본 포스팅은 FE 미니 반상회에서 발표한 내용을 다룹니다.
- 코드 및 발표자료 : GitHub
'초월번역'?

원문 : What were you guys smokin' when you came up with that?
직역(Papago) : 그걸 생각해냈을 때 여러분은 무엇을 피우고 있었나요?
-
'원문의 의미, 느낌을 직역한 것보다 더 효과적으로 표현한 번역을 뜻하는 말로 창작 이상의 창의적 번역 작품을 만났을 때 쓰는 표현' - 아시아경제
-
'외국어 원문의 뜻을 훼손하지 않고 현지 문화권의 느낌이 살아나도록 의역한 경우를 칭찬하는 표현' - 김경훈 한국트렌드연구소 소장
무슨 마약하시길래 이런 생각을 했어요?
LLM을 이용한 번역기(번역 서비스) 개발
요즘은 LLM 의 시스템 프롬프트에 출발어 - 도착어를 지정하고, context 를 번역하도록 작성하는 형태로 아주 간단하게 번역기를 개발합니다.
response = OpenAI(api_key=os.getenv("OPENAI_API_KEY")).chat.completions.create(
model="gpt-4-turbo",
messages=[
{f"role": "system", "content": "주어진 문장을 {source}에서 {target}(으)로 번역하세요."},
{f"role": "user", "content": "{text}"}
]
)LLM 등장 이전에는 학습용 언어 데이터셋을 구축한 후
값비싼 GPU를 이용해 모델을 학습시켜 번역기를 개발하였으나
이제는 LLM API 만 구매하여 빠르고 쉽고 저렴하게 번역기를 구현할 수 있게 되었습니다.
LLM Multi-Agent 를 이용한 번역 프레임워크
하지만 여전히 기계번역이 언어의 장벽을 넘기가 매우 어려운 분야가 있는데,
문학 작품의 경우 언어 자체의 복잡성, 묘사적 표현, 문화적인 뉘앙스를 고려하여 번역해야 하기 때문에 여전히 인간 번역가가 필요한 장르 중 하나입니다.
이러한 한계를 극복하기 위해 문학 번역에 LLM Multi-Agent 를 적용한 논문이 공개되었습니다.
(Perhaps) Beyond Human Translation: Harnessing Multi-Agent Collaboration for Translating Ultra-Long Literary Texts
- 이 논문에서는 대규모 언어모델(LLM)에 기반한 새로운 멀티 에이전트 프레임워크를 도입한다.
- 그리고 이를 이용하여 전통적인 출판 과정(publication process)을 모사한 가상의 회사 TRANSAGENTS를 실행한다.
- 문학 작품 번역에 요구되는 복잡한 문제들을 해결하기 위하여, 다수의 에이전트로부터 결합된 능력을 활용한다.
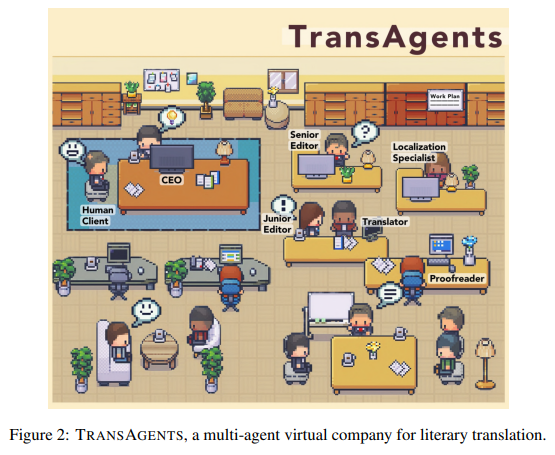
- 가상의 멀티 에이전트 번역 회사 TRANSAGENTS에는 다양한 역할이 있다.
- CEO
- 선임 편집자(senior editor)
- 주니어 편집자(junior editor)
- 번역가(translator)
- 현지화 전문가(localization specialists)
- 교정자(proofreader)
- 클라이언트가 한 권의 책에 대한 번역 작업을 할당했을 때, 선택된 에이전트로 구성된 팀은 번역을 위해 협력한다.
