객 리뷰 중 긍정적인 것은 무엇인가?" 또는 "이 시기에 매출이 감소한 이유는 무엇인가?"와 같은 질문을 하고 싶어합니다.
These questions present complex reasoning-based tasks, such as sentiment analysis over free-text fields or summarization of trends.
이러한 질문은 자유 텍스트 필드에 대한 감성 분석이나 트렌드 요약과 같은 복잡한 추론 기반 작업을 요구합니다.
LMs are well-suited to these tasks, which cannot be modeled by the exact computation or relational primitives in traditional database systems.
이러한 작업은 전통적인 데이터베이스의 정확한 계산이나 관계 연산만으로는 모델링할 수 없으며, 언어 모델이 더 적합합니다.
Secondly, the LM, using knowledge learned during model training and stored implicitly by the model’s weights, can powerfully augment the user’s data with world knowledge that is not captured explicitly by the database’s table schema.
둘째, 언어 모델은 학습 중에 습득하고 모델 파라미터에 암묵적으로 저장된 세계 지식을 활용하여, 데이터베이스의 테이블 스키마에 명시되지 않은 지식을 보완할 수 있습니다.
As an example, a Databricks internal AI user asked what are the QoQ trends for the "retail" vertical? over a table containing attributes for account names, products and revenue.
예를 들어, Databricks 내부 사용자가 "retail" 산업군의 QoQ(분기 대비) 트렌드는 무엇인가요?라는 질문을 테이블 속 계정 이름, 제품, 수익 속성을 기반으로 했습니다.
To answer this query the system must understand how the business defines QoQ (e.g., the quarter over quarter trends from the last quarter to the current quarter or this quarter last year to this quarter this year), as well as which companies are considered to be in the retail vertical.
이 질문에 답하려면, 시스템은 기업이 QoQ를 어떻게 정의하는지(예: 전 분기 대비 현 분기 또는 전년 동기 대비 현 분기), 그리고 어떤 회사들이 "retail" 범주에 속하는지 이해해야 합니다.
This task is well-suited to leverage the knowledge held by a pre-trained or fine-tuned LM.
이러한 작업은 사전 학습 또는 미세 조정된 언어 모델의 지식을 활용하는 데 매우 적합합니다.
Systems that efficiently leverage databases and LMs together to serve natural language queries, in their full generality, hold potential to transform the way users understand their data.
데이터베이스와 언어 모델을 효과적으로 결합하여 자연어 질의를 처리하는 시스템은 사용자 데이터 이해 방식을 획기적으로 변화시킬 잠재력을 지니고 있습니다.
Unfortunately, these questions cannot be answered today by common methods, such as Text2SQL and RAG.
안타깝게도, 이러한 질문은 현재의 Text2SQL이나 RAG 방식으로는 답변할 수 없습니다.
While Text2SQL methods [26, 28, 31, 32] are suitable for the subset of natural language queries that have direct relational equivalents, they cannot handle the vast array of user queries that require semantic reasoning or world knowledge.
Text2SQL 방식은 관계형 연산으로 직접 변환 가능한 자연어 질문에는 적합하지만, 의미적 추론이나 세계 지식을 요구하는 다양한 질문에는 대응할 수 없습니다.
For instance, the previous user query asking which customer reviews are positive may require logical row-wise LM reasoning over reviews to classify each as positive or negative.
예를 들어, "어떤 고객 리뷰가 긍정적인가요?"라는 질문은 각 리뷰를 긍정 또는 부정으로 분류하기 위한 행 단위의 언어 모델 추론을 필요로 합니다.
Similarly the question which asks why sales dropped entails a reasoning question that must aggregate information across many table entries.
마찬가지로 "왜 매출이 감소했는가?"라는 질문은 여러 테이블 항목의 정보를 집계해야 하는 추론을 필요로 합니다.
On the other hand, the RAG model is limited to simple relevance-based point lookups to a few data records, followed by a single LM invocation.
반면, RAG 모델은 몇 개의 데이터 레코드에 대해 단순 연관성 기반 조회를 수행하고, 한 번의 언어 모델 호출로 응답하는 데 그칩니다.
This model serves only the subset of queries answerable by point lookups and also fails to leverage the richer query execution capabilities of many database systems, which leaves computational tasks (e.g., counting, math and filtering) to a single invocation of the error-prone LM.
이 모델은 조회 기반으로 답변 가능한 질의에만 대응하며, 많은 데이터베이스 시스템의 풍부한 질의 실행 능력을 활용하지 못하고, 계산 작업(예: 개수 세기, 수학, 필터링)을 오류 가능성이 높은 단일 LM 호출에 맡기게 됩니다.
In addition to being error prone and inefficient at computational tasks, LMs have also been shown to perform poorly on long-context prompts limiting their ability to reason about data at scale in the generation phase of RAG.
계산 작업에서 오류가 많고 비효율적일 뿐 아니라, 언어 모델은 긴 문맥에 대한 성능이 낮아, RAG 생성 단계에서 대규모 데이터에 대한 추론 능력도 제한됩니다.
We instead propose table-augmented generation (TAG) as a unified paradigm for systems that answer natural language questions over databases.
우리는 대신, 데이터베이스 위의 자연어 질문에 답변하는 시스템을 위한 통합 패러다임으로 Table-Augmented Generation (TAG)을 제안합니다.
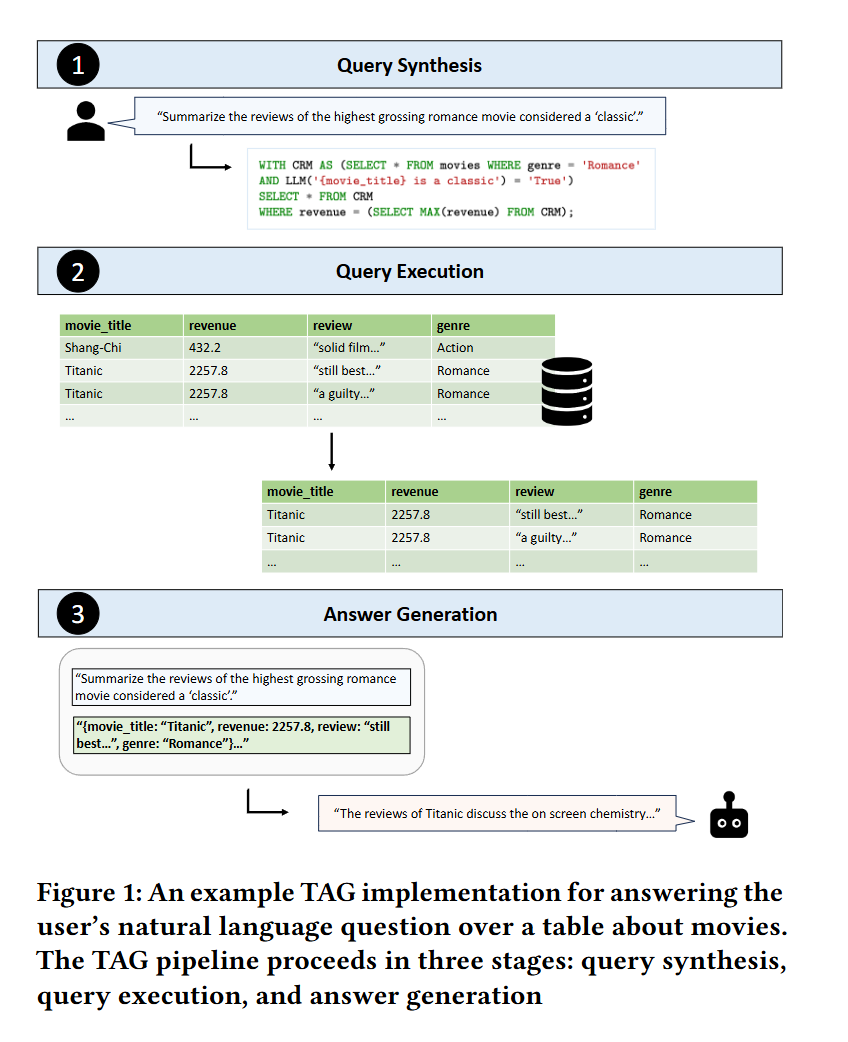
Specifically, TAG defines three key steps, as shown in Figure 1.
