본 글은 LLM 관용구 번역 논문을 보고 깜짝 놀라서 새벽 4시에 의식의 흐름대로 작성한 글입니다. 😇
쌩초보 NLP 연구자이던 2020년, 나는 2편의 관용구 기계번역 논문을 국내 학회에서 발표했다.
관용구 기계번역을 위한 한-영 데이터셋 구축 및 평가 방법
- 한국어 관용구를 영어로 번역하기 위한 관용구 데이터셋(KISS) 구축 및 블랙리스트를 이용한 평가 방법
- 기계번역 모델에 관용구를 효과적으로 학습시키기 위해 특정 토큰을 삽입하여 문장에 포함된 관용구의 위치를 나타내는 방법
그리고 2025년 현재, ChatGPT 를 위시한 LLM이 쏟아져 나온 오늘날,
LLM은 웬만한 관용구를 훌륭하게 잘 번역해 준다.
....그런데 LLM을 이용하는 새 관용구 번역 논문이 나왔네!?
논문 읽는 데에 MoonLight 가 그렇게 좋다던데, 한번 써서 읽어보자!
MoonLight 를 이용한 논문 리뷰 START!
Translate Meanings, Not Just Words: IdiomKB's Role in Optimizing Idiomatic Translation with Language Models
https://arxiv.org/abs/2308.13961
3줄 요약
- 📚 다국어 관용구 지식 베이스(IDIOMKB) 구축을 통해 관용구의 비유적 의미를 생성.
- 🔍 대형 언어 모델(LLM)을 활용하여 관용구의 의미를 효과적으로 검색하고 번역 과정에 통합.
- 📈 소형 모델로도 관용구 번역 품질을 향상시키기 위한 새로운 방식의 평가 지표 제안.
IdiomKB
나는 성격이 급하니 일단 논문 내용도 읽기 전에
IdiomKB 가 뭔지 데이터셋부터 냅다 까보기 시작했다.
Knowledge Base 는 json 파일로 간단하게 만들었고...
일단 영어 데이터를 까보니 관용구 번호, 영어 관용구, 영어로 작성된 관용구의 의미,
그리고 추가 언어(중국어, 일본어)로 작성된 관용구의 의미를 확인할 수 있다.
[
{
"id": 1,
"idiom": "1 o'clock \"sharp\"",
"en_meaning": "punctually at 1 o'clock; being exactly on time",
"zh_meaning": "1点整",
"ja_meaning": "厳密に1時に"
},
{
"id": 2,
"idiom": "Bob's your uncle",
"en_meaning": "used to mean that something will be successful or easy to achieve",
"zh_meaning": "完事了",
"ja_meaning": "簡単な手順で問題が解決する"
},
...만약 한국어 관용구 데이터셋을 만든다면 나라면 이렇게 하겠다.
-
관용구 사전 다운로드
국립국어원 표준국어대사전 사이트에서 관용구 사전을 다운로드한다.
(참고로 관용구뿐만 아니라 속담, 외래어, 혼종어 사전도 다운로드 가능!) -
다운로드한 사전을 파싱하여 한국어 관용구 KB를 똑같은 포맷으로 작성
(예시)
[
{
"id": 1,
"idiom": "눈이 낮다",
"ko_meaning": "보는 수준이 높지 아니하다.",
},
...참고로 표준국어대사전의 경우 각 관용구마다 예문도 제공하므로 데이터셋 포맷을 변경해서 예문을 추가해도 좋겠다.
[
{
"id": 1,
"idiom": "눈이 낮다",
"ko_meaning": "보는 수준이 높지 아니하다.",
"ko_example" : "난 눈이 낮은 편인지 웬만한 여자는 다 예뻐 보인다.",
},
...아차차, 나 논문 읽다 말았지.
논문에 대한 심층 분석 및 기술적 설명 (한국어)
이 논문은 기계 번역(MT) 시스템과 범용 언어 모델(LM)이 관용적인 표현을 효과적으로 번역하는 데 어려움을 겪는다는 점에 주목하고, 이를 해결하기 위해 IDIOMKB라는 다국어 관용구 지식 베이스를 제안합니다. IDIOMKB는 대규모 언어 모델(LLM)을 활용하여 관용구의 비유적 의미를 추출하고, 이를 작은 규모의 모델(예: BLOOMZ, Alpaca, InstructGPT)이 관용적 텍스트를 더 정확하게 번역할 수 있도록 돕는 것을 목표로 합니다. 또한, GPT-4를 기반으로 한 새로운 자동 평가 지표를 개발하여 인간의 평가와 더 잘 일치하도록 하고, IDIOMKB가 모델의 성능을 향상시킨다는 것을 입증합니다.
