서론
스탠포드 대학에서 진행한 유명한 인공지능 강의인 CS231n강의를 듣기 시작했다.
Deep Learning을 공부함에 있어 중요한 내용들이 많이 포함되어 있으므로 velog를 통해 꾸준히 기록하며 공부하고자 한다.
이미지 분류의 어려움
이미지를 분류하는 일은 사람에겐 쉬운 일이지만, 컴퓨터에겐 굉장히 어려운일이다.
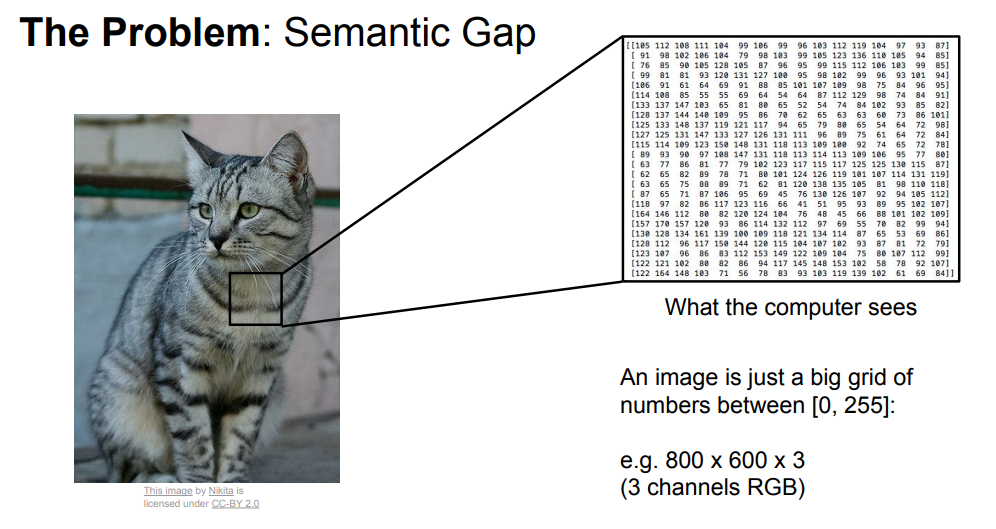
위와 같이 컴퓨터에겐 이미지가 각 픽셀의 숫자로 보이게 되고, 카메라가 움직이게 되면 모든 픽셀이 변경된다.
이미지 분류에 있어 illumination, deformation, occlusion, background clutter, intraclass variation 와 같은 여러 challenging problems가 존재한다.
알고리즘을 통해 이러한 문제들을 해결해야 한다.
이미지를 분류하는 알고리즘
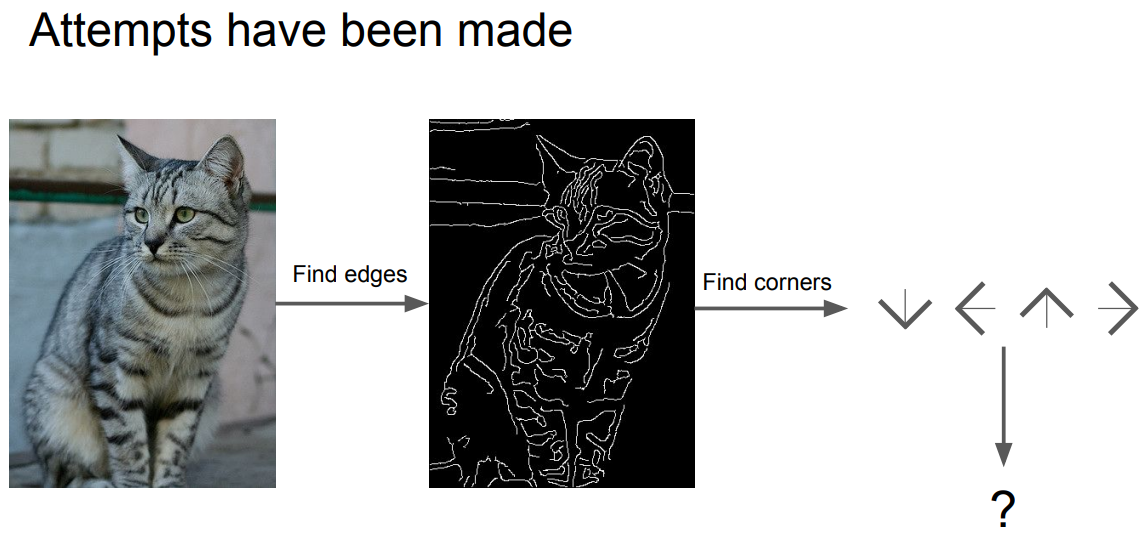
처음엔 이미지의 edges를 찾아 함수를 만들어 인식하려 했으나, 인식하고자 하는 사물의 종류별로 함수를 만들어야 하는 번거로움이 존재했다.