- 이 과정은 실제 이뤄지는 책 번역과정을 따라하는데, 서로 다른 역할의 사람들이 함께 일할 때 번역의 품질과 일관성이 유지될 수 있다.
출처 : 논문 번역 및 요약) LLM을 활용한 문학 번역 - (Perhaps) Beyond Human Translation
안 되면 되는 거 해라

논문을 읽고 세운 실험 목표 및 조건은 다음과 같습니다.
- 단순 LLM 을 이용하는 번역의 한계를 극복해 보자
- 이왕이면 트렌디한 기술을 써 보자 ➡️ AI Agent 를 적용해 보자
- TransAgent 는 혼자 구현하기에 규모가 크다 ➡️ 작은 Agent 를 구현해 보자
그렇게 생각해 낸 것은 'AI Agent 를 이용한 초월번역기' 입니다.
단순히 생각하기에 초월번역은 우선 원문을 번역(직역)하고,
번역 결과에 현지화를 거쳐 약간의 의역을 적용하면 될 것 같았고
이렇게 하면 번역 agent, 현지화 agent 이렇게 2개만으로 실험이 가능할 것 같다!
초월번역기 구현
Agent 구현에 앞서 단순히 LLM과 프롬프트만 이용했을 때 얼마나 초월번역을 잘 하는지 알아보겠습니다.
예시 문장으로 앞서 초월번역 소개에 사용한 문장을 사용하겠습니다.
원문 : What were you guys smokin' when you came up with that?
직역(Papago) : 그걸 생각해냈을 때 여러분은 무엇을 피우고 있었나요?
초월번역 : 무슨 마약하시길래 이런 생각을 했어요?
웹사이트를 이용해 번역하기

기본적인 프롬프트만으로도 매끄러운 구어체 형태로 번역해 줍니다.
API를 이용해 번역하기
ChatGPT
이번에는 웹사이트와 동일한 GPT-4-turbo 모델로 번역하되, API 를 이용하겠습니다.
import os
from openai import OpenAI
def translate_text(text):
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "당신은 콘텐츠 전문 번역가입니다. 사용자가 제공하는 문장을 한국어로 번역하세요."},
{"role": "user", "content": text}
]
)
return response.choices[0].message.content
if __name__ == "__main__":
text_to_translate = "What were you guys smokin' when you came up with that?"
translated_text = translate_text(text_to_translate)
print(translated_text)번역 결과
그거 생각해낼 때 뭘 피우고 있었어요?구어체 형태로 부자연스럽지 않게 번역해 주었지만
'you guys' 라는 부분을 고려하면 앞서 번역 결과와 같이 '너희들' 과 같은 뉘앙스를 살리거나, 조금 더 거칠게 번역했다면 더 좋았을 것 같습니다.
DeepSeek V3
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
import os
text = "What were you guys smokin' when you came up with that?"
client = ChatOpenAI(
model_name="deepseek/deepseek-chat:free",
temperature=0.7,
openai_api_base="https://openrouter.ai/api/v1",
openai_api_key=os.environ["OPENROUTER_API_KEY"]
)
prompt = [
SystemMessage(content="""
당신은 콘텐츠 전문 번역가이자 현지화 전문가입니다. 사용자가 제공하는 문장을 한국어로 번역하세요.
번역 과정에서 한국인들이 더 쉽게 이해할 수 있도록 현지화해 주세요.
문장이 수정된 이유를 반드시 한국어로 함께 설명하세요.
"""),
HumanMessage(content=f"{text}")
]
print(client.invoke(prompt).content)번역 결과
"그걸 생각해 낼 때 뭘 빨고 있었어?"
번역 이유:
1. "What were you smokin'"은 비속어 표현으로, 무언가 비현실적이거나 이상한 아이디어를 냈을 때 사용하는 표현입니다. 한국어로는 "뭘 빨고 있었어"라고 번역하여 비슷한 느낌을 전달했습니다.