구체적으로 TAG는 그림 1에 제시된 세 가지 핵심 단계를 정의합니다.
First, the query synthesis step syn translates the user’s arbitrary natural language request 𝑅 to an executable database query 𝑄.
첫 번째로, 쿼리 생성 단계인 syn은 사용자의 임의의 자연어 요청 𝑅을 실행 가능한 데이터베이스 쿼리 𝑄로 변환합니다.
Then, the query execution step exec executes 𝑄 on the database system to efficiently compute the relevant data 𝑇.
그 다음 쿼리 실행 단계인 exec은 데이터베이스 시스템에서 𝑄를 실행하여 관련 데이터 𝑇를 효율적으로 계산합니다.
Lastly, the answer generation step gen utilizes 𝑅 and 𝑇, where the LM is orchestrated, possibly in iterative or recursive patterns over the data, to generate the final natural language answer 𝐴.
마지막으로, 답변 생성 단계인 gen은 𝑅과 𝑇를 활용해 언어 모델이 반복적 또는 재귀적으로 작동하여 최종 자연어 답변 𝐴를 생성합니다.
The TAG model is simple, but powerful: it is defined by the following three equations, but captures a wide range of previously under-studied interactions between LMs and databases.
TAG 모델은 단순하지만 강력하며, 다음의 세 가지 수식으로 정의되지만 언어 모델과 데이터베이스 간의 다양한 상호작용을 포괄합니다.
Query Synthesis: syn(𝑅) → 𝑄 (1)
쿼리 생성: syn(𝑅) → 𝑄 (1)
Query Execution: exec(𝑄) → 𝑇 (2)
쿼리 실행: exec(𝑄) → 𝑇 (2)
Answer Generation: gen(𝑅, 𝑇) → 𝐴 (3)
답변 생성: gen(𝑅, 𝑇) → 𝐴 (3)
Notably, the TAG model unifies prior methods, including both Text2SQL and RAG, which represent special cases of TAG and serve only a limited subset of user questions.
주목할 점은 TAG 모델이 이전 방법들인 Text2SQL과 RAG을 포함하는 일반화된 형태로, 이들 방법은 TAG의 특수한 사례일 뿐이며 사용자 질문의 일부만 처리할 수 있습니다.
While several prior works address these special cases of TAG, we provide the first end-to-end TAG benchmark composed of a broad set of realistic queries that require LM reasoning and knowledge capabilities.
기존 연구들이 이러한 TAG의 특수 사례들을 다뤘다면, 우리는 언어 모델의 추론 및 지식 능력을 요구하는 현실적인 질의로 구성된 최초의 end-to-end TAG 벤치마크를 제안합니다.
We demonstrate the significant research challenges posed by these types of questions, as well as the promise of efficient TAG implementations.
우리는 이러한 유형의 질문이 제기하는 중요한 연구 과제와 효율적인 TAG 구현의 가능성을 보여줍니다.
Our evaluation analyzes the vanilla Text2SQL and RAG baselines as well as two stronger baselines, Text2SQL with LM generation and retrieval with LM-based re-ranking.
우리는 기본 Text2SQL과 RAG 외에도, LM을 이용한 Text2SQL 생성 및 LM 기반 재정렬이 포함된 검색 방식이라는 두 가지 더 강력한 기준 모델을 분석합니다.
Across a variety of query types, we find each baseline method consistently fails to achieve high accuracy, never surpassing 20% exact match on the benchmark.
다양한 쿼리 유형에서 각 기준 모델이 일관되게 높은 정확도를 달성하지 못하며, 벤치마크에서 20%의 정확 일치율을 넘지 못하는 것으로 나타났습니다.
On the other hand, we implement hand-written TAG pipelines on top of the recent LOTUS runtime [21] and find they achieve up to 20–65% higher accuracy compared to the baselines.
반면, 최근 LOTUS 런타임 위에 수작업으로 작성한 TAG 파이프라인을 구현한 결과, 기준 모델에 비해 최대 20~65% 더 높은 정확도를 달성했습니다.
This significant performance gap demonstrates the promise of building efficient TAG systems.
이와 같은 성능 차이는 효율적인 TAG 시스템 구축의 가능성을 보여줍니다.
2 THE TAG MODEL
We now describe the TAG model, which takes a natural language request 𝑅 and returns a natural language answer 𝐴 grounded in the data source.
이제 우리는 TAG 모델을 설명합니다. 이는 자연어 요청 𝑅을 받아, 데이터 소스를 기반으로 한 자연어 답변 𝐴를 생성합니다.
We outline three main steps that TAG systems implement: query synthesis, query execution, and answer generation.
TAG 시스템은 쿼리 생성, 쿼리 실행, 그리고 답변 생성이라는 세 가지 주요 단계를 포함합니다.
We define TAG tractably as a single iteration of these steps, but one can consider extending TAG in a multi-hop fashion.
TAG는 이 단계를 단일 반복으로 정의하지만, 다중 홉 방식으로 확장하는 것도 고려할 수 있습니다.
2.1 Query Synthesis
2.1 쿼리 생성 단계
The syn function takes a natural language request 𝑅 and generates a query 𝑄 to be executed by the database system.
syn 함수는 자연어 요청 𝑅을 받아 데이터베이스에서 실행할 수 있는 쿼리 𝑄를 생성합니다.
Given a user request, this step is responsible for (a) deducing which data is relevant to answering the request (e.g., using the table schema), and (b) performing semantic parsing to translate the user request into a query that can be executed by the database system.
이 단계에서는 (a) 어떤 데이터가 질의에 관련 있는지를 파악하고(예: 테이블 스키마 활용), (b) 사용자 요청을 데이터베이스 쿼리로 변환하는 의미론적 파싱을 수행합니다.
This query could be in any query language, but in our example we use SQL.
이 쿼리는 어떤 질의 언어로도 표현 가능하지만, 본 논문에서는 SQL을 예시로 사용합니다.