그래서 모든 사물을 분류할 수 있는 방법을 찾기 위해 데이터 중심으로 접근하기 시작했다.

단순히 하나의 function이 아닌, train function과 predict function이 만들어진다.
Nearest Neighbor
데이터 중심으로 접근하는 알고리즘으로 제일 간단한 Nearest Neighbor이 있다.
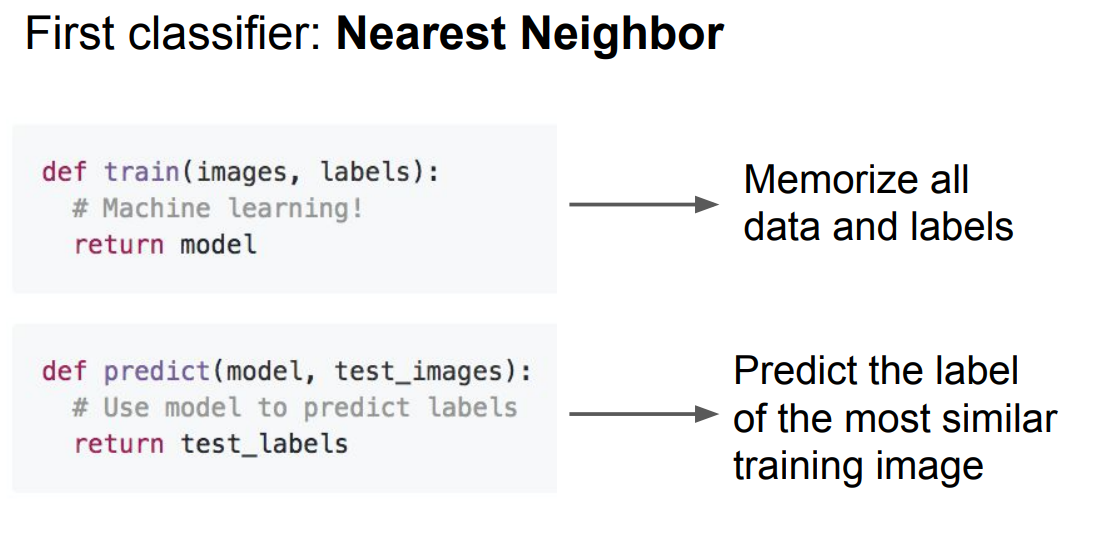
모든 data, labels를 외우고 training image와 가장 유사한 label을 예측한다.
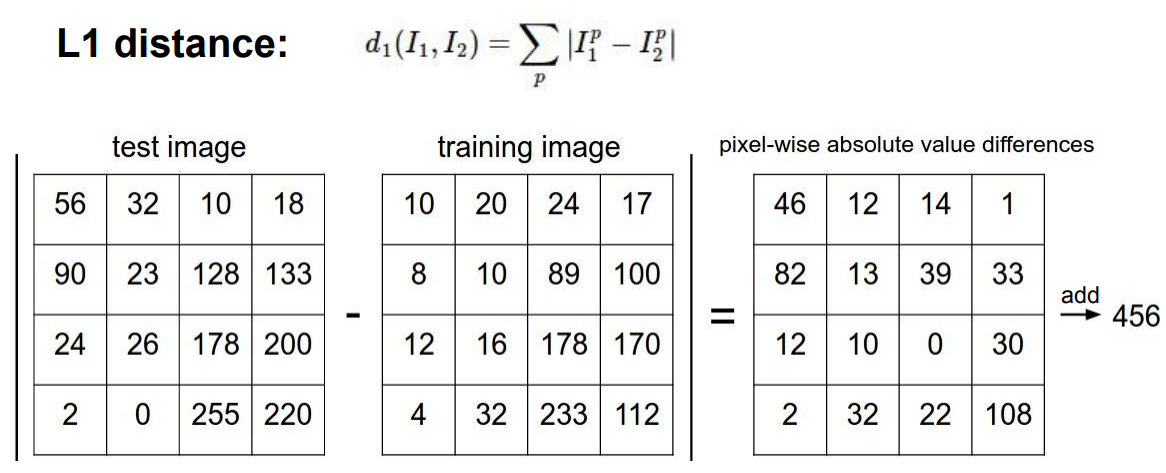
이미지의 유사도를 측정하는 방법엔 L1 distance가 있다.
