
아래의 모든 내용의 출처는 Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019. 임을 밝힙니다!
🛠️ 배경 & 문제점
Problem : Entanglement
2014년도에 처음 제시된 GAN (적대적 생성 네트워크)를 통해서, 모델이 단순히 이미지를 암기하는 것이 아니라, 정말로 그럴싸한 이미지를 만들어낼 수 있도록 하는데에 성공했습니다.
그 이후, 생성되는 이미지의 해상도와 퀄리티 등은 "Progressive Growing of GANs" 등의 논문에서 빠르게 성장을 해왔지만, 생성자들의 작동 과정은 여전히 상당 부분이 black box문제로 남아 있었고, 이미지 합성 과정의 다양한 부분에 대한 이해가 여전히 부족한 상황이었습니다.
또한, 고해상도의 그럴듯한 얼굴 이미지를 만들어내는데에는 성공했지만 latent vector의 interpolation 결과를 살펴 보았을 때, 원하는 특성만 제어하는 것이 (ex. 남자 ↔️ 여자) 어려운 상황이었습니다.
따라서 이 논문의 저자들은 PGGAN을 기본 구조로 하여 새로운 형태의 StyleGAN과 2가지 평가지표를 제시했습니다.
🧨 Problem: Latent Vector
기본적으로 기존의 모델들은 Gaussian 분포 등으로부터 Sampling된 latent code를 generator에 input으로 바로 집어넣었습니다.
그러나 아래 예시 그림에서 나타나듯이, 이러한 방법은 factor들이 일반적인 데이터셋과 latent의 분포로부터 완전히 *disentangle되는 것을 막습니다.
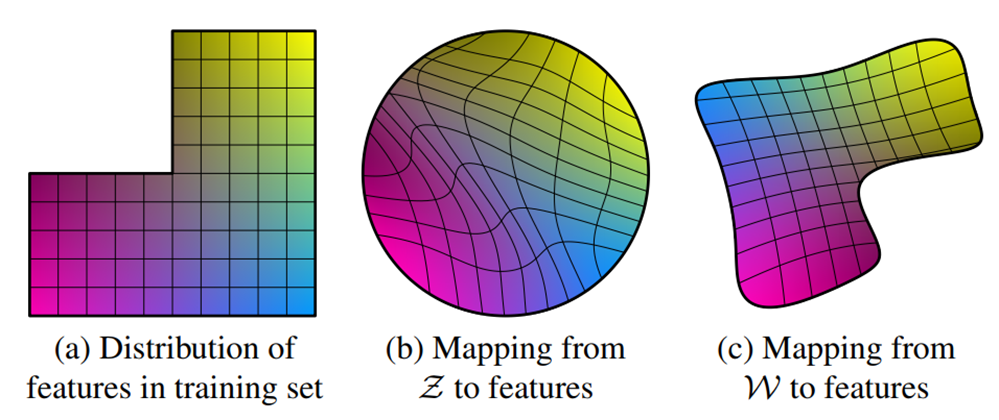
*entangle ↔️ disentangle : 얽히다 ↔️ 구분하다
제가 이해한 바로 풀어서 서술하자면, 사람들의 코의 길이나 너비같은 수치는 아마 가우시안 분포를 따를지도 모릅니다.
하지만, 머리카락의 길이가 단발이 제일 많이 분포하고, 숏컷이나 장발은 극히 드물게 분포하지는 않을 것이라고 생각이 됩니다. 비슷한 예시로 성별이나 그에 따른 특성들도 중성적인 얼굴을 중심으로한 가우시안 분포가 아닐 수 있습니다.
하지만 이러한 분포를 고려하지 않은 채 latent vector를 Gaussian이나 uniform 분포로부터 Sampling하여 바로 input으로 집어 넣을 경우, 위 그림과 같은 entanglement가 발생한다고 생각됩니다.