2. "you guys"는 "너희들"로 번역할 수 있지만, 한국어에서는 생략해도 자연스러운 경우가 많아 생략했습니다.
3. 전체적으로 비속어 표현을 살리면서도 한국인들이 쉽게 이해할 수 있도록 현지화했습니다.꽤 자연스럽게 비속어의 느낌을 잘 살려 초월번역해 줍니다.
LangGraph 를 이용한 Agent 구축
이번에는 AI Agent 를 이용해 초월번역기를 만들어 보겠습니다.
AI Agent 를 구현할 수 있는 프레임워크로 Crew AI, AutoGen 등이 있지만
저는 좀 더 미세하게 조정 가능한 LangGraph 를 사용했습니다.
AI Agent
- 특정 작업이나 목표를 수행하기 위해 설계된 인공지능 시스템
- 인간의 개입 없이 스스로 문제를 해결하고, 판단을 내리고, 목표를 달성할 수 있는 소프트웨어
-
예시
- 고객 서비스 등 사용자의 질문에 대해 적절한 답을 제공하는 챗봇
- 도로 환경을 인식하고, 자율적으로 주행 결정을 내리는 자율주행차
- 알람 설정, 날씨 정보 제공 등 사용자가 원하는 작업을 수행하는 AI 비서
-
구성 요소
-
Task- 수행해야 할 구체적인 과제나 작업
- ex) 특정 주제에 대한 블로그 포스트 작성하기
- 수행해야 할 구체적인 과제나 작업
-
Agent- 작업을 수행하는 주체
- ex) 자료 검색 Agent
- ex) 글 작성 Agent
- 작업을 수행하는 주체
-
Tool- Agent 가 Task를 수행하는 데 사용하는 도구
- ex) 웹사이트 스크랩 API
- ex) 웹사이트 콘텐츠 검색 API
- Agent 가 Task를 수행하는 데 사용하는 도구
-
Orchestration Layer(구글 백서) / Process(CrewAI) / Router(LangGraph)- Agent 들이 태스크를 효율적으로 수행하도록 작업의 흐름을 조정
- 여러 모델, 도구, 또는 파이프라인을 관리하고 조율
- (참고) 구글 백서
-
LangGraph

자연어처리 및 AI 응용 프로그램 개발을 위한 프레임워크
- 장점
- 복잡한 작업을 그래프 형태로 쉽게 구현하고 관리할 수 있음
- 각각의 독립된 모듈 단위로 개발 (레고 블록 쌓듯이)
- LangSmith 를 이용해 모니터링 가능
- 구성 요소
State: 현재 상태를 나타내는 공유 데이터 구조Node: 실제 작업을 수행하는 함수Edge: 노드 간 연결
Agent 설계
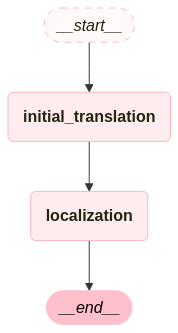
-
초벌 번역가 (initial_translator) Agent
- 주어진 영어 문장을 한국어로 정확하게 번역하는 콘텐츠 전문 번역가
- 의역이나 창의적 번역을 하지 않도록 설정
-
현지화 전문가 (localizer) Agent
- 번역된 콘텐츠가 한국 문화와 언어에 맞게 자연스럽고 이해하기 쉽게 수정
- 창의성을 발휘하도록 설정
Code - 단순 구현 (실패!)