test image와 training image의 각 픽셀값을 빼고 절대값을 취한 후 모두 더하는 방식이다.
하지만, Nearest Neighbor은 속도 면에서 좋은 알고리즘이 아니다.
training이 오래걸리더라도 prediction을 빠르게 하는 것이 중요한데, NN은 반대이기 때문이다.
(후에 배울 CNN은 training이 오래걸리고 prediction은 빠르다)
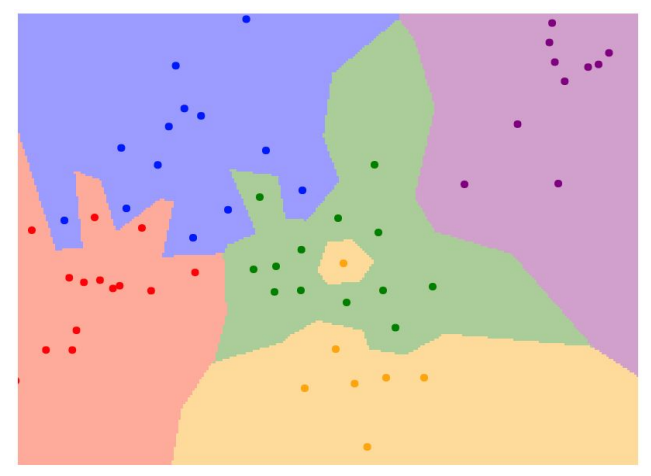
위 그림은 NN의 decision regions를 그린 것이다.(5개의 classes)
초록색 영역안에 노란색 부분이 들어있고, 다른영역을 침범한 색이 존재하는 등 예측이 좋지 않음을 알 수 있다.
K-Nearest Neighbors
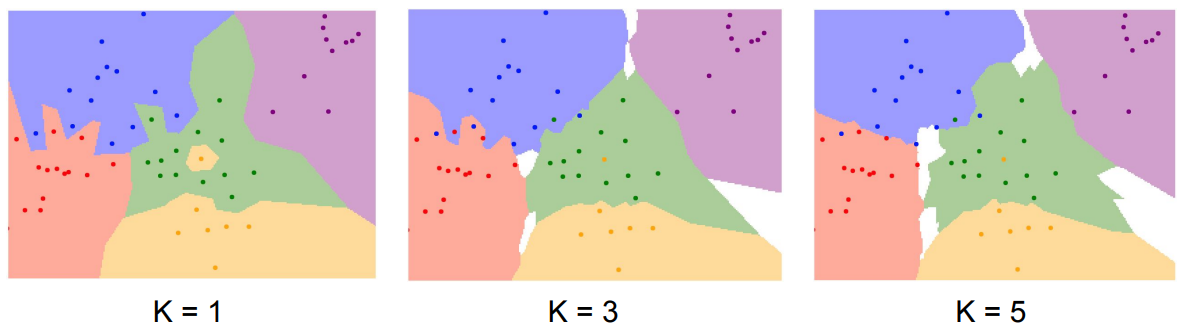
그래서 만들어진 것이 KNN인데, nearest neighbor을 찾는 것이 아닌 K개의 가까운 포인트를 찾아 예측하는 방식이다.
위 그림을 보면 K값이 커질수록 decision boundary가 부드러워짐을 확인할 수 있다.
참고로 흰색 부분의 점에선 어떤 라벨로도 예측하지 않는다고 한다.