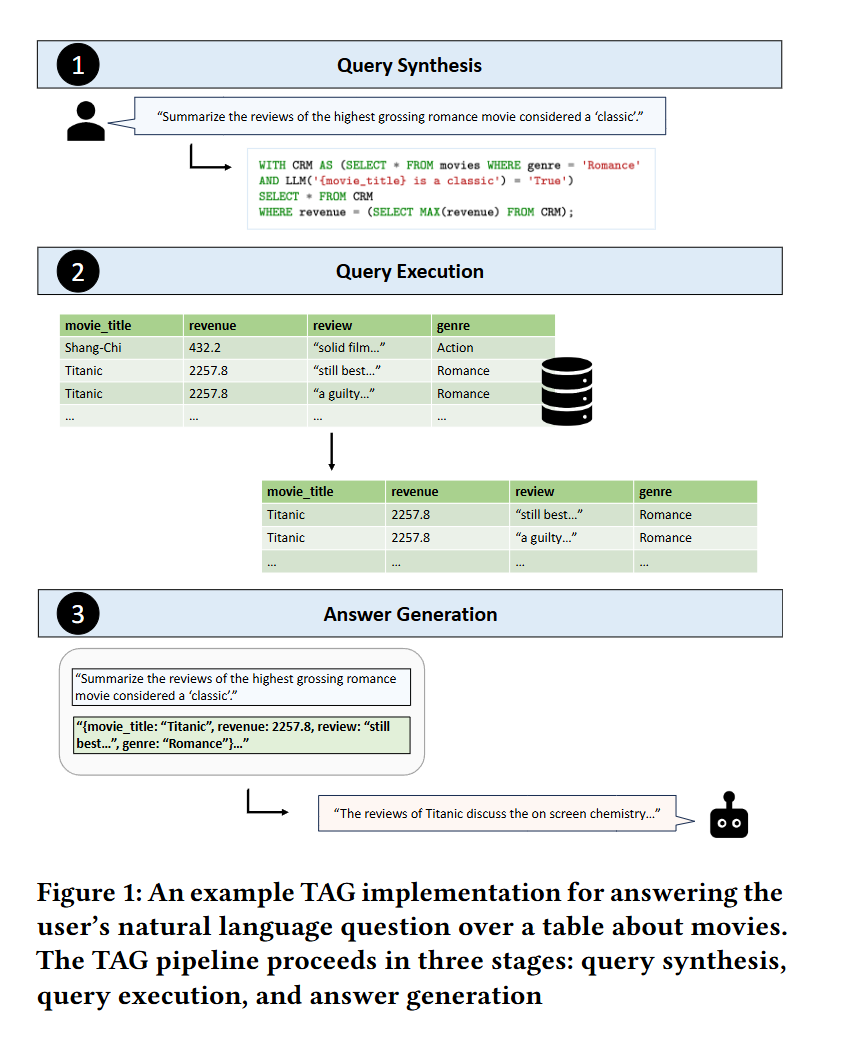
Figure 1 shows an example TAG instantiation for the user query which asks, “Summarize the reviews of the highest grossing romance movie considered a ‘classic’".
그림 1은 “가장 높은 수익을 낸 ‘클래식’ 로맨스 영화의 리뷰를 요약하라”는 사용자 질의에 대한 TAG 예시를 보여줍니다.
Here, the data source contains information about each movie’s title, revenue, genre, and an associated review.
여기서 데이터 소스에는 각 영화의 제목, 수익, 장르, 그리고 리뷰 정보가 포함되어 있습니다.
In this step, the system leverages the semantic reasoning abilities of the LM to generate a SQL query that uses attributes on movie_title, review, revenue, and genre from the data source.
이 단계에서 시스템은 언어 모델의 의미 추론 능력을 활용하여, movie_title, review, revenue, genre 속성을 활용한 SQL 쿼리를 생성합니다.
Note that in this example, the database API is able to execute LM UDFs within SQL queries, so this step also introduces calls to the LM for each row to identify classic films within the query.
이 예제에서는 데이터베이스 API가 SQL 쿼리 내에서 LM 사용자 정의 함수(UDF)를 실행할 수 있으므로, 쿼리 내에서 각 행마다 언어 모델을 호출하여 ‘클래식’ 영화를 식별합니다.
2.2 Query Execution
2.2 쿼리 실행
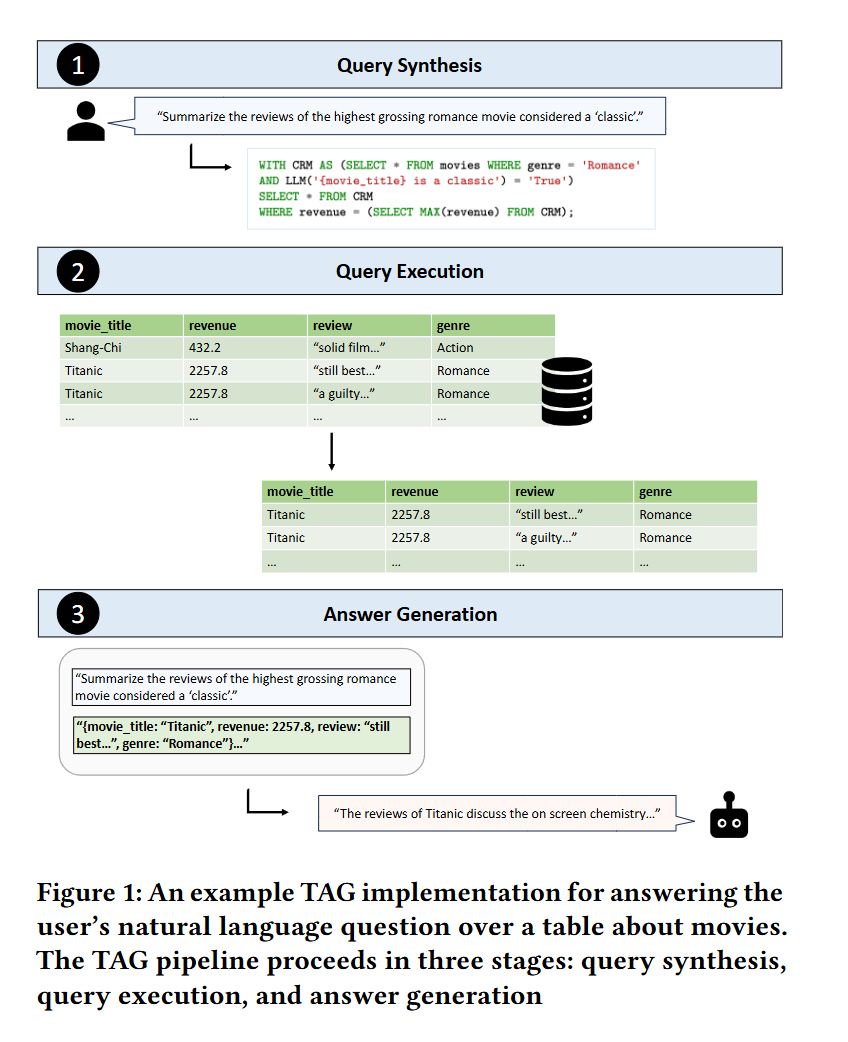
In the query execution step, the exec function executes the query 𝑄 in the database system to obtain the table 𝑇.
쿼리 실행 단계에서는 exec 함수가 데이터베이스 시스템에서 쿼리 𝑄를 실행하여 테이블 𝑇를 얻습니다.
This step leverages the database query engine to efficiently execute the query over vast amounts of stored data.
이 단계는 방대한 저장 데이터를 대상으로 쿼리를 효율적으로 실행하기 위해 데이터베이스 쿼리 엔진을 활용합니다.
The database API can be served by a wide variety of systems, which we explore in Section 3.
데이터베이스 API는 다양한 시스템에서 제공될 수 있으며, 이에 대한 내용은 3장에서 설명됩니다.
Some APIs may allow for LM-based operators [18–21], permitting the database engine to leverage the LM’s world knowledge and reasoning capabilities within exec.
일부 API는 언어 모델 기반 연산자 사용을 허용하며 [18–21], 이를 통해 데이터베이스 엔진은 exec 단계 내에서 언어 모델의 세계 지식과 추론 능력을 활용할 수 있습니다.
In the example shown in Figure 1, the database query is a selection and ranking query written in SQL, which returns a table containing relevant rows.
그림 1의 예시에서는 SQL로 작성된 선택 및 정렬 쿼리를 사용하며, 관련된 행들을 포함하는 테이블을 반환합니다.
The query performs the selection using an LM to assess which movies are classics according to their movie_title, as well as a standard filter on genre to find romance movies.
이 쿼리는 언어 모델을 이용해 movie_title을 기반으로 '클래식' 영화를 판별하고, 장르 필터를 통해 로맨스 영화를 선택합니다.
The query also ranks the results based on revenue to find the highest grossing film.
이 쿼리는 수익 기준으로 결과를 정렬하여 가장 높은 수익을 낸 영화를 찾습니다.
As the figure shows, the resulting table contains reviews for the movie “Titanic”.
그림에서 볼 수 있듯, 결과 테이블은 영화 "Titanic"에 대한 리뷰를 포함하고 있습니다.
