편향 VS 분산
편향(Bias) : 편향이 클수록 모델이 매우 단순화되어 지나치게 한 방향성으로 치우치게 된다.
분산(Variance) : 분산이 커지게 되면 학습 데이터 하나 하나의 특성을 반영하면서 매우 복잡한 모델이 되었지만, 학습 데이터에 대한 오차는 적지만, 그 외의 데이터에 대한 지나치게 높은 변동성을 가지게 된다.
일반적으로 편향과 분산은 한쪽이 높으면 한쪽이 낮아는 Trade off 경향을 띈다.
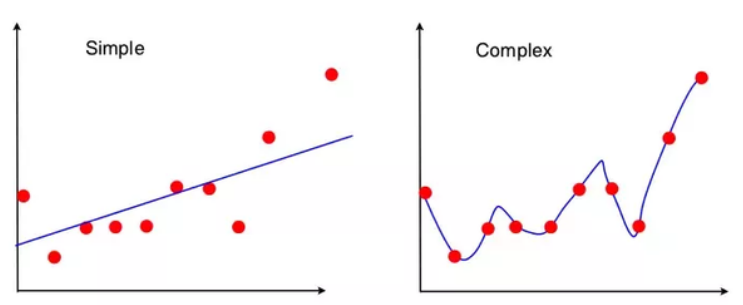
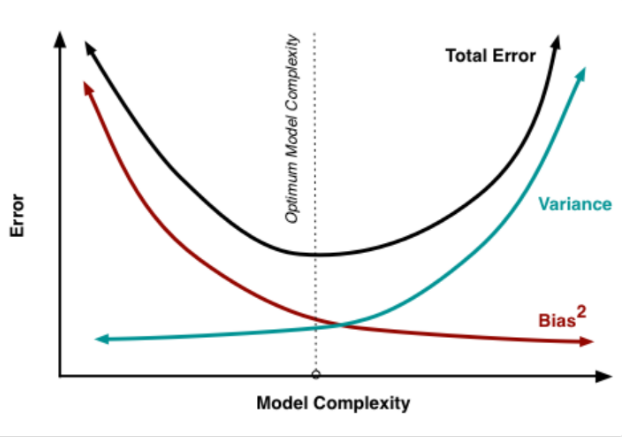
아래 그림은 편향과 분산의 관계에 따른 오차 값을 보여주는 그래프이다. 편향이 너무 높으면 전체 오류가 높게 되고, 편향을 낮추게 되면 분산이 높아지게 되고 전체적인 오류도 낮아지게 된다. 하지만 특정 이후 부터는 오류 값이 증가하면서 예측 성능이 다시 낮아지게 된다.
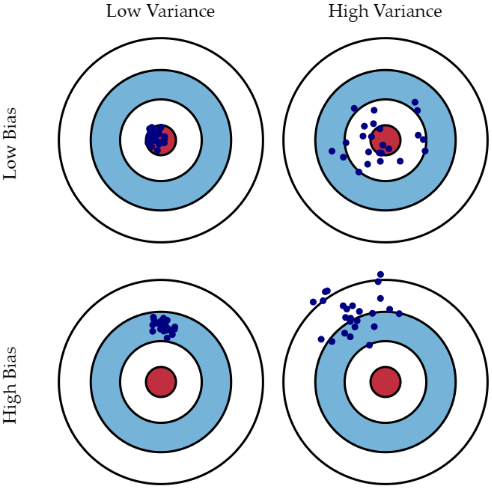
따라서 높은 편향/낮은 분산에서는 과소적합이 되기 쉬우며, 낮은 편향/높은 분산에서는 과적합 되기 쉽다. 그러므로 둘의 값을 적절하게 조절하면서 오류가 최대로 낮아지는 모델을 구축하는 것이 가장 효율적인 머신러닝 예측 모델을 만드는 방법이다.
규제 선형 모델 - 릿지, 라쏘, 엘사트틱넷
- 회귀 모델의 회귀 계수가 매우 크게 설정이 되면서 훈련 데이터에 대한 성능은 좋지만 변동성이 커지게 되어 평가 데이터에 대한 예측값은 낮아지게 된다. 따라서 회귀 모델은 회귀 계수가 기하급수적으로 커지는 것을 제어할 수 있어야 한다.
- 비용함수는 학습 데이터의 오류 값을 최소로 하면서도, 과적합을 방지하기 위해 회귀 계수값이 커지지 않도록 하는 방법이 서로 균형을 이루어야 한다.
- 회귀 계수 크기를 제어해 과적합을 개선하려면 비용 함수의 목표가 다음과 같이 LOSS(비용함수) + Alph*W를 최소화 하는 것으로 바뀌게 된다.