🎆해결방법 : Mapping Network
따라서 이 논문은 학습된 8-layer MLP을 통한 non-linear mapping을 통해서 *unwarp된 intermediate latent code W를 통해서,
언급된 제약 (Latent code Z가 반드시 train data의 확률분포를 따라가야 하는) 으로부터 벗어나 disentangle 될 수 있도록 만들었으며,
variation의 요소들이 더욱 linear해질 수 있도록 했습니다.
좌측 예시 그림을 통해서 조금 더 쉽게 이해할 수 있는데, (b)와는 달리 (c)는 제약에서 벗어나 training set의 distribution과 유사한 분포를 보일 수 있으며, 직선들이 거의 휘지 않은, 말 그대로 linear한 형태를 나타내는 것을 볼 수 있습니다.
*warp : 휘다, 왜곡하다
❔그래서 왜 StyleGAN인데❔
위에서 잘 구해낸 intermediate latent code W 를 통해서, 중간중간마다 AdaIN을 통해 Style을 입히기 때문입니다! 이게 뭔소린지 더 디테일하게 설명해보겠습니다.
AdaIN과 Style
최초의 Style Transfer이 발표된 이후, 그 속도를 빠르게 하면서도 여러가지 스타일을 적용시킬 수 있는 방법으로 AdaIN이 제시되었습니다.
주어진 이미지의 content(하늘, 집, 바다, 의자, 사람)는 유지하되 style(질감, 재료, 화풍 등)을 바꾸기 위한 효율적인 방법이 바로 feature space 상의 통계량, 즉 평균과 분산(표준편차)을 건드리는 것입니다.
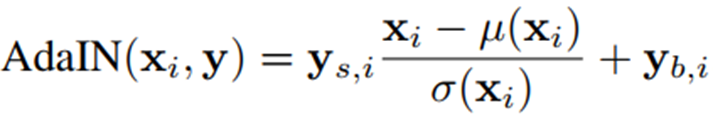
위 방법을 GAN에 적용한 것이 StyleGAN인데, convolution layer을 거치고 나온 각 feature map에 대해서 Normalize를 진행한 후, latent code W 에 Affine Transformation을 적용해서 얻어낸 scale과 bias 값을 이용해 Style을 적용시키는 것입니다.
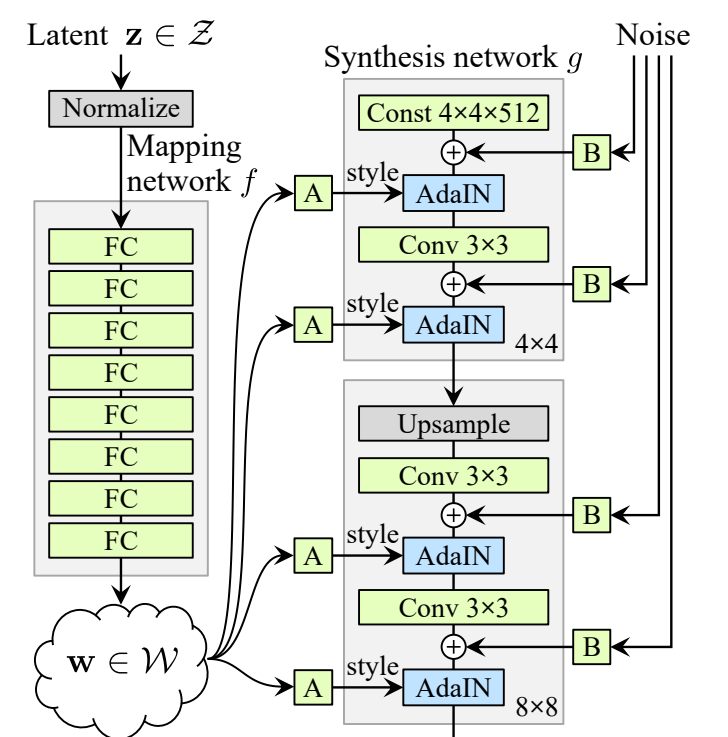
Noise Inputs & Constant Tensor Input
또한, 논문에서는 generator에게 확률적인 디테일(머리카락 배치, 피부트러블, 모공 등)을 생성하기 위한 직접적인 수단인 “noise input”을 제안합니다. 이것은 uncorrelated Gaussian noise이며 각 convolution layer와 AdaIN사이에서 학습된 per-channel scaling이 적용된 이후, 모든 feature map에 더해집니다.