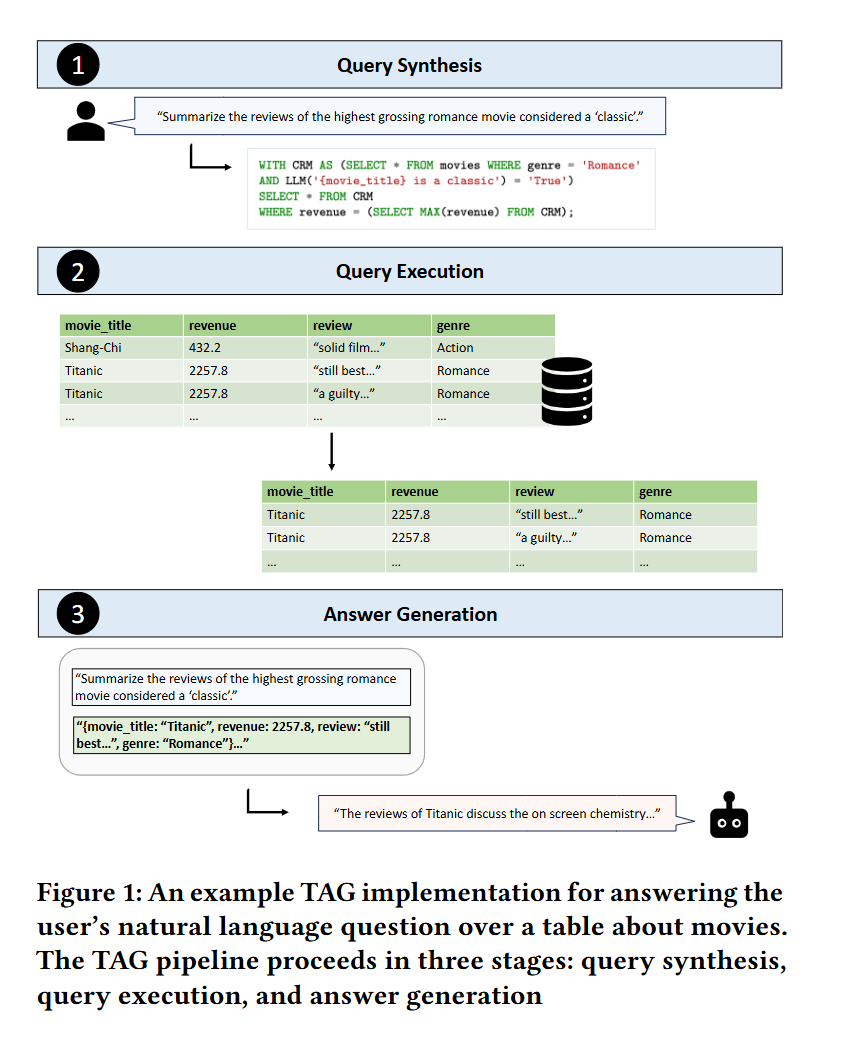
2.3 Answer Generation
2.3 답변 생성
The answer generation step in TAG mirrors the generation step in RAG.
TAG의 답변 생성 단계는 RAG의 생성 단계와 유사합니다.
In this step, the gen function uses the LM to generate an answer 𝐴 to the user’s natural language request 𝑅, using the computed data 𝑇.
이 단계에서 gen 함수는 계산된 데이터 𝑇를 이용해 언어 모델을 통해 사용자 자연어 요청 𝑅에 대한 답변 𝐴를 생성합니다.
Figure 1 shows the final stage of the example TAG pipeline outputting a summary of the reviews on "Titanic" as the answer to the original user request.
그림 1은 예시 TAG 파이프라인의 마지막 단계로, "Titanic"에 대한 리뷰를 요약하여 원래 사용자 요청에 대한 답변으로 출력하는 모습을 보여줍니다.
In the example, the relevant data 𝑇 is encoded as a string for the model to process.
이 예시에서는 모델이 처리할 수 있도록 관련 데이터 𝑇를 문자열로 인코딩합니다.
The encoded table is passed to the LM along with the original user request, 𝑅.
인코딩된 테이블은 원래의 사용자 요청 𝑅과 함께 언어 모델에 전달됩니다.
To obtain the answer, this step leverages the model’s semantic reasoning capabilities over the review column to summarize the reviews.
답변을 생성하기 위해, 이 단계는 리뷰 열에 대해 언어 모델의 의미적 추론 능력을 활용하여 리뷰를 요약합니다.
3 TAG DESIGN SPACE
In this section, we explore the generality of the TAG model and describe the rich design space it produces, highlighting several under-studied opportunities for further research.
이 섹션에서는 TAG 모델의 범용성을 탐색하고, 이로부터 파생되는 풍부한 설계 공간을 설명하며, 추가 연구가 필요한 여러 미개척 기회를 강조합니다.
Query Types
질의 유형
The TAG model is expressive enough to serve a broad range of natural language user queries.
TAG 모델은 다양한 자연어 사용자 질의에 대응할 수 있을 만큼 표현력이 풍부합니다.
We consider two important query categorizations, according to (a) the level of data aggregation required to answer the query and (b) the knowledge and capabilities needed for answering the query.
우리는 (a) 질의 응답에 필요한 데이터 집계 수준과 (b) 질의 응답에 요구되는 지식 및 기능을 기준으로 두 가지 주요 질의 분류를 고려합니다.
First, the TAG model captures both point queries, such as retrieval-based questions [3, 9, 15, 16, 25, 30] which require look-ups to one or a few rows of the database,
첫째, TAG 모델은 한두 개의 행만 조회하는 retrieval 기반 질문과 같은 포인트 질의뿐만 아니라,
as well as aggregation queries, such as summarization or ranking-based questions which require logical reasoning across many rows of the database.
다수의 행에 걸친 논리적 추론이 필요한 요약 또는 순위 기반 질문과 같은 집계 질의도 포괄합니다.
Secondly, the TAG model enables natural language queries with varying demands on the system to provide data or reasoning-based capabilities, including for tasks such as sentiment analysis and classification.
둘째, TAG 모델은 감성 분석이나 분류 같은 작업을 포함하여 데이터 처리 또는 추론 기능이 다양한 수준으로 요구되는 자연어 질의에도 대응할 수 있습니다.
Data Model
데이터 모델
The underlying data model can take many forms.
기본 데이터 모델은 다양한 형태를 가질 수 있습니다.
Our implementation uses relational databases to store and retrieve structured attributes for knowledge-grounding in the downstream question-answering task.
우리 구현에서는 관계형 데이터베이스를 사용하여 구조화된 속성을 저장 및 조회함으로써, 질문 응답 작업에서 지식을 기반으로 삼습니다.
Others may operate on more unstructured data (e.g., free-text, images, video, and audio) or semi-structured data,
다른 시스템은 비정형 데이터(예: 자유 텍스트, 이미지, 비디오, 오디오) 또는 반정형 데이터를 사용할 수 있으며,
which may be stored with a variety of data models, such as key-value, graph, vector, document, or object stores.
이러한 데이터는 키-값, 그래프, 벡터, 문서, 오브젝트 저장소 등 다양한 데이터 모델로 저장될 수 있습니다.
Database Execution Engine and API
데이터베이스 실행 엔진 및 API
The underlying system used to store the data can use many possible database execution engines.
데이터를 저장하는 기본 시스템은 다양한 데이터베이스 실행 엔진을 사용할 수 있습니다.
Text2SQL considers the setting of an SQL-based query engine for retrieving relational data for user queries.
Text2SQL은 관계형 데이터를 검색하기 위한 SQL 기반 쿼리 엔진 환경을 고려합니다.
In this setting, syn will leverage the knowledge of the data source, such as the table schema, and return a SQL query to perform the retrieval step.
이 환경에서 syn은 테이블 스키마와 같은 데이터 소스의 지식을 활용하여 검색용 SQL 쿼리를 생성합니다.
