
- 전체보기(95)
- TIL(73)
- CS(20)
- js(20)
- 면접대비(20)
- JavaScript(18)
- elastic(17)
- elastic search(13)
- WIL(13)
- ESE(10)
- 자바스크립트(7)
- elasticsearch(5)
- Node(4)
- 혼자공부하는자바스크립트(4)
- 혼공스(4)
- ECE(4)
- express(3)
- https(2)
- 객체(2)
- k8s(2)
- 실행컨텍스트(2)
- CI/CD(2)
- github action(2)
- this(2)
- html(2)
- jest(2)
- github(2)
- watcher(2)
- Sequelize(1)
- ORM(1)
- node.js(1)
- API(1)
- 콜백함수(1)
- S.A(1)
- prisma(1)
- 1주차(1)
- 파이썬(1)
- Nginx(1)
- JavsScript(1)
- sql(1)
- 객체지향(1)
- ES(1)
- socket.io(1)
- 함수(1)
- nosql(1)
- 예외처리(1)
- 실전 프로젝트(1)
- Restful(1)
- typescript(1)
- Joi(1)
- 정규식(1)
- Elastic Stack(1)
- 알고리즘(1)
- 면접복기(1)
- 미니프로젝트(1)
- ts(1)
- 프로그래머스(1)
elasticsearch watcher 신규 이벤트마다 webhook 발생
쿠버네티스 환경에서 엘라스틱서치 싱글노드 띄우기
elasticsearch shard rebalancing
Header 해당 문서는 아래 공식 문서를 정리한 내용임 https://www.elastic.co/guide/en/elasticsearch/reference/7.16/modules-cluster.html 샤드 리밸런싱 클러스터의 어느 노드에도 샤드가 몰려있지 않고
[230515] ECE 기출 2회
작성 후 날리는 쿼리문에서, index를 생성만 한다고 치면 PUT이 맞는데, 생성과 동시에 데이터를 인덱싱 하려면 POST가 맞지 않나 의문또, 따로 타입을 지정하라는 요구사항이 없는데 mapping을 내가 작성해두는게 맞을지?mapping은 source index
[230510] Elastic Certificated Engineer Practice Exam 복습
설정한 role과 user는 어떻게 테스트 할 수 있는지 질문할 것user 생성 시, role을 여러 개 선택할 수 있는 것 같던데 선택한 role 사이에 권한이 충돌하면 어떻게 되는지?task1_role : 문제 조건에 맞는 role 설정task1 이외의 모든 인덱스
[230509] practice exam 1
조건에 맞추어 User와 Role 설정하는 문제lab에서 실습하지 않은 내용이지만, 키바나 잘 확인하면 무리 없이 작성 가능query를 사용해 범위를 좁히고, 중첩 구조의 aggregation을 진행하는 문제lab에서 진행하던 것과 상황 설정만 다를 뿐, 거의 같음dy
[230508] module 5~8 복습
5.2장 solution 5번runtime이라고 이름을 붙인 aggregation의 결과를 보면, runtime 내에 values가 있고, 또 이 내부에 50.0과 그 결과가 있는 구조임이 결과를 활용해서 정렬을 진행하는 것이 문제의 핵심인데, request를 보면 r
[230504] module 1~4 복습