- State 정의
from typing import TypedDict
class State(TypedDict):
text: str- Graph 인스턴스 생성
from langgraph.graph import StateGraph
graph = StateGraph(State)- Node 정의
from langchain.schema import SystemMessage, HumanMessage
# 첫 번째 노드: 초벌 번역 (영어 → 한국어)
def initial_translation(state: State):
prompt = [
SystemMessage(content="당신은 콘텐츠 전문 번역가입니다. 사용자가 제공하는 문장을 한국어로 번역하세요."),
HumanMessage(content=state["text"]) # ✅ State 의 'text' 키 사용
]
translated_text = initial_translation_llm(prompt).content
return {"text": translated_text} # ✅ 딕셔너리 형태로 반환
# 두 번째 노드: 현지화 (자연스러운 한국어로 수정)
def localization(state: State):
prompt = [
SystemMessage(content="""
당신은 한국어 콘텐츠 현지화 전문가입니다.
초벌 번역된 한국어 문장을 한국인들이 더 쉽게 이해할 수 있도록 현지화해 주세요.
"""),
SystemMessage(content="문장이 수정된 이유를 반드시 한국어로 함께 설명하세요."),
HumanMessage(content=state["text"]) # ✅ State 의 'text' 키 사용
]
localized_text = localization_llm(prompt).content
return {"text": localized_text} # ✅ 딕셔너리 형태로 반환참고 LLM 정의 (OpenRouter API 사용)
from langchain.chat_models import ChatOpenAI
import os
initial_translation_llm = ChatOpenAI(
model_name="deepseek/deepseek-chat:free",
temperature=0, # 창의성 0
openai_api_base="https://openrouter.ai/api/v1",
openai_api_key=os.environ["OPENROUTER_API_KEY"]
)
localization_llm = ChatOpenAI(
model_name="deepseek/deepseek-chat:free",
temperature=0.7, # 창의성 허용
openai_api_base="https://openrouter.ai/api/v1",
openai_api_key=os.environ["OPENROUTER_API_KEY"]
)
- Node 추가
graph.add_node("initial_translation", initial_translation)
graph.add_node("localization", localization)- Edge 연결
graph.set_entry_point("initial_translation")
graph.add_edge("initial_translation", "localization")
graph.add_edge("localization", END) # 답변 -> 종료- Graph 컴파일
graph = graph.compile()- 그래프 실행
# 입력 텍스트
input_text = "What were you guys smokin' when you came up with that?"
# 초기 상태 설정
state = {"text": input_text}
# 그래프 실행 및 결과 출력
for result in graph.stream(state):
print(f"🔄 단계: {list(result.keys())[0]}") # 현재 실행 중인 노드 이름
print(f"📝 결과: {result[list(result.keys())[0]]['text']}\n") # 해당 노드의 결과값결과

결과 문장이 원문이랑 의미가 좀 다릅니다.
이유는 다음과 같습니다. (ChatGPT야 고마워!)

Code - 현지화 과정에서 원문을 참고하도록 개선
- State 정의 ➡️ State key 수정
from typing import TypedDict
class State(TypedDict):
origin_text: str
output_text: None|str- Node 정의 ➡️ Node 입/출력 key 수정
from langchain.schema import SystemMessage, HumanMessage
# 첫 번째 노드: 초벌 번역 (영어 → 한국어)
def initial_translation(state: State):
prompt = [
SystemMessage(content="당신은 콘텐츠 전문 번역가입니다. 사용자가 제공하는 문장을 한국어로 번역하세요."),
HumanMessage(content=state["origin_text"]) # ✅ State 의 'text' 키 사용
]
translated_text = initial_translation_llm(prompt).content
return {"origin_text": state["origin_text"], "output_text": translated_text} # ✅ 딕셔너리 형태로 반환
# 두 번째 노드: 현지화 (자연스러운 한국어로 수정)
def localization(state: State):
prompt = [
SystemMessage(content="""
당신은 한국어 콘텐츠 현지화 전문가입니다.
초벌 번역된 한국어 문장을 한국인들이 더 쉽게 이해할 수 있도록 현지화해 주세요.
"""),
SystemMessage(content="문장이 수정된 이유를 반드시 한국어로 함께 설명하세요."),
HumanMessage(content=f"원문: {state['origin_text']}\n초벌 번역: {state['output_text']}")
]
localized_text = localization_llm(prompt).content
return {"origin_text": state["origin_text"], "output_text": localized_text} # ✅ 딕셔너리 형태로 반환- 그래프 실행 ➡️ 그래프 실행 입/출력값 수정
# 입력 텍스트
input_text = "What were you guys smokin' when you came up with that?"
