아직 미완성된 포스팅입니다.
🛠️ 배경 & 문제점
CNN 등의 neural network가 발달하면서, 사람들은 network architecture을 디자인 하는데에 많은 신경을 쓰기 시작했다. 그러다보니 hyper-parameter가 매우 늘어났고 이를 tuning하는 것은 매우 어려운 일이 되어버렸다.

그러다, VGGnet 등에서 같은 shape의 block들을 쌓는 간단한 rule을 적용하며 선택해할 hypter parameter가 줄게 되었고, 모델의 depth가 중요해지게 되었다. 또, 이러한 방식은 모델이 특정 데이터셋에 지나치게 특화되는 것을 막기도 하는 역할을 했다.
이후에 ResNet이나 WRN 등에서 더욱 deeper 혹은 wider한 network들이 등장하여 높은 성능을 보였으나 그만큼 parameter의 개수가 늘어나 연산량과 학습시간이 늘어나게 되었다.

그와 반대로, Googlenet과 같은 Inception model들에서는 위와 같이 세세히 디자인 된 topology들을 통해서 거의 비슷한 accuracy와 낮은 complexity를 달성하는데에 성공했따.
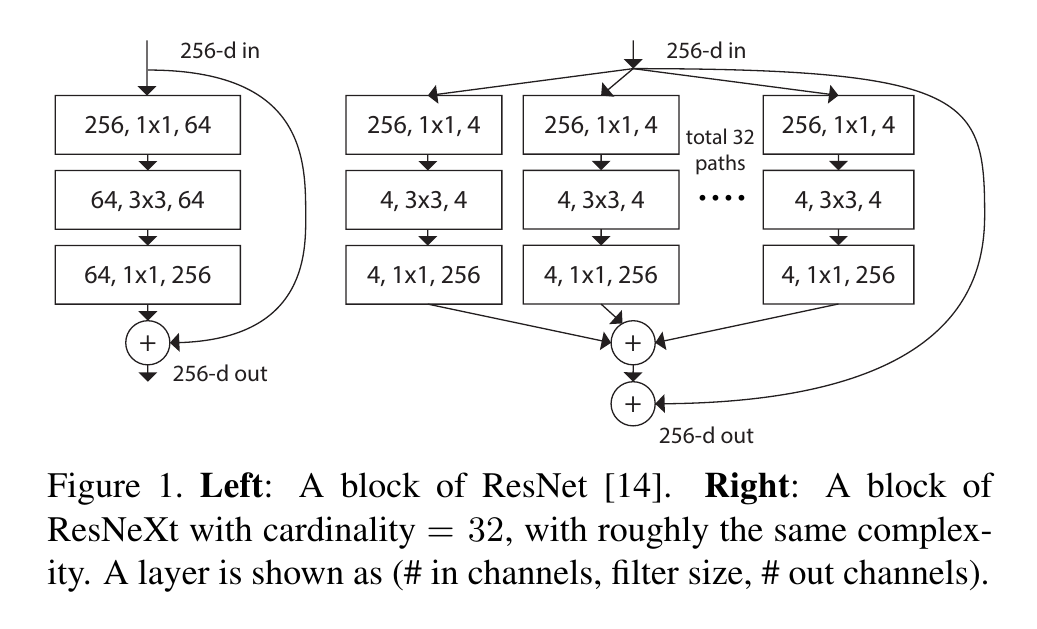
이러한 Inception model이 발전하면서 가장 중요하다고 여겨진 특성은 바로 "split-transform-merge" 전략이다.
이름 그대로 input을 몇개의 lower-dimensional embedding으로 "split"하고
conv3x3 등을 통해 "transform"시키며
concatenation을 통해 "merge"하는 방식이다.
이러한 split-transform-merge 방식은 크고 dense한 layer들의 representational power을 가지면서도 상당히 낮은 computaional complexity를 가지는 것이 파악되었다.
✨해결방법 : Cardinality with same topology
그래서 ResNeXt에서는 위 두가지 방식의 장점들을 합쳤다.
1. split-transform-merge 전략의 장점
2. 같은 shape과 topology라는 rule을 통한 hyper parameter의 감소 및 over-adapting의 방지
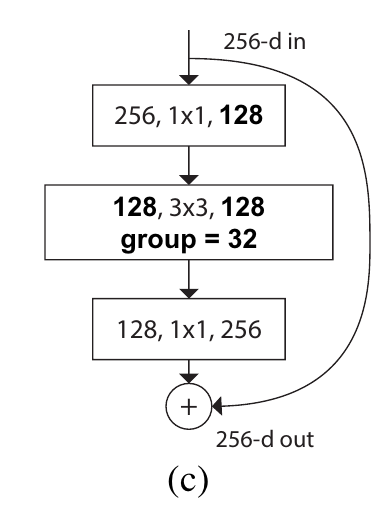
위 두가지를 group convolution이 포함된 bottleneck의 변형 구조의 반복을 통해서 이끌어냈다.
🎨Method
우선 VGG와 ResNet에서 채용했던 기본적인 Rule을 똑같이 적용한다.
- block들은 똑같은 hyper parameter를 공유한다
- feature map size가 1/2로 줄어들 때, width(# of channels)는 2배로 늘어나서 모든 block들의 대략적인 computational complexity를 같게 만든다.
위 2가지 Rule 덕분에, template module만 정의하면 전체적인 architecture는 자연스레 결정된다.
Group Convolution, Cardinality의 역할
기존에는 input의 모든 channel에 대해서 convolution filter를 적용하여 output의 각 channel을 형성했다면, Group convolution에서는 말 그대로 group을 지어서 input의 일부 channel에 conv 연산을 통해 output의 일부 channel을 형성하는 방식이다.
이것이 처음 제안된 것은 Alexnet(2014)으로 알고 있으며, 이러한 방식은 3가지의 장점이 있다.
- 병렬처리에 유리해진다.
- parameter의 개수와 연산량이 감소하여 deeper / wider / more cardinality의 모델을 만들 수 있다.
- 각 그룹에 높은 correlation을 가지는 channel들이 묶여 학습될 수 있다.