핵심 방법론 (IDIOMKB 구축 및 활용)
핵심 방법론은 크게 IDIOMKB 구축과 IDIOMKB를 활용한 관용적 번역 개선, 그리고 GPT-4 기반 평가 지표 개발로 나눌 수 있습니다.
-
IDIOMKB 구축 (지식 증류)
-
데이터 수집: 영어, 중국어, 일본어의 기존 관용구 데이터셋(MAGPIE, IMIL, EPIE, PIE, PETCI, CCT, ChID, OpenMWE, ID10M)을 통합하여 다국어 관용구 목록을 구축합니다. 각 데이터셋의 특성(예: 문맥 정보, 번역 정보, 의미 정보)을 고려하여 가장 포괄적인 목록을 확보합니다.
-
의미 추출: LLM(GPT-3.5 시리즈, BLOOM, BLOOMZ)의 강력한 생성 능력을 활용하여 관용구의 비유적 의미를 추출합니다. 이는 지식 증류(Knowledge Distillation)의 한 형태로, 큰 모델(LLM)의 지식을 작은 모델이 활용할 수 있도록 하는 방법입니다. 구체적으로, In-Context Learning 방식을 사용하여 LLM에 관용구와 그 의미에 대한 예시를 제공하고, 새로운 관용구에 대한 비유적 의미를 생성하도록 합니다.
-
프롬프트 엔지니어링 (Prompt Engineering): LLM이 관용구의 비유적 의미를 정확하게 생성하도록 유도하기 위해 신중하게 설계된 프롬프트를 사용합니다. 프롬프트에는 관용구의 비구성적(Non-compositional) 특성을 강조하고, literal한 의미와 figurative한 의미의 차이를 명확히 설명하는 지시사항이 포함됩니다. 또한, 다양한 언어 쌍에 대해 여러 예시를 제공하여 LLM이 문맥을 이해하고 적절한 의미를 생성하도록 돕습니다. 프롬프트 예시는 다음과 같습니다.
/* Task prompt */ Given a Chinese idiom, please write the idiom’s figurative English meaning. Please note: Idiom always expresses figurative meaning which is different from literal meaning of its constituent words. /* Examples */ Case 1: Chinese idiom: 明目张胆 English meaning: straightforwardly, without any concealment ... /* Test Data */ Case 5: Chinese idiom: 一气呵成 English meaning: to complete a task or work in one go, without stopping or taking a break
-
-
IDIOMKB를 활용한 관용적 번역 개선 (KB-CoT)
- 관용구 식별: 번역 대상 문장에서 관용구를 식별합니다. 이 논문에서는 관용구 식별을 별도의 단계로 처리하지 않고, 기존 데이터셋의 관용구-문장 쌍을 사용합니다.
- 의미 검색: IDIOMKB에서 식별된 관용구에 해당하는 비유적 의미를 검색합니다.
- 프롬프트 구성: LLM에 제공되는 프롬프트에 검색된 관용구의 의미를 포함합니다. 이는 Chain-of-Thought (CoT) Prompting과 유사한 방식으로, LLM이 관용구의 비유적 의미를 이해하고 번역에 반영하도록 돕습니다. Direct Prompting과는 대조적으로, KB-CoT는 LLM이 관용구의 non-literal한 의미에 집중하도록 유도하여 더 정확한 번역을 생성합니다.

-
GPT-4 기반 평가 지표 개발
* **평가 기준 설정:** 관용적 번역의 품질을 평가하기 위한 상세한 기준을 설정합니다. 이 기준은 1점(오역 또는 literal한 의미만 번역), 2점(기본적인 비유적 의미는 전달하지만 불완전함), 3점(정확하고 문화적 뉘앙스까지 반영한 우수한 번역)으로 구성됩니다. * **프롬프트 구성:** GPT-4가 번역 품질을 평가하도록 유도하기 위해 명확하고 상세한 프롬프트를 설계합니다. 프롬프트에는 평가 기준이 명시되어 있으며, 번역 대상 문장과 번역 결과가 함께 제공됩니다. ``` /* Task prompt */ Evaluate the idiom translation in the given Chinese translation of an English sentence. Focus on the idiom’s figurative meaning. /* Evaluation Criteria */ 1 point: Ignores, mistranslates, or only translates the literal meaning of the idiom. 2 points: Conveys basic figurative meaning but may lack refinement or have minor imperfections. 3 points: Exceptional translation, accurately conveying figurative meaning, context, and cultural nuances. /* Test Data */ Evaluate the following translation: English sentence: <source> Idiom in the English sentence: <idiom> Chinese translation: <translation> Evaluation (score only):<score> ```결론적으로, 이 논문은 IDIOMKB라는 다국어 관용구 지식 베이스를 구축하고, 이를 활용하여 작은 규모의 언어 모델의 관용적 번역 성능을 향상시키는 효과적인 방법을 제시합니다. 또한, GPT-4 기반의 새로운 자동 평가 지표를 개발하여 관용적 번역의 품질을 더 정확하게 평가할 수 있도록 하였습니다. IDIOMKB는 향후 관용적 표현의 교차 문화적 정렬 연구에도 유용한 자료가 될 것으로 기대됩니다.