# 초기 상태 설정
state = {"origin_text": input_text}
# 그래프 실행 및 결과 출력
for result in graph.stream(state):
print(f"🔄 단계: {list(result.keys())[0]}") # 현재 실행 중인 노드 이름
print(f"📝 결과: {result[list(result.keys())[0]]['output_text']}\n") # 해당 노드의 번역 결과결과

Tip) LangSmith 를 이용한 모니터링
환경변수로 다음 3가지를 설정하면 LangSmith 가 자동으로 모니터링을 시작합니다.
(OpenAI API 를 사용하지 않을 경우 OPENAI_API_KEY 생략 가능)
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="<your-langsmith-api-key>"
# The example uses OpenAI, but it's not necessary if your code uses another LLM provider
export OPENAI_API_KEY="<your-openai-api-key>"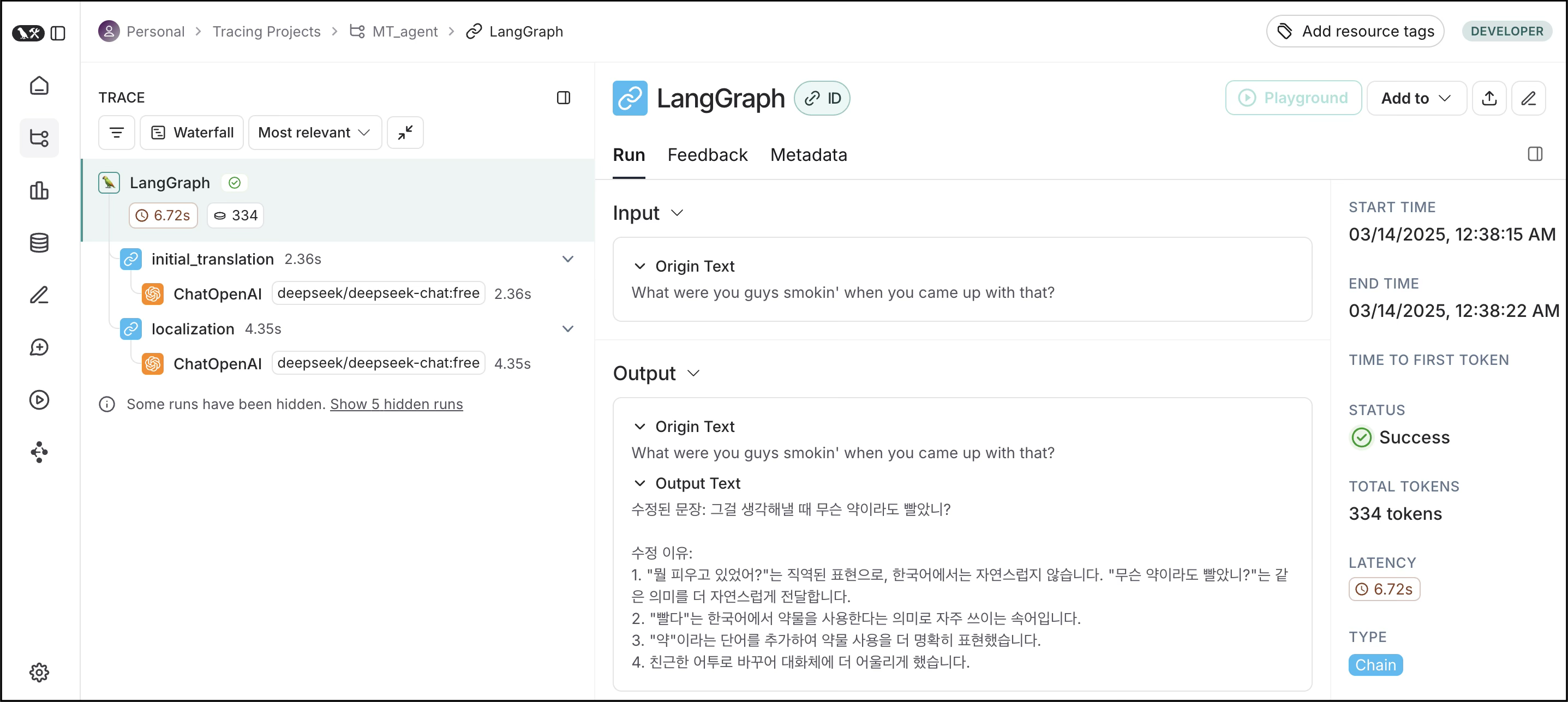
회고
-
초월번역을 하기 위해서는 LLM + 간단한 프롬프트만으로 충분하다
- 이 경우 초월번역의 품질은 LLM 의 성능에 좌우됨
-
번역에 Agent 를 사용할 경우 AI가 tool 을 선택해야 할 때, 즉 AI의 판단이 필요한 작업에 더 유용할 것으로 보인다
- 초월번역에 AI의 주도적인 역할을 부여한다던가, 또는 복잡한 분기를 임의로 추가하여 Agent의 효과를 극대화한다던가..
- 아니면 차라리 web search tool 을 사용해서 신조어 번역기를 만들었어야 했다.
-
번역뿐만이 아니라 목표로 하는 서비스의 특성과 필요한 점을 고려하여 LangChain 으로 구축할지, LangGraph 및 Agent 로 구축할지, Agent 로 구축한다면 어떤 tool 들이 유기적으로 동작해야 하는지 판단하고 설계해야 한다.