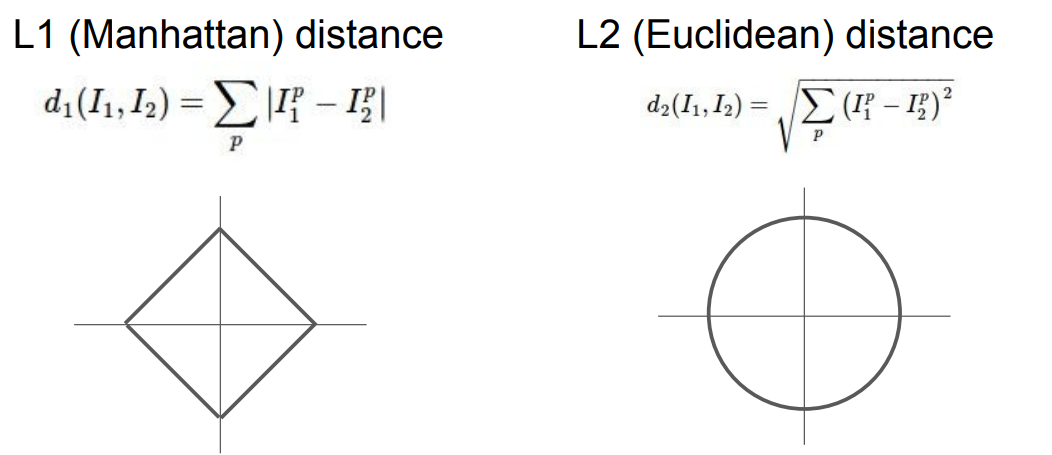
이미지의 유사도를 측정하는 방법엔 L1 말고도 L2 distance가 있다.
L1은 coordinate system에 따라 값이 바뀔 수 있지만, L2는 그렇지 않다.
만약 input feature의 벡터가 개별적인 의미를 가지고 있다면 L1이 유용하고, 의미가 별로 없다면 L2가 유용하다.
Hyperparameters
K값, distance metric(L1,L2)와 같은 정보들을 Hyperparameters라고 한다.
이 parameters는 problem-dependent해서 직접 적용해보고 최선의 값들을 찾아내야 한다.

Hyperparameters를 정할 때 좋은 방법은 train, validation, test 세가지 dataset를 만드는 것이다.
validation set이 따로 필요한 이유: test set은 최종 성능을 평가하기 위해 쓰이고 training의 과정엔 관여하지 않지만, validation set은 최종 모델을 선정하기 위한 성능 평가에 관여한다고 볼 수 있다.
즉, validation set은 training 과정에 관여하여 training이 된 여러가지 모델 중 가장 좋은 하나의 모델을 고르기 위한 set이다
Cross-Validation(교차검증)
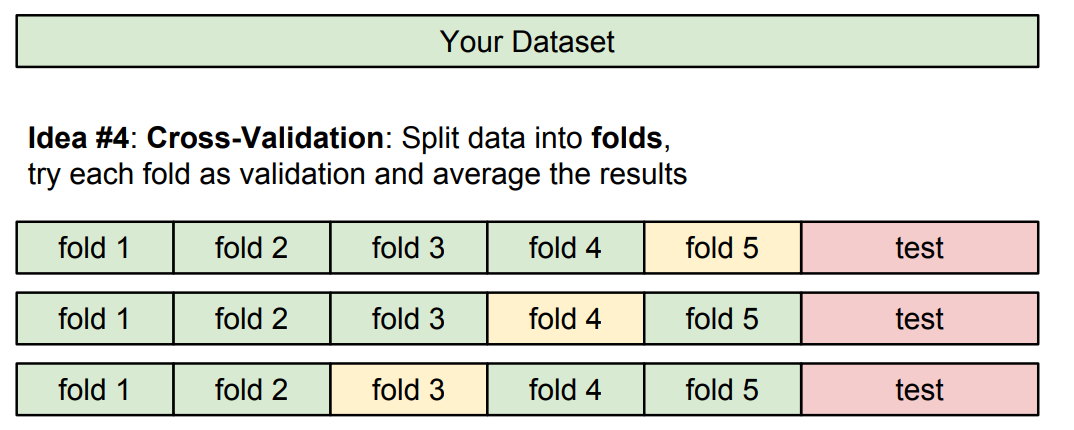
data의 규모가 작을 때 쓰는 방식으로 cross-validation이 있다.