highlight내에서 pre_tags, post_tags로 사용할 태그를 지정할 수 있음\[]로 감싸져 있어서 여러 개의 태그를 담을 수 있을 것이라고 생각했고, 아래처럼 작성해봄그런데 여전히 결과는 <strong>, </strong> 태그로만 감싸져 나오
[230503] module 5~8 복습
constant keyword 필드를 data stream 인덱스에 설정해두면 rollover 될 때마다 가장 처음 들어오는 document에 의해 그 값이 결정됨default로 rollover 되어도 같은 값을 유지하게 할 수 있음\-> 모든 인덱스가 같은 값을 가진
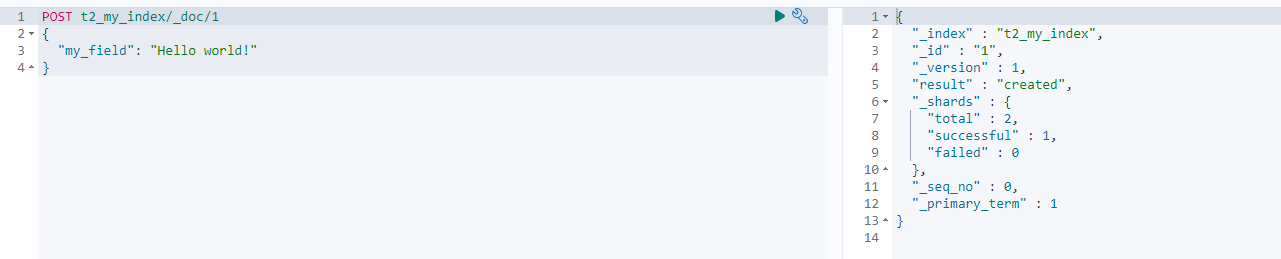
[230502] module 1~4 복습
1.2장 solution2번답안에는 PUT으로 되어있는데, POST로 작성해도 문제 없이 돌아가긴 함t2_my_index에서 자료를 보면 하나밖에 안 들어있는데, Index Management 메뉴에서 보면 document가 2개로 뜸하나는 뭘까?blogs 인덱스도 자

[230428] module 7,8 실습 기록
aliases 실습 과정 중에서 궁금한 점이 생겼다.위 코드를 순서대로 실행하면, 현재 write 설정된 인덱스는 2초간만 유효하기 때문에 바로 다음 넘버링 인덱스가 생성된다.그런데 이 설정이 계속 유지되는 건 아닌지 다음 넘버링이 나는 2초마다 생길 줄 알았는데, 한
[230426] module 5~6 실습 기록
5.3의 5번 solutionmoving_fn이 어떤 역할을 하는지 잘 모르겠음6.1의 7번 solution=> node 3번이 보이지 않음primary 1, 2번이 각각 node1, node2에 배치된것은 확인했는데,replicas는 왜 모두 unassigned인지
[230425] module 3~4 실습 기록
\_source는 따로 설정해주지 않으면 default로 원본 자료의 모든 필드가 이 안에 담겨서 출력"\_source": \["필드명", ...]으로 어떤 필드만 담을지 선택할 수도 있음"\_source": false로 설정하면 해당하는 document의 인덱스 명과
[230424] module 1~2 실습 기록
mapping에서 분석기 만들어놓고, 필드 타입이랑 분석기를 지정해 줬는데도 document를 넣으면 keyword랑 다를 바 없이 "We love X-Pack"가 그대로 저장되는 것을 확인=> 우리한테 보여줄 때에는 그렇게 보이고, analysis는 내부적으로 실행되
[230420] Elastic Stack 3일차 리뷰 내용
개념 추가 클러스터, 노드는 논리적인 개념이지 물리적인 개념이 아님 한 서버에 노드를 여러 개 올릴 수 있지만 서버 스펙이 좋아도 하나만 올릴 것이 권장됨 => 디스크를 공유하는 데에 있어서 속도가 영향을 받음 Shard 샤드는 Lucene의 한 인스턴스이다 = 샤드
[230419] Elastic Stack 2일차 리뷰 내용
Async search 오래 걸리는 query나 aggregation에 대해 진행 상황을 모니터링 하거나 부분적인 결과 상황을 확인할 때 사용
[230418] Elastic Stack 1일차 리뷰 내용
Elastic Search는 검색, 분석을 위한 엔진맨 꼭대기에 있는 cluster, 그 아래로 각 실행흐름인 node, 그 아래 RDB의 테이블과 비슷한 개념으로 생각할 수 있는 index가 존재클러스터는 여러 개가 존재할 수 있으며, 각 클러스터가 논리적으로 분리됨