- 초월번역기의 경우 단순 선형 작업이므로 LangChain 으로 구현하는 편이 더 효율적이었을 것.
-
코딩부터 하는 대신 No-Code 툴로 먼저 빠르게 개발하고 효과를 검증했어야 했다
- Make, Zapier, Flowise…
-
전문적인 Agent 를 구축하기 위해서는 도메인에 대한 깊은 이해가 필요하다
- 개발자가 번역 산업에 대한 이해도가 낮았다면 TransAgent 를 개발할 수 없었을 것.
- 이는 AI가 대체할 수 없음 (Agent 를 개발하는 Agent 가 나온다면 과연…?)
-
복잡한 작업을 수행하는 Agent 를 구현하는 능력 == 설계 능력
- 각각의 Agent 가 상호작용하려면?
- 단순 파이프라인? 조건문? 작업 분배? …
- 입/출력 데이터는 무엇이 필요한가?
- 각각의 Agent 가 상호작용하려면?
Idea
-
Agent 를 이용해 실제로 비즈니스적인 가치가 있는 번역기를 만든다면 초월번역 대신 팩트체크를 돕는 번역기를 만들거나 RAG를 이용해 특정 도메인을 번역해야 할 경우 등등 번역 주제를 바꾸는 것도 좋을 것 같다.
-
메모리를 적극적으로 이용해 본다면 드라마나 웹소설 번역기를 만드는 건 어떨까?
- 번역중인 회차 정보는 Short-term 메모리에, 전체 회차 정보는 Long-term 메모리 RAG에...?
-
틈새시장(?) 으로 비윤리적인 도메인 전문 번역기는 어떨까 🤪😵💫☠️
- 너무 윤리적인(?) 모델의 경우(Llama3 7B) 예시 문장이 drug 관련 내용이라며 답변을 거부함 -_-;;
- 실험을 몇번 돌려보니 가끔 문장이 너무 평범하게 번역되던데 설마 LLM 윤리 가드레일에 걸려서...!? (검증은 못 해봄)
- 너무 윤리적인(?) 모델의 경우(Llama3 7B) 예시 문장이 drug 관련 내용이라며 답변을 거부함 -_-;;

재밌게 너무 잘읽었습니다! 큐레이션 축하드려요~