BERTopic : Neural topic modeling with a class-based TF-IDF procedure
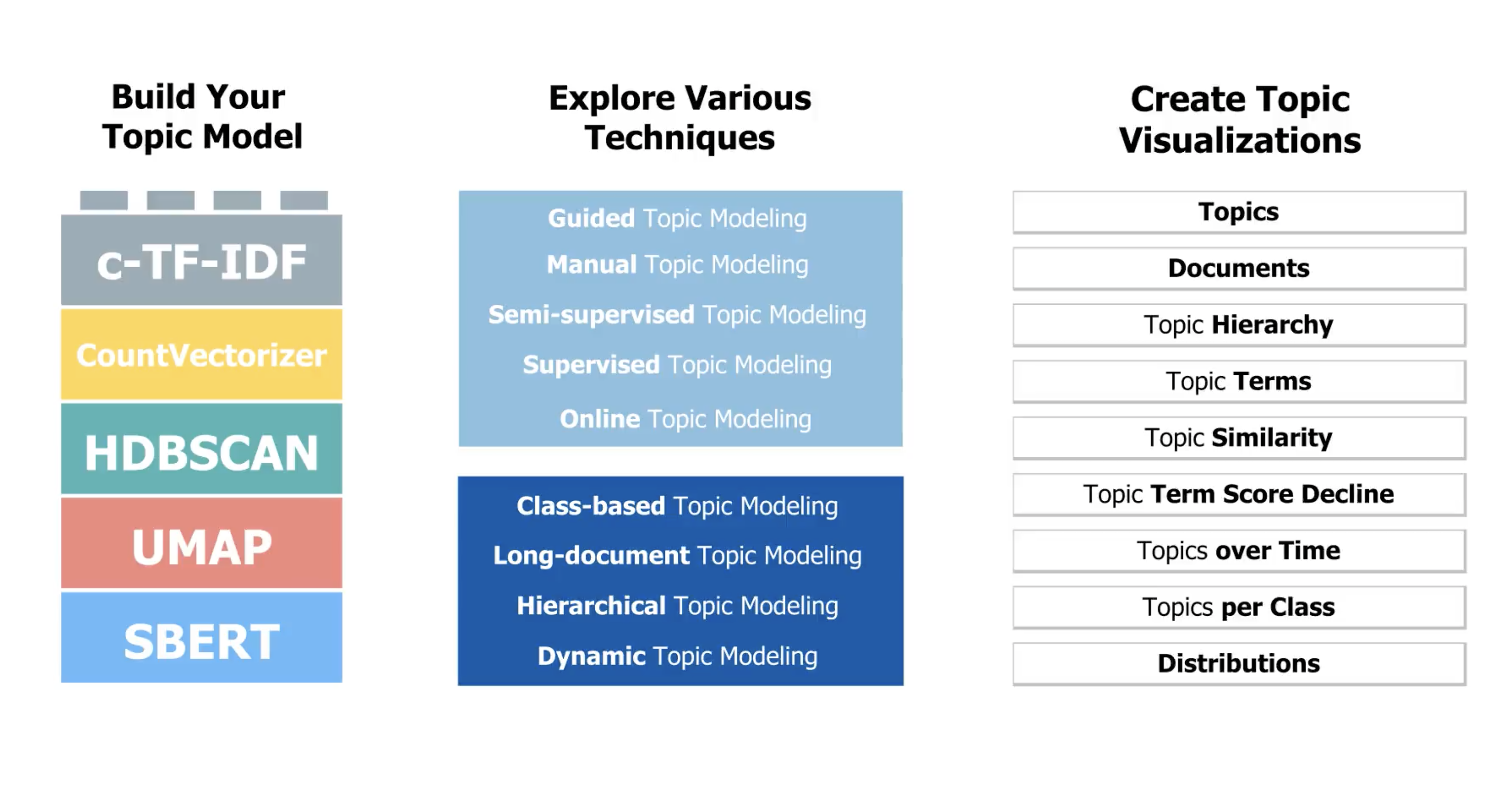
BERTopic이란 ?
Topic Modeling 기법 중 하나
💡 Topic Modeling 문장들의 코퍼스(Corpus)에 내재되어 있는 주제(토픽)를 끌어내는데 쓰이며, 전체 문서를 하나의 주제로 보고 주제를 구성하는 토픽을 찾아내어 문장을 분류하는 방법론이다. 비지도(Non-Training) 기계학습의 하나이며, 이 모델링은 주제뿐만 아니라 단어 차원 축소, 동음이의어를 찾아내는 부가적인 기능도 수행 가능하다.