In another common setting, retrieval systems over vector embeddings, syn transforms the natural language query into an embedding and exec performs similarity-based retrieval over the vector store.
다른 일반적인 환경에서는 벡터 임베딩 기반 검색 시스템을 사용하며, syn은 자연어 질의를 임베딩으로 변환하고 exec는 벡터 저장소에서 유사도 기반 검색을 수행합니다.
While these two settings have been widely studied, several under-studied alternative settings present interesting opportunities for efficiently implementing TAG systems to serve a broader range of queries.
이 두 환경은 널리 연구되었지만, 몇 가지 미개척된 대안적 환경은 더 넓은 범위의 질의에 대응할 수 있는 효율적인 TAG 시스템 구현의 기회를 제공합니다.
For instance, recent works augment relational models with semantic operators [21],
예를 들어, 최근 연구에서는 관계형 모델에 의미 기반 연산자 [21]를 추가합니다.
which provide a set of declarative AI-based operators (e.g., filtering, ranking, aggregating, and performing search with natural language specifiers) or LM user-defined functions [19],
이 연산자는 선언형 AI 기반 필터링, 정렬, 집계, 자연어 조건을 통한 검색 등의 기능이나, 언어 모델 사용자 정의 함수(LM UDF) [19] 등을 제공합니다.
which provide a general-purpose LM function.
이는 범용 언어 모델 기능을 구현합니다.
Additionally, query languages like MADLib [10], Google’s BigQuery ML [1], and Microsoft’s Predictive SQL [24] augment SQL-based APIs with native ML-based functions.
또한 MADLib [10], Google BigQuery ML [1], Microsoft Predictive SQL [24]과 같은 쿼리 언어는 ML 기반 기능을 SQL API에 통합합니다.
Leveraging these systems provides unique opportunities for executing optimized reasoning-based retrieval patterns.
이러한 시스템을 활용하면 최적화된 추론 기반 검색 패턴을 실행할 수 있는 독특한 기회를 제공합니다.
For instance, in the example shown in Figure 1, a TAG pipeline implemented with semantic operators [21] might use a sem_filter operator to filter rows based on whether they are a 'classic' during the query execution step.
예를 들어, 그림 1의 사례에서 TAG 파이프라인은 sem_filter 연산자를 사용하여 쿼리 실행 단계에서 ‘클래식’ 영화인지에 따라 행을 필터링할 수 있습니다.
LM Generation Patterns
언어 모델 생성 패턴
Given the table 𝑇 of relevant data, gen can be comprised from a vast array of implementation decisions to produce the final natural language answer 𝐴 in response to the user request 𝑅.
관련 데이터 테이블 𝑇가 주어지면, gen은 다양한 구현 방식을 통해 사용자 요청 𝑅에 대한 최종 자연어 답변 𝐴를 생성할 수 있습니다.
While Text2SQL omits the final generation step and stops short after query execution,
Text2SQL은 최종 생성 단계를 생략하고 쿼리 실행 이후에는 멈춥니다.
RAG pipelines typically leverage a single LM-call generation implementation where relevant data is fed in context.
RAG 파이프라인은 관련 데이터를 문맥에 넣어 하나의 LM 호출로 답변을 생성하는 방식을 사용합니다.
In this setting, several works study sub-problems related to table encoding [8], prompt compression [5], and prompt tuning [13] to optimize the in-context learning results.
이 환경에서는 테이블 인코딩 [8], 프롬프트 압축 [5], 프롬프트 튜닝 [13] 등 문맥 학습 성능을 최적화하기 위한 다양한 세부 문제가 연구되고 있습니다.
More recent research, such as LOTUS [21], highlights the potential of composing iterative or recursive LM generation patterns for answering queries involving reasoning-based transformations, aggregations, or rankings across multiple data rows.
LOTUS [21]와 같은 최근 연구는 여러 행에 걸친 추론 기반 변환, 집계, 순위 매김 질의를 처리하기 위해 반복적 또는 재귀적 LM 생성 패턴을 구성하는 가능성을 보여줍니다.
Early work demonstrates the rich design space presented by these LM-based algorithms and promising results on several downstream tasks.
초기 연구들은 이러한 LM 기반 알고리즘의 풍부한 설계 가능성과 여러 다운스트림 작업에서의 유망한 성과를 보여줍니다.
4 EVALUATION
In this section, we introduce the first TAG benchmark and evaluate a collection of baselines, aiming to address the following questions:
이 섹션에서는 최초의 TAG 벤치마크를 소개하고 여러 기준 모델을 평가하여 다음 질문에 답하고자 합니다:
(1) How do existing methods for table question answering perform on queries requiring semantic reasoning or world knowledge?
(1) 의미 추론 또는 세계 지식이 필요한 질의에 대해 기존 테이블 질의응답 방법들은 어떻게 성능을 보이는가?
(2) How does a hand-written implementation of the TAG model, which divides computational and reasoning steps across DBMS and LM operations, perform on these queries?
(2) 계산과 추론 단계를 DBMS와 언어 모델로 분리한 수작업 TAG 모델 구현은 이러한 질의에 대해 어떤 성능을 보이는가?
4.1 Benchmark Methodology
4.1 벤치마크 방법론
Existing benchmarks have explored how models perform on basic queries answerable entirely from data in the data source.
기존 벤치마크들은 데이터 소스 내의 정보만으로 답변 가능한 기본 질의에 대한 모델 성능을 평가해왔습니다.
We build upon prior work by modifying queries such that they require knowledge not directly available in the data source or semantic reasoning to answer.
우리는 기존 작업을 바탕으로 질의를 수정하여, 데이터 소스에 직접 존재하지 않는 지식이나 의미적 추론이 필요한 형태로 만듭니다.
We select BIRD [17], a widely used Text2SQL benchmark on which LMs have been evaluated, for its large scale tables along with its variety of domains and query types.
우리는 대규모 테이블과 다양한 도메인 및 질의 유형을 포함하는, 널리 사용되는 Text2SQL 벤치마크인 BIRD [17]를 선택했습니다.
Dataset
데이터셋
Our queries span 5 domains selected from BIRD, each containing diversity in query types.
우리가 사용하는 질의는 BIRD에서 선택된 5개의 도메인에 걸쳐 있으며, 각각 다양한 질의 유형을 포함하고 있습니다.
We select california_schools, debit_card_specializing, formula_1, codebase_community, and european_football_2 as the DB sources for our queries.
우리는 california_schools, debit_card_specializing, formula_1, codebase_community, european_football_2를 질의의 데이터베이스 소스로 선택했습니다.
Queries
질의
The BIRD benchmark defines fundamental query types, including match-based, comparison, ranking, and aggregation queries.
BIRD 벤치마크는 매칭 기반, 비교, 순위, 집계 등 기본적인 질의 유형들을 정의합니다.
We select queries among these types from the BIRD benchmark and modify them to require either world knowledge or semantic reasoning for the model to answer.
우리는 이러한 유형의 질의 중 일부를 선택하고, 모델이 세계 지식 또는 의미 추론을 필요로 하도록 수정합니다.
As an example of a modified query requiring world knowledge, in the california_schools DB, a modified query adds an additional clause asking for only schools in the Bay Area.
예를 들어, california_schools DB에서 수정된 질의는 "Bay Area에 위치한 학교"만을 요구하는 조건을 추가합니다.
This information is not in the table and requires the model’s world knowledge to answer.
이 정보는 테이블에 존재하지 않으며, 모델의 세계 지식이 필요합니다.
Next, a modified query requiring LM reasoning asks for the top 3 most sarcastic comments on a particular post in the codebase_community DB.
다음으로, codebase_community DB에서 언어 모델의 추론이 필요한 질의는 특정 게시물에 대한 가장 냉소적인 댓글 상위 3개를 요청합니다.
For evaluation on these queries, we rely on human-labeled ground truth.
