1. 결측치 제거
- pandas의 pd.dropna() 함수 이용
import pandas as pd
# create a sample dataframe with missing values
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [5, None, None, 8],
'C': [9, 10, 11, 12],
'D': [None, None, None, None]
})
# drop rows with missing values
df = df.dropna()output :
A B C D
0 1.0 5.0 9 NaN2. 결측치 채우기
pd.fillna() 함수 이용
- pd.fillna() 함수를 이용하여 결측치를 원하는 값으로 변경할 수 있음.
- 이때 변경할 수 있는 값으로는 아래와 같다.
- 최빈값 : 범주형에서 결측값이 발생시, 범주별 빈도가 가장 높은 값으로 변경
- 중앙값 : 숫자형(연속형)에서 결측값을 제외한 중앙값으로 대치방법
- 평균(mean) : 숫자형(연속형)에서 결측값제외한 평균으로 대치방법
- Similar case Imputation(조건부 대치)
- Generalized Imputation(회귀분석을 이용한 대치)
import pandas as pd
# create a sample dataframe with missing values
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [5, None, None, 8],
'C': [9, 10, 11, 12],
'D': [None, None, None, None]
})
# fill missing values with a default value
df = df.fillna(0)output :
A B C D
0 1.0 5.0 9 0
1 2.0 0.0 10 0
2 0.0 0.0 11 0
3 4.0 8.0 12 0 # 0으로 대체하기
df['col'] = df['col'].fillna(0)
# 컬럼의 평균으로 대체하기
df['B'] = df['B'].fillna(df['B'].mean()) # 결측치 이전값으로 채우기
df.fillna(method = 'pad')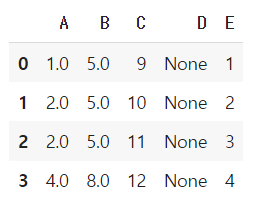
# 결측치 이후의 값으로 채우기
df.fillna(method = 'bfill')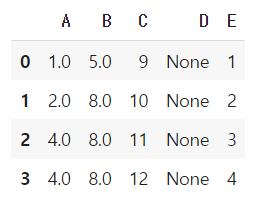
pd.interpolate 사용
- linear interpolation(선형 보간법) 방법으로 missing value를 채우는 방법
import pandas as pd
# create a sample DataFrame with missing values
df = pd.DataFrame({
'A': [1, 2, None, 4, None],
'B': [5, None, None, 8, 10],
'C': [9, 10, 11, None, 13],
})
# interpolate missing values using spline interpolation
df_interpolated = df.interpolate(method='spline', order=3)output :
A B C
0 1.000000 5.000000 9.000000
1 2.000000 4.867844 10.000000
2 2.821188 4.769428 11.106773
3 4.000000 8.000000 12.247345
4 4.430571 10.000000 13.000000