Improving LLM Abilities in Idiomatic Translation
https://arxiv.org/abs/2407.03518
그리고 올해 1월, COLING 의 Low-Resource 워크샵에 후속 논문이 나왔다.
마찬가지로 MoonLight 의 도움을 받아서 읽어 보자.
3줄 요약
- 🤖 Semantic Idiom Alignment (SIA) 방식으로 문장의 의미를 임베딩한 후, 코사인 유사도를 활용해 목표 언어의 이디엄을 식별합니다.
- 📝 LLM 기반 이디엄 정렬 (LIA) 기법으로 LLM이 직접적으로 적절한 이디엄의 대응어를 제안하도록 유도합니다.
- 📊 인간 평가를 통해 SIA가 이디엄 스타일을 효과적으로 보존하며, 여러 언어 쌍에서 더 높은 번역 정확도를 달성함을 입증합니다.
이 논문에서는 대형 언어 모델(LLMs)을 활용한 숙어 번역의 개선에 대해 다루고 있습니다. 특히, 숙어는 언어적이고 문화적으로 독특한 표현으로, 현재의 LLM은 숙어의 의미를 잘 이해하지 못해 그 결과가 문자 그대로의 의미로 해석되거나 부정확한 번역이 발생하는 경우가 많습니다. 예를 들어, "break a leg"를 한글로 번역하면 원래 의미와는 상관이 없는 비논리적인 문구가 될 수 있습니다. 이러한 문제를 해결하기 위해, 연구팀은 두 가지 방법을 제안했습니다.
핵심 방법론
-
Semantic Idiom Alignment (SIA) 방법:
- 이 방법은 사전 훈련된 문장 임베딩을 활용하여 목표 언어의 숙어를 식별합니다.
- 구체적으로는, 영어 숙어의 의미를 여러 언어로 임베딩(classify)하고, 코사인 유사도(cosine similarity)를 사용하여 가장 적합한 목표 언어의 숙어를 검색합니다.
- 이 과정에서 임베딩된 벡터는 숙어의 의미를 포착하며, 두 벡터 간의 각도 코사인을 계산하여 유사성을 구합니다. 결과 값은 -1에서 1 사이의 범위이며, 0.7 이상의 유사도를 가진 숙어를 후보로 선택합니다.
- 후보 숙어가 발견되면, GPT-4에게 질문하여 문화적 및 상황적 맥락에 가장 적합한 숙어를 선택하도록 유도합니다.
-
Language-Model-based Idiom Alignment (LIA) 방법:
- 이 방법은 LLM에게 해당 언어의 숙어를 제안하도록 프롬프트를 제공합니다.
- 모델은 최대 3개의 숙어 후보를 찾게 됨과 동시에, 필요 시 불일치도 허용됩니다. 이후 가장 적합한 후보를 선택하여 번역에 반영하게 됩니다.
데이터셋 구축
논문에서는 영어, 중국어, 우르두어, 힌디어의 숙어 데이터를 사용하였습니다.
- 각 언어의 데이터셋은 숙어, 그 의미, 예문으로 구성되어 있습니다.
- 영어-중국어 및 중국어-영어 번역에서는 MWE-PIE와 CCT "cheng yu" 데이터셋을 사용했습니다.
- 우르두어와 힌디어 데이터셋은 각각 2100개 이상의 숙어를 포함하고 있으며, 영어 숙어의 의미와 매칭을 통해 생성되었습니다.
평가 방법
모델 성능을 평가하기 위해, 원문과 번역문을 비교하였습니다. GPT-4와 GPT-4o 모델, 그리고 인간 평가자들의 평가 결과를 비교하였으며, 번역의 정확성과 맥락적 적합성을 기준으로 점수를 매겼습니다.
결과
- 연구 결과 SIA 방법이 특히 숙어의 문맥 및 문화적 뉘앙스를 잘 유지하는 경향이 있음을 보여주었습니다.
- LIA 방법도 나름의 장점을 가졌지만, SIA 방법에 비해 덜 효과적이었습니다.
- 자연어 처리 평가 역시 SIA 방법이 인간의 평가와의 일치도가 높았음을 나타냈습니다.
결론적으로 이 연구는 LLM을 활용한 숙어 번역 개선에 기여하며, 문화적 표현을 유지하는 번역 기술의 기초를 다지는데 중요한 결과를 보여주고 있습니다. 이러한 접근법은 궁극적으로 다양한 언어의 의사소통을 더 풍부하고 정확하게 만들 수 있는 가능성을 지니고 있습니다.