(W로부터 계산된 style은 각 feature map의 전체를 같은 값으로 scale하고 bias하기에 이미지 전반에 영향을 미쳐 포즈와 배경 같은 global 한 effect를 조절하고,
반면에 noise는 각 픽셀에 independent하게 계산되어 더해지기 때문에 Stochastic한 variation 조절에 적합한 것입니다.)
추가적으로, 베이스라인의 향상을 이끌어 낼 수 있는 방법을 발견했는데, 바로 학습된 4x4x512의 상수 Tensor로부터 이미지 합성을 시작하는 것입니다. latent code W로부터 얻어낸 값으로 AdaIN을 통해서 style을 각 convolution layer 이후에 적용하기에 더 이상 latent code를 first convolution layer에 input으로 줄 필요가 없기 때문에 가능해진 일입니다.
이 밑으로는 경어체로 포스팅을 작성하겠습니다!
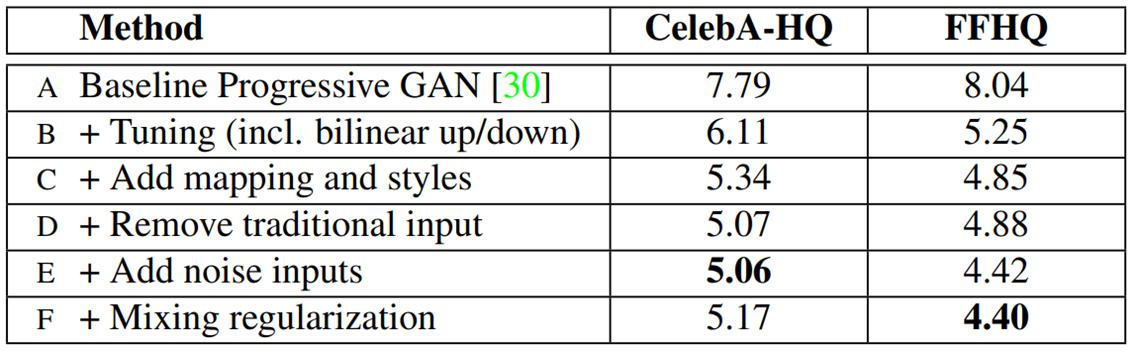
논문에서 제시한 Table을 통해서 Tuning된 기존의 generator(B)보다 해결방법1과 2에서 언급한 4가지 (intermediate code W, AdaIN with Style y, noise input, learned constant tensor input) 방법을 적용한 (E)의 성능이 약 20% 더 좋은 것을 알 수 있다!
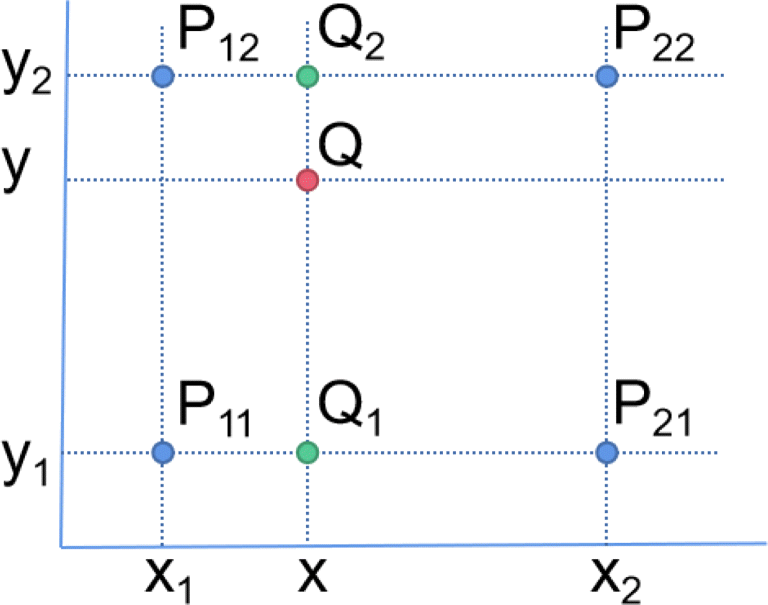
Bilinear Interpolation
- (B)에서 적용한 Bilinear up/down의 Bilinear Interpolation은 기존에는 두점에 대해서 진행하던 linear interpolation을, 이번에는 근처 4점에 대해서 진행하는 것이다. 생각보다 너무 간단해서 놀랐다. 아래 그림을 보면 바로 이해될 것이다.