BERT 기반 Embedding + Class-based TF-IDF를 사용한 것이 아이디어의 핵심이다
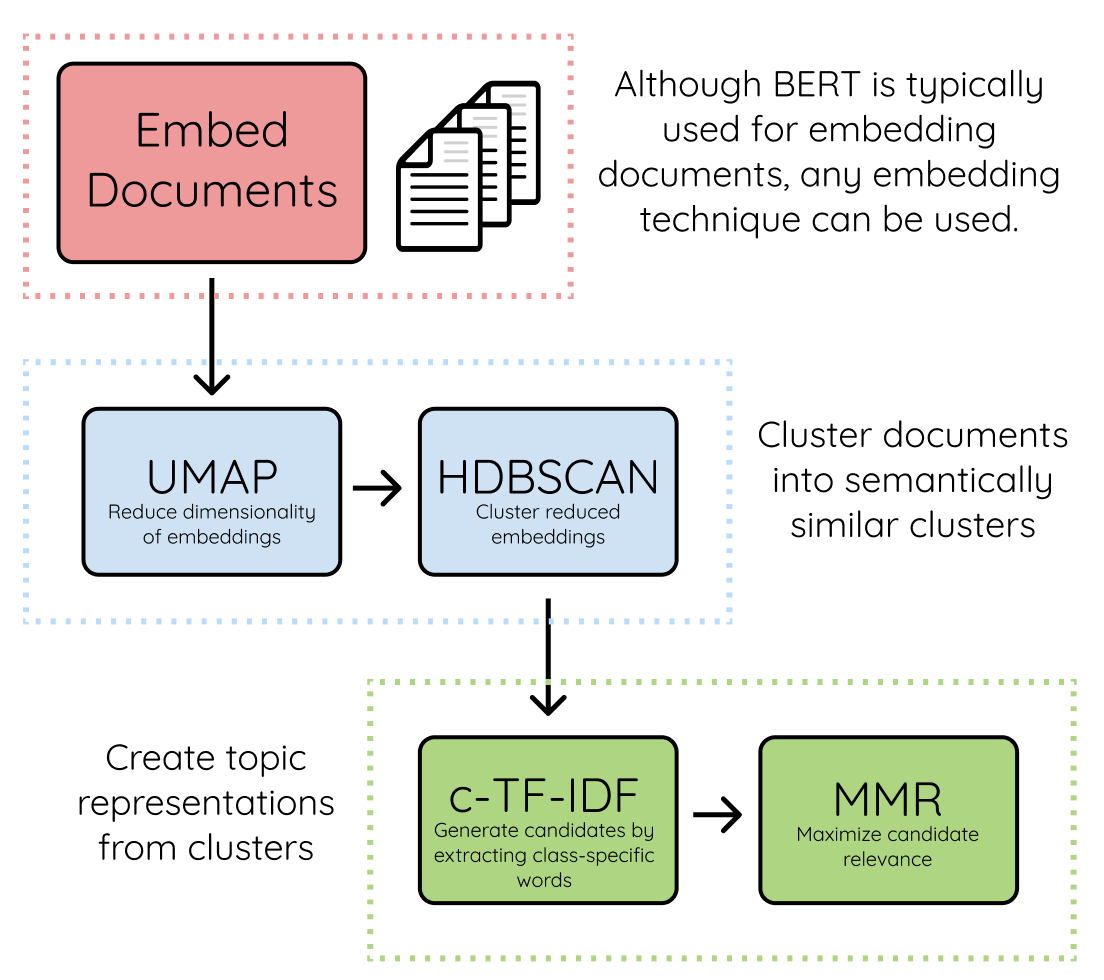
BERTopic 프로세스
- 문서 수준의 정보를 얻기 sentence-transformer(sbert)를 사용해서 각 document에 대해 embedding 수행한다.
- 클러스터링 프로세스의 최적화를 위해 UMAP을 사용해서 각 document vector의 차원을 축소하고, HDBSCAN을 이용해 클러스터링을 수행한다.
- 클러스터링을 통해 각 document vector에 대해 유사한 document끼리 묶어준다.
- C-TF-IDF (class-based tf-idf)를 통해 각 클러스터에 대해 해당 topic을 잘 표현하는 단어를 찾는다.
- MMR (Maximize Candidate Relevance Algorithm)을 이용해서 topic을 대표하는 keyword들이 최대한 다양하게 선별되도록 조정한다. document, word embedding vector에 대해 코사인 유사도를 계산해서 keyword list를 반환한다
BERTopic 사용해보기
bertopic을 사용해서 특정 문서의 키워드를 뽑아내는 작업을 해보자.