비용 함수 목표 = Min(RSS(W)+alpha∗∣∣W∣∣
수식 :
- 여기서 alpha는 학습 데이터 적합 정도와 회귀 계수 값의 크기를 제어하는 하이퍼파라미터 이다.
- alpha값을 크게 하면 비용함수는 회귀 계수 W값을 작게 해 과적합을 개선할 수 있으며, alpha값을 작게 하면 회귀 계수 W의 값이 커져도 어느 정도 상쇄가 가능하므로 학습데이터의 적합을 개선할 수 있다.
- 즉 alpha를 0에서부터 지속적으로 값을 증가시키면 회귀 계수 값의 크기를 감소시킬 수 있다. 이처럼 비용함수에 alpha 값으로 패널티를 부여해 회귀 계수 값의 크기를 감소시켜 과적합을 개선하는 방식을 규제(Regularization)이라고 부른다.
- 규제 방법에는 L2 , L1 방식이 있다.
- L2 규제는 와 같이 W의 제곱에 대해 패널티를 부여한다. 이런 방식을 라고 한다.
- L1 규제는 W의 절대값에 대해 패널티를 부여하고 이를 라쏘(Lasso)회귀라고 한다. L1 규제를 적용하면 영향력이 크지 않은 회귀 계수 값을 0으로 변환한다.
릿지 회귀, 라쏘 회귀
- alpha값이 커질수록 회귀 계수 값을 작게 만든다.
- L2 규제(릿지 회귀)가 회귀 계수의 크기를 감소시키는 데 반해, L1 규제는 불필요한 계수를 급격하게 감소시켜 0으로 만들고 제거한다. 이런 측면에서 L1 규제는 적절한 피처만 회귀에 포함시키는 특성을 가지고 있다.
L2 규제와 마찬가지고 alpha 하이퍼 파라미터를 통해 규제하게 된다.
엘라스틱넷 회귀
- L2규제와 L1규제를 결합한 회귀. 따라서 엘라스틱넷은
를 최소화 하는 W를 찾게 된다. - 라쏘 회귀가 서로 상관관계가 높은 피처들의 경우에 이들 중에서 중요 피처만을 선택하고 다른 피처회귀 계수를 0으로 만드는 성향이 강함. 특히 이러한 성향으로 인해 alpha 값에 따라 회귀 계수의 값이 급격히 변동할 수도 있는데, 엘라스틱넷 회귀는 이를 완화하기 위해 L2규제를 라쏘 회귀에 추가했다.
- 사이킷런은 ElasticNet 클래스를 통해 엘라스틱넷 회귀를 구현
- 주요 하이퍼 파라미터는 alpha와 L1_ratio 이다. 엘라스틱넷의 규제는 로 정의될 수 있으며 이때 a는 L1규제의 alpha값 , b는 L2규제의 alpha 값이다.
- 따라서 ElasticNet클래스의 alpha값은 a+b이고 L1_ratio파라미터는 a/(a+b)가 된다. 따라서 L1_ratio가 0이면 a가 0이므로 L2 규제와 동일 하고 1이면 b가 0이므로 L1규제와 동일하다.
선형 회귀 모델을 위한 데이터 변환
- 선형 회귀 모델과 같은 모델은 일반적으로 피처와 타깃값 간에 선형의 관계가 있다고 가정하고 이러한 최적의 선형함수를 찾아내 결과값을 예측한다.
- 또한 선형 회귀 모델은 피처값과 타깃값의 분포가 정규분포 형태를 매우 선호한다.
- 특히 타깃값의 경우 정규 분포 형태가 아니라 특정하게 치우친 형태의 분포도일 경우 예측 성능에 부정적인 영향을 미칠 가능성이 높다.
- 선형 회귀 모델을 적용하기 전에 먼저 데이터에 대한 스케일링/정규화 작업을 수행하는 것이 일반적이다.
- 일반적으로 중요 피처나 타깃값의 분포도가 심하게 왜곡되었을 경우 이러한 변환 작업을 한다. (MinMax , standardScaler , Log 변환)
- 원래 값에 Log 함수를 적용하면 보다 정규 분포에 가까운 형태로 값이 분포하게 된다. 이러한 변환을 로그 변환이라고한다.
- 실제로 선형 회귀에서는 로그 변환이 훨씬 많이 사용된다.
회귀 트리
-
일반적으로 선형회귀는 회귀 계수를 관계를 선형으로 가정하는 방법이다.