다시 원론으로 돌아와, FFHQ 데이터 셋으로부터 curate되지 않은 채 생성된 위의 이미지들을 통해서 generator의 성능을 파악할 수 있다. 심지어 안경이나 모자 같은 악세서리도 성공적으로 합성되었다고 한다. (low resolution에서 truncation trick이 선택적으로 적용되기는 하였으나, FID와 같은 성능지표들은 모두 trick없이 계산되었다.)

추가적으로, 각 Style들은 신경망 내부에서 localize되었다(style의 일부를 바꾸는 것이 이미지의 특정한 부분에만 영향을 미친다)고 볼 수 있는데, 이는 AdaIN operation이 zero-mean / unit-variance로 normalize를 진행한 후에 scale과 bias를 적용하기에, 기존의 통계량에 영향을 받지 않고 오직 하나의 convolution에 대해서만 control을 진행하기 때문이다.
Truncation Trick
- train data에 굉장히 적게 분포되어있는 부분들은 생성모델이 그럴듯한 이미지를 만들기 어렵고, 그러한 이미지를 만드는 것을 피하기 위해서 truncaiton trick을 사용하여 위의 예시를 만들어냈다고 논문에서는 밝히고 있다. Appendix B에는 그에 대한 디테일한 설명이 포함되어있는데, 상당량의 W의 평균을 구해서 일종의 average face를 구해낸 다음, 이미지를 생성할 때 집어넣을 W를 아래 수식을 통해 변형시켜 average에서 너무 벗어나지 않은 이미지를 생성할 수 있도록 일종의 trick을 적용했다고 설명했다.
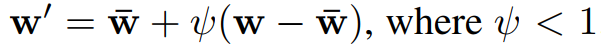
Mixing Regularization
- 기존의 문제를 해결한 것은 아니나, style들을 더욱 localize하기 위해서 논문에서는 mixing regularization을 제안한다. 하나가 아닌 두 개의 random한 latent code를 crossover point를 기점으로 전후로 나눠 적용하는 것이며 이러한 regularization 기법은 인접한 style들이 서로 correlate되어있다는 추측을 차단하는 효과가 있다고 한다.
- 이전에 보여준 Table의 case (F)를 살펴보면 FFHQ 데이터셋에서 FID 성능이 제일 좋게 나온 것을 볼 수 있다.
또한 아래 그림은 두개의 latent code를 사용해 이미지를 합성한 예시로, Style의 subset들이 high-level의 attribute를 잘 control하는 것을 확인할 수 있다.

- Coarse style(4-8) : 성별, 얼굴형, 각도, 이목구비 위치, 안경여부, 헤어스타일 등
- Middle styles(16-32) : 성별이나 얼굴형, 각도, 이목구비 위치, 안경 등에는 영향을 별로 주지 못했으나, 헤어스타일 약간과 이목구비의 생김새, 표정 등에 영향을 미침
- Fine Style(64-1024) : 색깔이나 조명, 헤어 질감 등의 디테일한 부분들
🆕새로운 2가지 Metric
Perceptual Path Length
Interpolation을 수행할 때, 양 끝에 존재하지 않던 feature가 갑자기 나타나는 경우가 있을 수 있는데, 이는 latent space의 entangle을 의미하며 variation의 요소들이 잘 분리되지 않았다는 뜻이다.
