1.2장 solution2번
답안에는 PUT으로 되어있는데, POST로 작성해도 문제 없이 돌아가긴 함
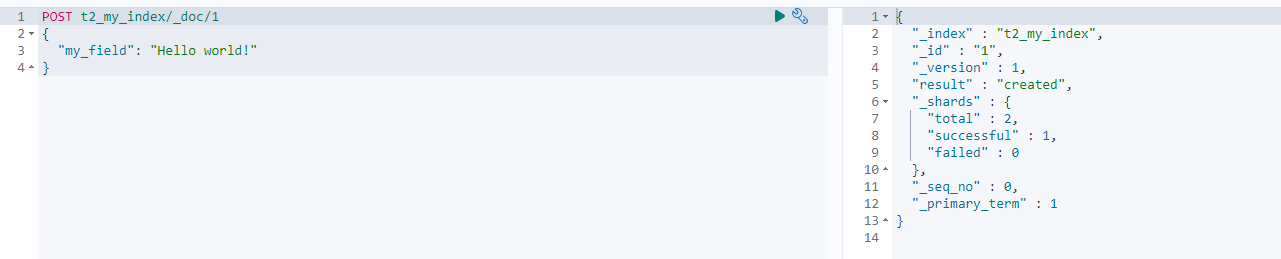
t2_my_index에서 자료를 보면 하나밖에 안 들어있는데, Index Management 메뉴에서 보면 document가 2개로 뜸

하나는 뭘까?

blogs 인덱스도 자료 개수가 4719개로 뜨는데, Index Management에서 보면 두 배로 나옴
혹시 replica에 저장된 document 개수까지 해서 이렇게 나오는건가?
GET t2_blogs_fixed2/_search
{
"size": 5,
"query": {
"match_phrase": {
"content": "open source"
}
},
"sort": [
{
"publish_date": {
"order": "desc"
}
}
],
"_source": ["title", "publish_date"]
}
GET t2_blogs_fixed2/_search
{
"size": 5,
"query": {
"match_phrase": {
"content": "open source"
}
},
"_source": ["title", "publish_date"]
}위 아래는 sort가 있는지 없는지만 다름
sort가 있을 때에는 score가 null인 것을 확인함
sort를 빼면 각 document에 맞는 score가 계산됨
정렬 방식을 내가 지정하면 score 계산을 따로 진행하지 않는 듯
GET t2_blogs_fixed2/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "meetups",
"fields": ["title", "content"]
}
}
],
"filter": [
{
"range": {
"publish_date": {
"gte": "now-3y"
}
}
}
]
}
}
}
GET t2_blogs_fixed2/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "meetups",
"fields": ["title", "content"]
}
}
],
"filter": [
{
"range": {
"publish_date": {
"gte": "now/d-3y"
}
}
}
]
}
}
}위쪽 코드가 내가 작성한 방식, 아래쪽 코드가 solution 답안
검색할 자료의 기간을 설정할 때, now-3y인지 now/d-3y인지 표현 방식만 다름
결과는 동일한데, now/d의 정확한 의미가 궁금
match와 term의 차이가 뭘까?
같은 기능인데 단순히 must는 match, filter는 term을 쓰는건가?
기능이 같다면 두 가지 함수가 있는 이유는 score 계산의 유무 차이인가?
score 계산을 할지 말지는 match, filter를 선언하는 순간 정해질텐데...
비슷한 고민을 했던 것 같은데 명확히 해결되지 않은 모양
질문 후 따로 정리할 것
pipeline 만들고 적용하고 하는 부분은 아직도 어색..
4장 여러번 돌려야 할 듯
이름 겹치면 안 돌아갈 줄 알았는데 runtime_mappings를 통해서 이미 있던 필드 위에 타입을 일시적으로 덧씌울 수도 있음
significant_terms가 terms보다 상세한 정보가 나오는 것은 확인
그런데 bg_count는 뭘까?
"aggregations" : {
"top_OS" : {
"doc_count_error_upper_bound" : 11,
"sum_other_doc_count" : 38389,
"buckets" : [
{
"key" : "Windows",
"doc_count" : 517774,
"top_urls" : {
"doc_count" : 517774,
"bg_count" : 1462658,
"buckets" : [
{
"key" : "/blog/welcome-insight-io-to-the-elastic-team",
"doc_count" : 38455,
"score" : 0.058338717766485755,
"bg_count" : 60841
},
{
"key" : "/blog/configuring-ssl-tls-and-https-to-secure-elasticsearch-kibana-beats-and-logstash",
"doc_count" : 7369,
...
...
3개의 댓글

significant_terms가 terms보다 상세한 정보가 나오는 것은 확인
그런데 bg_count는 뭘까?
significant terms는 쿼리로 반환되는 버킷의 데이터 중, 특별한 데이터를 찾는데 사용됩니다. 여기서 특별한 데이터라 의미하는 것은 단순한 카운트가 아니며, 이를 계산하는 방식은 예전에 엘라스틱에 물어봤을때도 정확한 공식은 받지 못했습니다. 다만, 이런 경우를 의미합니다.
예를 들면 전체 다큐먼트에서 10개의 문서에서만 존재하는 단어를
검색어 반환 버킷에 거의 모든 부분을 포함하여 반환한다면
해당 significant 점수가 크게 부여됩니다.(실무에선 중요 키워드 등을 뽑는데 사용)
따라서, (어떤 request에 대한 response인진 모르겠지만)bg_count의 경우 검색대상이 된 모든 다큐먼트 숫자를 의미합니다.
그냥 teams로 검색: bm25 알고리즘으로 검색
significant_terms 검색: 위의 알고리즘을 사용하여 검색
match와 term의 차이가 뭘까?
두 기능의 가장 큰 차이는 analyzer 사용 유무 입니다.
match의 경우 analyzer, 즉 형태소 분석을 사용하여 검색을 질의하게 되며, 따라서 일반적으로 text type에 질의할 때 사용됩니다.(모든 text 타입엔 analyzer가 사용됩니다)
term query의 경우 형태소 분석을 사용하지 않고 문자열 그대로를 검색하기 때문에, 일반적으로 keyword 타입에 질의할 때 사용됩니다.
정렬 방식을 내가 지정하면 score 계산을 따로 진행하지 않는 듯