이러한 질의에 대한 평가를 위해 사람에 의해 레이블링된 정답을 사용합니다.
Our final benchmark consists of 80 modified queries, 40 requiring parametric knowledge and 40 requiring reasoning, with 20 of each of the 4 chosen BIRD query types.
최종 벤치마크는 80개의 수정된 질의로 구성되며, 그 중 40개는 파라메트릭 지식이, 40개는 추론이 필요하고, 각 BIRD 질의 유형당 20개씩 포함됩니다.
Evaluation metrics
평가지표
We measure accuracy as the percentage of exact matches as compared to the labeled correct answer for the match-based, comparison, and ranking query types.
정확도는 매칭 기반, 비교, 순위 질의에 대해 레이블된 정답과 정확히 일치하는 비율로 측정됩니다.
For aggregation queries, we provide qualitative analysis on results using each baseline.
집계 질의에 대해서는 각 기준 모델 결과에 대한 정성적 분석을 제공합니다.
We also measure execution time in seconds for each query.
또한 각 질의별 실행 시간을 초 단위로 측정합니다.
Experimental setup
실험 환경
We use the instruction tuned variant of Meta’s Llama-3.1 model [2] with 70B parameters as our LM for both Text2SQL and final output generation.
Text2SQL과 최종 응답 생성을 위한 언어 모델로, Meta의 Llama-3.1 모델 (70B 파라미터)의 인스트럭션 튜닝 버전을 사용합니다.
We use SQLite3 as our database API for baselines involving SQL and use an E5 base embedding model [23] for our RAG baseline.
SQL 관련 기준 모델에는 SQLite3를, RAG 기준에는 E5 임베딩 모델 [23]을 사용합니다.
We run Llama-3.1-70B-Instruct with vLLM [14] on 8 A100 80GB GPUs.
Llama-3.1-70B-Instruct는 vLLM [14]과 함께 A100 80GB GPU 8개에서 실행됩니다.
4.2 Baselines
Text2SQL
Text2SQL 기준
In this baseline, the LM generates SQL code which is run to obtain an answer.
이 기준 모델에서는 언어 모델이 SQL 코드를 생성하고 이를 실행하여 답을 얻습니다.
For a given NL query, we construct an LM prompt containing table schemas for every table in the query’s domain, using the same prompt format as in the BIRD work.
자연어 질의에 대해, 해당 도메인의 테이블 스키마를 포함하는 프롬프트를 구성하며, 이는 BIRD 작업과 동일한 형식을 사용합니다.
We evaluate this baseline executing the generated SQL code in SQLite3 and measuring the number of incorrect answers, including instances where the model fails to generate valid SQL code.
생성된 SQL을 SQLite3에서 실행하고, 잘못된 SQL 생성 포함하여 틀린 답변 수를 측정하여 성능을 평가합니다.
Retrieval Augmented Generation (RAG)
검색 기반 생성 (RAG)
RAG style methods have been explored for table retrieval [6, 25], where tabular data is embedded into an index for search.
RAG 방식은 테이블 검색용으로 탐색되어 왔으며 [6, 25], 테이블 데이터를 임베딩하여 인덱스 기반으로 검색합니다.
For our baseline, we use row-level embeddings.
우리 기준 모델에서는 행 단위 임베딩을 사용합니다.
A given row is serialized as "- col: val" for each column before being embedded into a FAISS [7] index.
각 행은 "- col: val" 형태로 직렬화된 후 FAISS [7] 인덱스로 임베딩됩니다.
During query time, we perform vector similarity search to retrieve 10 relevant rows to feed in context to our model along with the NL question.
질의 시점에 벡터 유사도 검색을 수행하여 관련된 행 10개를 모델에 문맥으로 입력합니다.
Retrieval + LM Rank
검색 + 언어 모델 재정렬
We extend the RAG baseline by utilizing an LM to assign a score between 0 and 1 for retrieved rows to rerank rows before input to the model, as is done in the STaRK work [25].
RAG 기준을 확장하여, 검색된 행에 대해 0~1 사이의 점수를 부여하고 이를 재정렬하는 언어 모델을 사용합니다(STaRK 방식 [25] 참고).
We use Llama-3.1-70B-Instruct as our reranker.
재정렬 모델로 Llama-3.1-70B-Instruct를 사용합니다.
Text2SQL + LM
Text2SQL + 언어 모델
In this baseline, our model is first asked to generate SQL to retrieve a set of relevant rows to answer a given NL query.
이 모델에서는 먼저 SQL을 생성하여 관련된 행을 검색하도록 합니다.
This is an important distinction from the Text2SQL baseline, where the model is asked to directly generate SQL code that alone provides an answer to the query when executed.
이는 SQL 자체가 정답을 제공하는 Text2SQL 기준과 달리, 관련 행을 먼저 추출한 후 추가 처리를 요구하는 방식입니다.
Similar to the RAG baseline, relevant rows are fed in context to the model once retrieved.
RAG 기준처럼, 검색된 관련 행을 모델에 문맥으로 제공합니다.
Hand-written TAG
수작업 TAG 파이프라인
We also evaluate hand-written TAG pipelines, which leverage expert knowledge of the table schema rather than automatic query synthesis from the natural language request to the database query.
우리는 전문가가 테이블 스키마 지식을 활용하여 직접 구현한 TAG 파이프라인도 평가합니다. 이 방법은 자연어 요청에서 데이터베이스 쿼리로의 자동 변환을 사용하지 않습니다.
We implement our hand-written TAG pipelines with LOTUS [21].
이 수작업 TAG 파이프라인은 LOTUS [21]을 사용해 구현합니다.
The LOTUS API allows programmers to declaratively specify query pipelines with standard relational operators as well as semantic operators, such as LM-based filtering, ranking, and aggregations.
LOTUS API는 프로그래머가 관계 연산자뿐 아니라 LM 기반 필터링, 정렬, 집계 같은 의미 연산자를 선언형으로 지정할 수 있도록 합니다.
LOTUS also provides an optimized semantic query execution engine, which we use to implement the query execution and answer generation steps of our hand-written TAG pipelines.
LOTUS는 최적화된 의미 기반 질의 실행 엔진도 제공하며, 이를 사용해 쿼리 실행 및 응답 생성 단계를 구현합니다.
4.3 Results
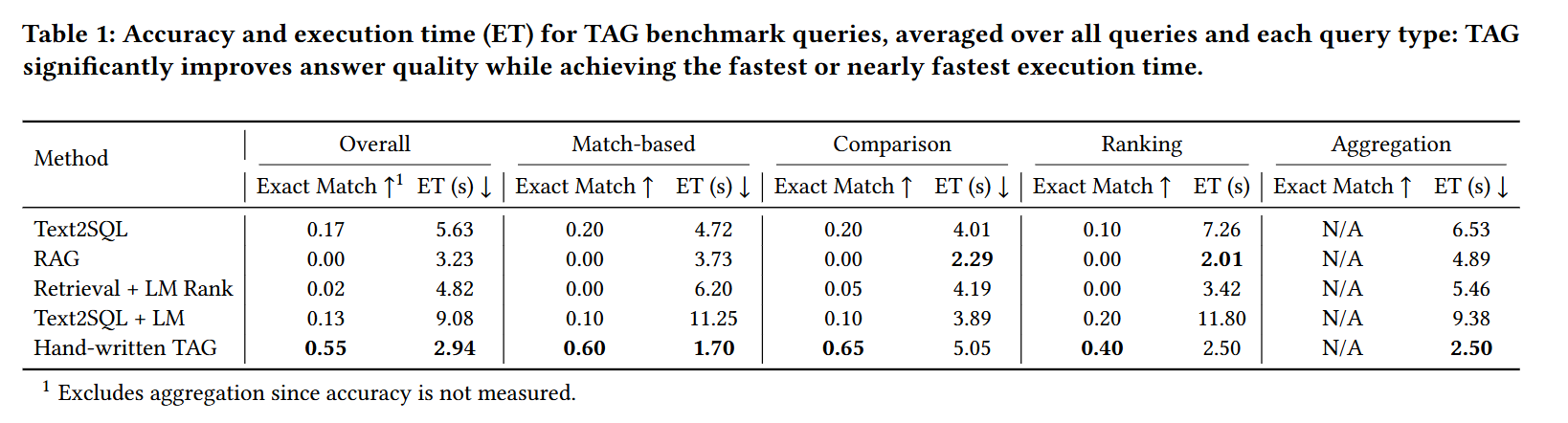

Table 1 shows the accuracy, measured by exact match, and execution time of each method.