가지고 있는 dataset을 여러 fold로 나눈 후, 그림과 같이 training set과 validation set을 바꿔주며 학습시킨다.
하지만 이 방식은 실제로 deep-learning에서 많이 쓰이진 않는다고 한다.
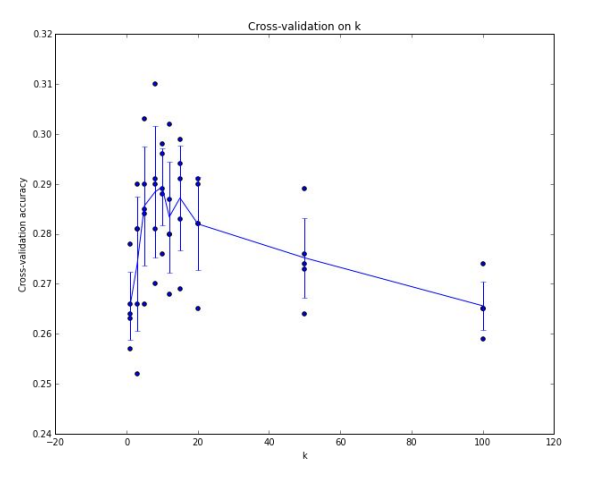
5-fold cross-validation에서 K의 값에 따른 성능을 나타낸 것이다.
K ~= 7에서 제일 잘 작동하는 것을 알 수 있다.
이미지에 KNN을 거의 쓰이지 않는다고 한다.
이유는 너무 test time이 길고, distance metric이 별로 정확하지 않기 때문이다.
또한, 차원이 늘어날수록 필요한 training data가 엄청나게 늘어난다.
Linear Classification
Linear Classification은 간단한 알고리즘이지만 neural network를 만드는 데에 있어 상당히 중요하다.
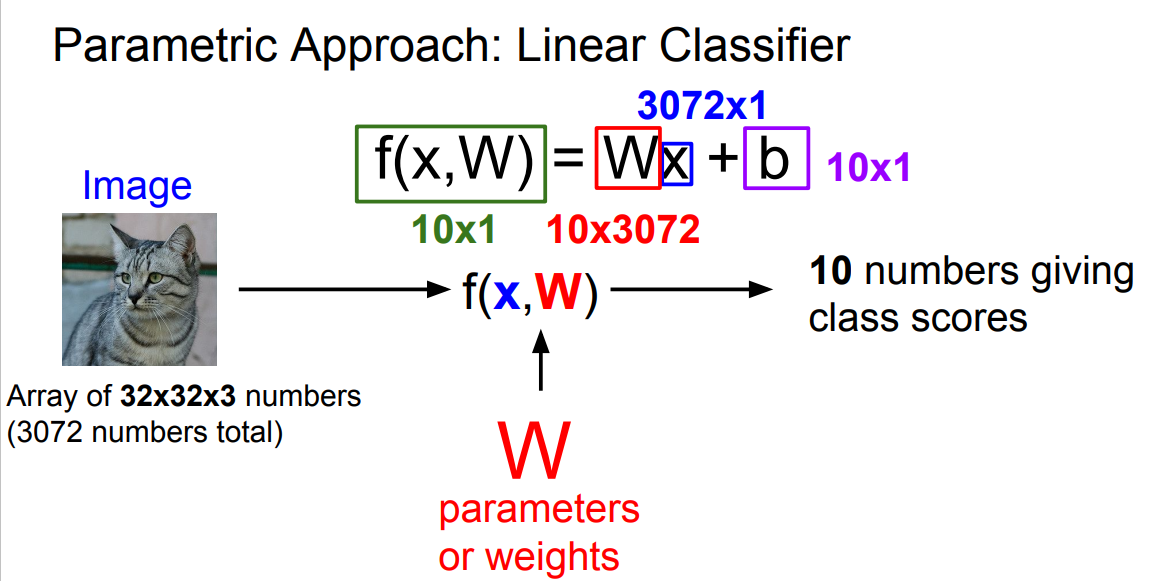
input image,parameters,weights를 넣고 function을 넣으면 class score을 받게 된다.