논문에서는 이를 측정하기 위해 interpolation을 수행하는 도중 이미지가 얼마나 급격하게 변하는지 측정하는 “Perceptual Path Length”라는 개념을 제안한다.
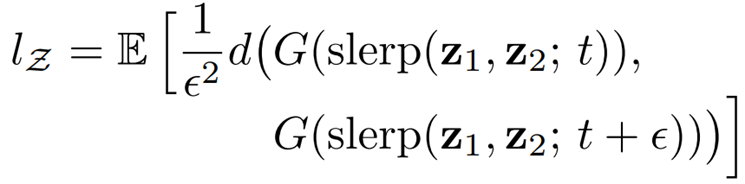
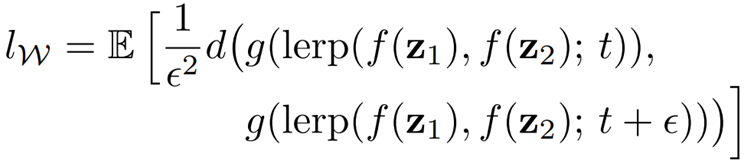
수식의 e는 10^-4의 매우 작은 수로, interpolation의 위치를 아주 약간 변경한 것이며, 둘의 VGG16 embedding 값 사이의 perceptual distance의 기댓값을 계산하여, 얼마나 큰 변화가 있었는지를 측정할 수 있다.
만약, latent space가 덜 휘어졌다면(더 linear하다면) 더욱 smooth한 변화를 보일 것이고 그에 따라 Perceptual Path Length도 더 작은 값을 보일 것임을 예상할 수 있다.
Linear separability
Linear Separability는 이름 그대로 Latent code들이 linear한 hyperplane에 의해 얼마나 잘 분리될 수 있는지를 측정하는 방법이다.
조금 더 자세히 설명하자면, CelebA 데이터셋에 대해 generator를 통해 200k의 이미지를 만들어내고, 40개의 attribute에 대해서 보조 분류 network를 이용해 confidence가 높은 100k의 이미지를 골라낸 이후, linear SVM으로 latent space point(Z 또는 W)에 대해 분류를 시도하여 conditional Entropy를 계산해 얼마나 선형적으로 분류가 잘 안되는지를 알아낼 수 있다.
별도 - WGAN-GP
- 정보량 : 놀람의 정도
- Entropy : 정보량의 기댓값. 불확실성의 정도
- KL Divergence : 어느 분포 p가 다른 분포 q의 정보량을 얼마나 잘 보존하는가 / 상대적인 엔트로피 / 최솟값 0
- 문제점 : 비대칭적임 / 가 0에 가까워지면, 의 효과가 무시됩니다. - JS Divergence : [0, 1]의 범위 / 대칭적 / 부드러움
- GAN의 Loss Function는 사실상 JSD의 최적화
- GAN에서의 문제점 : 판별기는 JSD를 최대화하고 생성기는 최소화하려하기 때문에 수렴이 어려움 (성능이 나쁘면 정확한 피드백 X / 성능이 좋으면 Loss가 0에 가까워져 Vanishing Gradient문제 발생)
- JSD 자체의 문제 : 겹치는 부분이 없는 경우, 그 값이 , 상수로 고정
- Wasserstein 1: 어느 분포를 다른 분포로 만드는 데에 드는 에너지의 총량 중 최솟값.
- 문제점 : 모든 조합이 너무 많다...
- Kantorovich-Rubinstein duality를 사용하여 대신 제약을 만족하는 f를 근사하는 문제로 변경합니다 (자세한 설명은,,, 모릅니다 ㅜㅜ)
- 또 다시 문제점 : 제약을 만족하기 위해 weight clipping을 통해 w의 범위를 [-0.01, 0.01]로 제한하는데, 이는 Terrible way라고 합니다.
- WGAN-GP : weight clipping 대신에 gradient penalty(GP)를 통해서 제약을 만족시키자!