ChatGPT-4o 로 대충 돌려보기
일단 대충 관용구랑 관용구 의미를 프롬프트로 넣어서 번역 품질이 개선되나 보자.
웬만한 관용구는 번역을 잘 해주는데...

찾았다, 관용구 오역 중 한 가지 경우인 직역되는 경우!

프롬프트 고!

혹시 문장부호 들어가서 그런가?
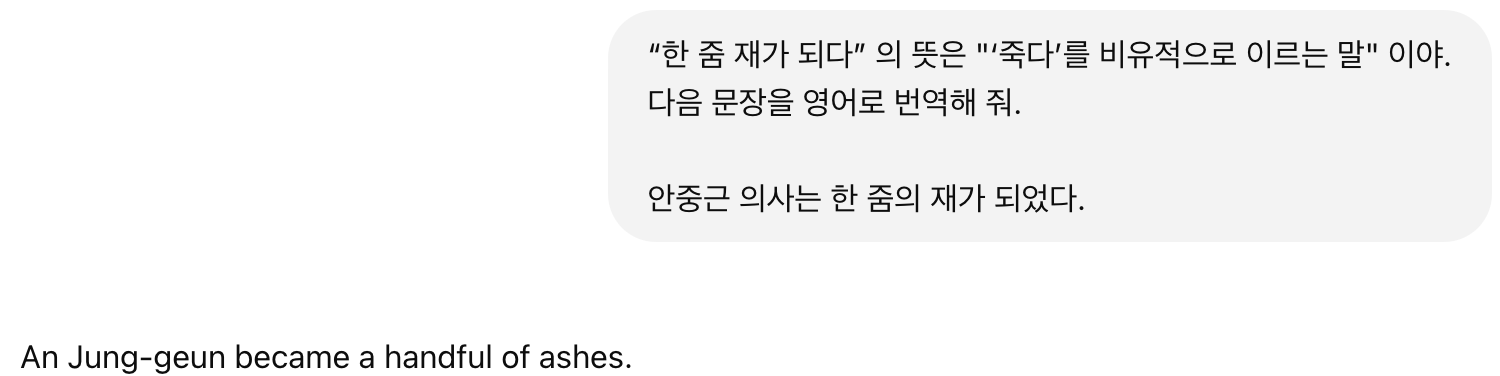
이런, 관용구 의미를 참고하라는 지시를 넣어 볼까?

왜 관용구 의미가 제대로 반영이 안되지... 프롬프트 더 잘 넣어야 하나 😇😇😇
느낀 점
-
두 논문 다 GPU 없이 실험이 가능했다(!)
- 라떼는 말이야.. GPU 없으면 모델을 못 돌렸는데.. 😂😂
-
이제는 대부분의 LLM 논문에서 LLM 모델명만 명시하는 경우도 많다
- 라떼는 말이야.. 모델명이랑 레이어 갯수같은 파라미터도 명시했는데.. 😂
-
실험 장벽이 좀 내려간 느낌
- 실험에 필수적이지만 개인 연구자가 갖추기 어려웠던 장비 문제가 해결된 셈
- 실험 방법론 + 잘 구성된 프롬프트만으로 실험한 경우가 많이 보인다.
-
두 논문 내용 잘 조합해서 한국어 관용구에 대해 실험을 해서 국내 학회에 제출해도 좋을 듯?
-
MoonLight 짱이다!
- Scientific 보다 한국어 사용자에게 훨씬 가독성 좋다(한국어 번역 제공)
- 심지어 처리 속도가 매우 빠름!
- 사용성도 매우 좋다. 유저가 사용하기 편리하게 화면과 기능이 구성되어 있다. 단락별로 돋보기 버튼 클릭하면 AI가 설명해 준다.
- 라떼는 말이야.. 논문 프린트하거나 아이패드에 넣어서 필기하고 조금씩 복사해서 번역기 돌리면서 읽었는데... 😂😂
- 이 기능이 약이 될 지 독이 될 지는 모르겠으나, 요약 내용이 논문 원문과 조금 다른 부분이 보인다.
- 논문에는
for instance, directly converting “break a leg” into a nonsensical phrase in the target language.즉break a leg를 타겟 언어(한 ➡️ 영 번역하는 경우 영어를 말함) 로 번역한다는 문장만 있는데, Moonlight 의 요약 결과에는break a leg"를 한글로 번역하면 원래 의미와는 상관이 없는 비논리적인 문구가 될 수 있습니다라고 나옴.
- 논문에는
- 프롬프트를 중간에 생략하기도 하고.. (그래서 본 포스팅에는 코드블록 대신 캡쳐 첨부)
- 그럼에도 논문 리서치하는 시간과 노력이 엄청 절약됨!
- 유료버전 결제해서 쓸 가치가 충분함!!!!