표 1은 각 방법의 정확 일치 기반 정확도와 실행 시간을 보여줍니다.
As the table shows, across the selected BIRD query types, we find that our hand-written TAG baseline consistently achieves 40% exact match accuracy or better, where all other baselines fail to exceed 20% accuracy.
표에서 보이듯이, 선택된 BIRD 질의 유형 전반에서 수작업 TAG 기준 모델은 항상 40% 이상의 정확 일치 정확도를 달성하는 반면, 다른 기준 모델은 모두 20%를 넘지 못합니다.
The Text2SQL baseline performs poorly on all baselines with an execution accuracy no higher than 20% but especially poorly on ranking queries with only 10% accuracy, as many of the ranking queries require reasoning over text.
Text2SQL 기준 모델은 전반적으로 20% 이하의 낮은 정확도를 보이며, 특히 텍스트 기반 추론이 필요한 순위 질의에서는 정확도가 10%에 불과합니다.
The Text2SQL + LM generation baseline has similar poor performance across baselines, but does worse on match-based and comparison queries with only 10% accuracy.
Text2SQL + LM 생성 기준 역시 성능이 낮으며, 매칭 및 비교 질의에서는 정확도가 10%에 그쳐 더욱 부진합니다.
On these query types, several context length errors occur trying to feed in many rows to the model after the executed SQL.
이러한 질의 유형에서는 SQL 실행 후 다수의 행을 모델에 입력하려 할 때 문맥 길이 초과 오류가 발생합니다.
Turning our attention to the RAG baseline, we see that it fails to answer a single query correctly across all query types, highlighting its poor fit for queries in this space.
RAG 기준 모델은 모든 질의 유형에서 단 하나의 질의도 정확히 응답하지 못해, 이 환경에 적합하지 않음을 보여줍니다.
Adding LM reranking allows Retrieval + LM rank to answer a query correctly among the comparison queries, however the baseline still performs worse than all others besides RAG.
LM 기반 재정렬을 추가한 Retrieval + LM rank는 비교 질의에서 하나의 정답을 맞히지만, 여전히 RAG을 제외한 다른 기준 모델보다 낮은 성능을 보입니다.
Our hand-written TAG baseline answers 55% of queries correctly overall, performing best on comparison queries with an exact match accuracy of 65%.
수작업 TAG 기준 모델은 전체 질의의 55%에 정확히 응답하였으며, 비교 질의에서 특히 뛰어나 65%의 정확도를 기록했습니다.
The baseline performs consistently well with over 50% accuracy on all query types except ranking queries, due to the higher difficulty in ordering items exactly.
이 기준 모델은 순위 질의를 제외한 모든 유형에서 50% 이상의 성능을 보이며, 순위 질의는 정확한 정렬이 어려워 성능이 다소 낮습니다.
Overall, this method gives us between a 20% to 65% accuracy improvement over the standard baselines.
전반적으로 이 방식은 기존 기준 모델 대비 20%에서 65%까지 정확도 향상을 이끌어냈습니다.
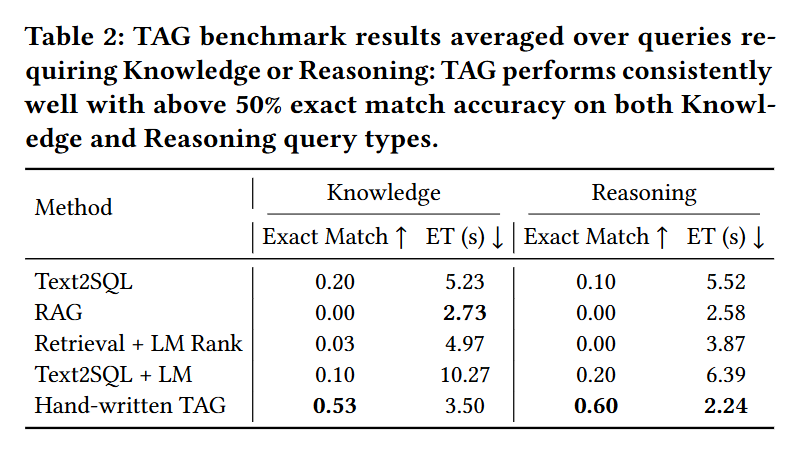
Additionally, Table 2 highlights the weaknesses of standard methods in answering the query types discussed in Section 3.
또한 표 2는 3장에서 논의된 질의 유형에 대한 기존 방법들의 한계를 강조합니다.
Namely, vanilla Text2SQL especially struggles on queries requiring LM reasoning with 10% exact match accuracy, due to its omission of the answer generation step.
즉, Text2SQL은 응답 생성 단계를 생략하기 때문에 LM 추론이 필요한 질의에서 정확도가 10%에 불과하며 특히 성능이 낮습니다.
Meanwhile, the RAG baseline and Retrieval + LM Rank baseline struggle on all query types, answering only one query correctly, due to their reliance on the LM to handle all exact computation over data.
반면, RAG 및 Retrieval + LM Rank 기준 모델은 데이터 계산 전반을 언어 모델에 의존하여 모든 질의 유형에서 부진하며 단 하나의 질의만 맞췄습니다.
In contrast, the hand-written TAG baseline achieves over 50% accuracy on both queries requiring knowledge and queries requiring reasoning, emphasizing the TAG model’s versatility in the queries it encapsulates.
반면, 수작업 TAG 기준 모델은 지식 기반 질의와 추론 기반 질의 모두에서 50% 이상의 정확도를 달성하여 TAG 모델의 범용성을 보여줍니다.
Notably, along with offering superior accuracy, the hand-written TAG method offers an efficient implementation with up to 3.1× lower execution time over other baselines.
특히, 수작업 TAG 방식은 높은 정확도와 함께 최대 3.1배 더 빠른 실행 시간으로 효율성도 제공합니다.
The hand-written baseline takes an average of 2.94 seconds for all queries.
이 기준 모델은 모든 질의에 대해 평균 2.94초가 소요됩니다.
This relatively low execution time highlights that an efficient TAG system can be designed by exploiting efficient batched inference of LMs.
이러한 낮은 실행 시간은 언어 모델의 배치 추론을 활용하여 효율적인 TAG 시스템을 설계할 수 있음을 보여줍니다.
Lastly, we qualitatively analyze the results of each baseline on aggregation queries.
마지막으로, 우리는 각 기준 모델의 집계 질의에 대한 결과를 정성적으로 분석합니다.
Figure 2 shows the results for the RAG, Naive TAG, and hand-written baselines on the example query "Provide information about the races held on Sepang International Circuit."
그림 2는 “Sepang International Circuit에서 열린 레이스에 대한 정보를 제공하라”는 예시 질의에 대한 RAG, 단순 TAG, 수작업 TAG 기준 모델의 결과를 보여줍니다.
The RAG baseline is only able to provide information about some of the races, as most of the relevant races are not retrieved.
RAG 기준 모델은 관련된 레이스 대부분을 검색하지 못해 일부 정보만을 제공합니다.
On the other hand, the Text2SQL + LM baseline is not able to utilize any information from the DBMS, relying only on parametric knowledge and providing no further analysis.