이 function을 잘 설계하는 것이 중요하다.
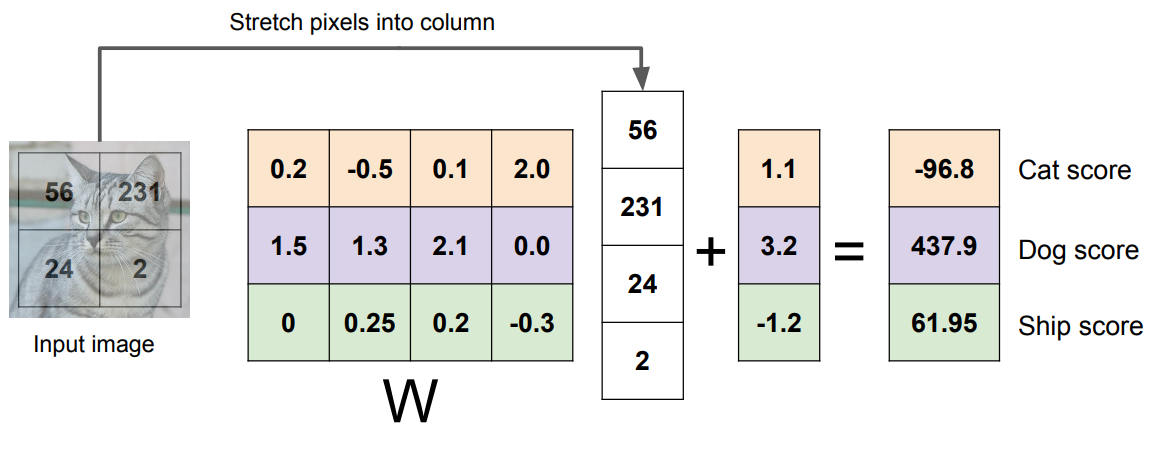
2x2의 input image을 4x1의 열벡터로 바꾸고 weight는 3x4로 만들었다.
마지막엔 막 class별로 점수가 나와있다.
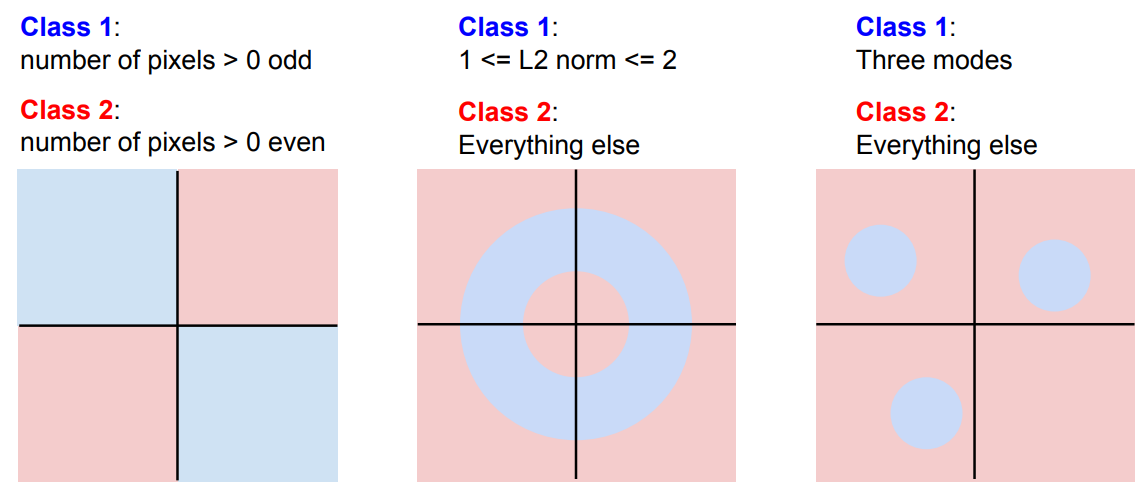
위 그림은 Linear Classification이 어려운 상황의 예시이다.
어떠한 직선을 그려도 분류가 되지 않는다.