먼저 실습을 진행할 환경에 bertopic 및 한국어 전처리를 위한 패키지를 설치하자
$ pip install bertopic
$ pip install kiwipiepy실습 진행에 필요한 라이브러리를 가져온다
import json
import pickle
import glob, os
import pandas as pd
import kiwipiepy import Kiwi
import bertopic import BERTopic키워드를 추출할 문서 데이터를 가져와서 전처리를 진행한다
AI Hub에 있는 민원(콜센터) 질의-응답 데이터 중, 질병관리본부의 데이터를 가져와서 상담사 및 질문자의 대화 내용만 가져온다. 데이터는 json 형식이며, 로그인만 하면 다운로드 받을 수 있다.
dataset = dict()
# 해당 경로에 있는 모든 json 파일에 대해서
for path in glob.iglob('./data/' + '**/*.json', recursive=True):
try:
with open(path, "r") as f:
data = json.load(f)
# 인코딩 관련 에러 처리
except:
try:
with open(path, "r", encoding="cp949") as f:
data = json.load(f, encoding="cp949")
except:
continue
for row in data:
category = row["카테고리"]
speaker = row["화자"]
QA = row["QA"]
# 의도 추출
if speaker == "고객":
intention = ''.join(row["고객의도"].split())
else:
intention = ''.join(row["상담사의도"].split())
# 대화 내용 추출
if QA == "Q":
if speaker == "고객":
content = row["고객질문(요청)"]
else:
content = row["상담사질문(요청)"]
else:
if speaker == "고객":
content = row["고객답변"]
else:
content = row["상담사답변"]
conversation_id = row["대화셋일련번호"]
sentence_id = row["문장번호"]
content = content.strip()
if content no in dataset:
dataset[content] = {"Q": {"고객": set(), "상담사": set()},
"A": {"고객": set(), "상담사": set()}}
dataset[content][QA][speaker].add(intention)
# 정제한 데이터 중, 대화 내용만 리스트에 저장
corpus = list(dataset.key())corpus에는 다음과 같은 총 63283개의 문장이 들어있다.
['열이 나는데 코로나일까요?', '네, 안녕하세요', '열 말고 다른 증상은 없으신가요?', ...]빈 문자열이거나 숫자로만 이루어진 문장은 제외시킨다
preprocessed_documents = list()
for sentence in corpus:
if sentence and not sentence.replace(' ','').isdecimal():
preprocessed_documents.append(sentence)한국어 전처리를 위해 Kiwi를 이용해서 커스텀 토크나이저를 생성하자
품사 태깅은 해당 링크에서 찾을 수 있다
# 불용어를 정의한다
user_stop_word = ["안녕", "안녕하세요", "때문", "지금", "감사", "네", "감사합니다"]
# 토크나이저에 명사만 추가한다
extract_pos_list = ["NNG", "NNP", "NNB", "NR", "NP"]
class CustomTokenizer:
def __ini__(self, kiwi):
self.kiwi = kiwi
def __call__(self, text):
result = list()
for word in self.kiwi.tokenize(text):
# 명사이고, 길이가 2이상인 단어이고, 불용어 리스트에 없으면 추가하기
if word[1] in extract_pos_list and len(word[0]) > 1 and word[0] not in user_stop_word:
result.append(word[0])
return result
custom_tokenizer = CustomTokenizer(Kiwi())
vectorizer = CountVetorizer(tokenizer=custom_tokenizer, max_features=300)정의한 토크나이저 기반으로 BERTopic 모델을 정의한다.
model = BERTopic(embedding_model="sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens", \
vectorizer_model=vectorizer,
nr_topics=10, # 문서를 대표하는 토픽의 갯수
top_n_words=10,
calculate_probabilites=True) 문서에 대한 토픽을 추출한다
약 6만문장에 대해 처리하는데 약 50분 정도가 소요되므로, 빠른 실습을 위해 10000개만 뽑아서 돌린다. 10000개를 처리하는데는 약 80초가 걸린다.
# 왜인지는 파악못했으나, 아래처럼 환경변수 셋팅을 안해주면 토크나이저 관련 에러가 남
os.environ["TOKENIZERS_PARALLELISM"] = "false"
topics, probs = model.fit_transform(preprocessed_documents[:10000])뽑힌 토픽의 결과를 확인한다
model.get_topic_info()BERTopic은 다양한 시각화 결과를 확인할 수 있는 함수도 제공한다.
더 많은 정보는 해당 링크에서 확인할 수 있다.
관련 이슈
문서의 크기가 클수록, 모델이 토픽을 생성하는데 오랜 시간이 걸리기때문에 model 정보를 pickle로 저장하여 추후에 사용할때 용이하게 하려고 했으나, 'Kiwi' object는 pickle을 지원하지 않는다는 에러가 발생했다. Mecab을 사용했을때는 pickle로 저장이 되어서 Mecab 라이브러리를 이용하거나, 추출된 토픽의 결과를 csv 파일로 저장해서 추후에 사용하면 될 것 같다.
또, 토픽을 뽑으려는 문서가 너무 클때는, 랜덤 샘플링을 여러번 반복해서 샘플링된 문서들의 토픽들이 전체 문서를 대표하는 토픽을 나타내도록 코드를 작성하면 큰 문서도 빠르게 토픽을 추출할 수 있을 것이다.
reference
https://arxiv.org/pdf/2203.05794.pdf
https://wikidocs.net/162079
https://github.com/MaartenGr/BERTopic
https://bongholee.com/bertopic/