반면, Text2SQL + LM 기준 모델은 DBMS 정보를 활용하지 못하고 파라메트릭 지식에만 의존해 추가 분석 없이 응답합니다.
The hand-written baseline provides a thorough summary of all the races from 1999 to 2017 held at Sepang International Circuit.
수작업 기준 모델은 Sepang에서 열린 1999년부터 2017년까지의 모든 레이스에 대한 상세 요약을 제공합니다.
We observe a similar trend across other aggregation queries provided by the benchmark,
다른 벤치마크 집계 질의에서도 유사한 경향이 관찰됩니다.
with initial results highlighting the potential of TAG systems to successfully aggregate large amounts of data to provide informative answers.
초기 결과는 TAG 시스템이 방대한 데이터를 성공적으로 집계하여 유익한 응답을 제공할 가능성을 보여줍니다.
We leave quantitative analysis to future work.
정량적 분석은 향후 연구로 남겨두었습니다.
5 RELATED WORK
Text2SQL using LMs has been extensively explored in prior work.
언어 모델을 활용한 Text2SQL은 이전 연구에서 광범위하게 탐구되었습니다.
WikiSQL [33], Spider [29], and BIRD [17] are all popular datasets for cross-domain Text2SQL.
WikiSQL [33], Spider [29], BIRD [17]는 도메인 간 Text2SQL을 위한 대표적인 데이터셋입니다.
These datasets contain structured data across many domains on which the task of converting natural language queries to SQL is evaluated.
이들 데이터셋은 다양한 도메인의 구조화된 데이터를 포함하고 있으며, 자연어 질의를 SQL로 변환하는 과제를 평가합니다.
However, this direction does not utilize model capabilities beyond SQL generation,
하지만 이러한 방향은 SQL 생성 이상의 모델 기능은 활용하지 않으며,
keeping queries that require reasoning or knowledge beyond a static data source out of scope.
정적 데이터 소스를 넘어서는 추론이나 지식을 요구하는 질의는 다루지 않습니다.
Retrieval-Augmented Generation (RAG) has been applied to extend knowledge to large collections of text.
RAG(검색 기반 생성)은 대규모 텍스트 집합에 지식을 확장하는 데 활용되었습니다.
SQuAD [22] and HotPotQA [27] focus on question-answering over single document and multiple document sources respectively.
SQuAD [22]는 단일 문서 기반, HotPotQA [27]는 다중 문서 기반 질문 응답을 다룹니다.
The DTR (Dense Table Retrieval) model [11] extends RAG to tabular data,
DTR 모델 [11]은 RAG를 표 형태의 데이터로 확장하며,
embedding tabular context to retrieve relevant cells and rows for a query.
질의에 관련된 셀과 행을 검색할 수 있도록 테이블 문맥을 임베딩합니다.
Join-aware table retrieval [6] adds a table-table similarity score term to improve performance on complex queries involving joined tables.
Join-aware table retrieval [6]은 조인된 테이블이 포함된 복잡한 질의 성능 향상을 위해 테이블 간 유사도 점수를 추가합니다.
In contrast to prior RAG work, the TAG model encompasses a larger field of queries
기존 RAG 방식과 달리, TAG 모델은 더 넓은 범주의 질의를 포괄하며
by leveraging LM capabilities in the query execution step and allowing DBMS operations for exact computation over large amounts of data.
질의 실행 단계에서 언어 모델의 능력을 활용하고, 대량 데이터를 정확히 처리하기 위한 DBMS 연산을 허용합니다.
NL Queries over Semi-structured Data
반정형 데이터에 대한 자연어 질의
Prior work has explored the relational information between table entities and unstructured entity fields in semi-structured data sources.
이전 연구에서는 반정형 데이터에서 테이블 엔터티와 비정형 엔터티 필드 간의 관계 정보를 탐구했습니다.
STaRK [25] evaluates table retrieval methods across semi-structured knowledge bases (SKBs), including both structural and nonstructural information.
STaRK [25]는 구조적/비구조적 정보를 모두 포함한 반정형 지식 베이스(SKBs)에서 테이블 검색 기법을 평가합니다.
SUQL [20] addresses conversational search, using LMs as semantic parsers to handle unstructured query components over hybrid data.
SUQL [20]은 언어 모델을 의미 파서로 활용하여 혼합형 데이터에 대한 비정형 질의 요소를 처리하는 대화형 검색을 다룹니다.
While these works primarily focus on natural language search queries over semi-structured data,
이러한 연구는 대부분 반정형 데이터에 대한 자연어 검색 질의에 중점을 두지만,
we seek to explore a broader range of queries leveraging more LM capabilities for tasks beyond search and lookup.
우리는 검색과 조회를 넘어서는 과제에서 언어 모델의 더 많은 기능을 활용하는 폭넓은 질의를 탐색하고자 합니다.
Agentic Data Assistants
에이전트형 데이터 어시스턴트
Recent work has explored LM agents as data assistants [12].
최근에는 언어 모델 에이전트를 데이터 어시스턴트로 활용하는 연구도 진행되었습니다 [12].
Spider2-V [4] explores multimodal agent-based interaction.
Spider2-V [4]는 다중 모달 기반의 에이전트 인터랙션을 탐구합니다.
RAG also enables LMs to go beyond parametric performance in tasks involving code generation and GUI controls [16].
RAG는 코드 생성 및 GUI 제어 같은 과제에서 파라메트릭 성능을 넘어서는 언어 모델 활용을 가능하게 합니다 [16].
Though we define the TAG model tractably as one iteration of the syn, exec, and gen functions,
우리는 TAG 모델을 syn, exec, gen 세 단계의 단일 반복으로 정의했지만,
future work may explore extending this in an agentic loop.
향후 연구는 이를 에이전트 루프로 확장하는 방향을 탐색할 수 있습니다.
6 CONCLUSION
In this work we proposed table-augmented generation (TAG) as a unified model for answering natural language questions over databases.
본 연구에서는 데이터베이스 위의 자연어 질의 응답을 위한 통합 모델로 TAG(Table-Augmented Generation)을 제안했습니다.
We developed benchmarks to study two important types of queries: those that require world knowledge, and those that require semantic reasoning capabilities.
우리는 세계 지식 또는 의미 기반 추론 능력을 요구하는 두 가지 핵심 질의 유형을 다루기 위한 벤치마크를 개발했습니다.
Our systematic evaluation confirms that baseline methods are unable to make meaningful traction on these tasks.
체계적인 평가 결과, 기존 기준 모델은 이러한 과제에서 유의미한 성능을 보이지 못했습니다.
However, hand-written TAG pipelines can achieve up to 65% higher accuracy,
그러나 수작업 TAG 파이프라인은 최대 65%의 정확도 향상을 달성할 수 있었으며,
demonstrating substantial research opportunities for building TAG systems.
TAG 시스템 구축을 위한 상당한 연구 가능성을 입증했습니다.
7 ACKNOWLEDGEMENTS
This research was supported in past by affiliate members and supporters of the Stanford DAWN project and the Sky Computing Lab at Berkeley,
본 연구는 과거 Stanford DAWN 프로젝트 및 버클리 Sky Computing Lab의 후원과 참여 기관의 지원을 받았습니다.
including Accenture, AMD, Anyscale, Cisco, Google, IBM, Intel, Meta, Microsoft, Mohamed Bin Zayed University of AI, NVIDIA, Samsung SDS, SAP, VMware, and a Sloan Fellowship.
지원 기관으로는 Accenture, AMD, Anyscale, Cisco, Google, IBM, Intel, Meta, Microsoft, Mohamed Bin Zayed 인공지능대학, NVIDIA, 삼성 SDS, SAP, VMware, 그리고 Sloan Fellowship이 포함됩니다.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the sponsors.
이 논문에 표현된 견해, 발견, 결론, 권고는 모두 저자의 의견이며, 후원 기관의 입장을 반드시 반영하지는 않습니다.