-
트리 기반은 회귀 함수를 기반으로 하지않고 결정 트리와 같이 트리 기반으로 회귀를 하게 된다.
-
분류에서의 트리와 유사하지만 예측 결정 값을 만드는 과정에 차이가 있다. 분류 트리가 특정 클래스 레이블을 결정하는 것과 달리 회귀 트리는 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측을 계산한다.
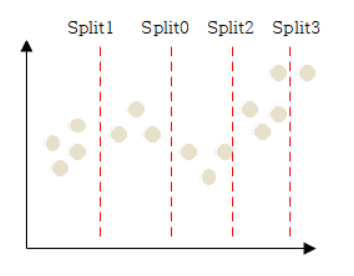
-
Split과 같이 트리 분할이 완료된 상태에서 리프 노드에 해당하는 데이터 값의 평균 값을 최종 리프 노드 값으로 사용하는 것이 바로 회귀 트리의 원리입니다.
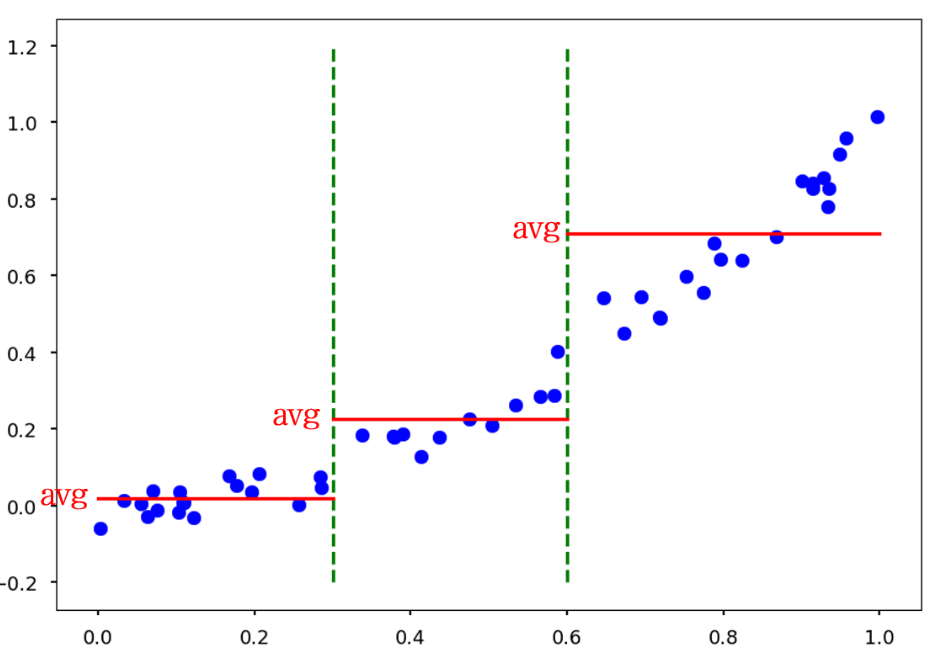
-
트리 회귀에는 결정트리 , 랜덤포레스트 , GBM , XGBoost , LightGBM등의 모든 트리 기반의 알고리즘은 분류뿐만 아니라 회귀도 가능하다.
-
사이킷런에서는 회귀 수행을 할 수 있는 Estimator 클래스를 제공한다.

-
회귀 들이 트리 클래스는 선형 회귀와 다른 처리 방식이므로 회귀 계수를 제공하는 coef 속성이 없지만 feature_importances 를 이용해 피처별 중요도를 알 수 있다.
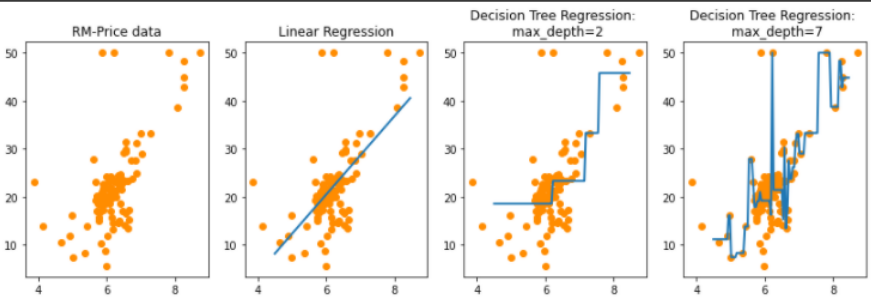
-
선형 회귀는 직선으로 예측 회귀선을 표현하는데 반해, 회귀 트리의 경우 분할되는 데이터 지점에 브랜치를 만들면서 계단 형태로 회귀선을 만든다.
