Ch.1 자연어처리 소개
자연어처리란?
자연어처리의 어려움
- 부정확한 답변
- 성별, 인종 편향
- 모호성 (동음이의어, 문맥이 충분한 정보 제공 x)
- 다양한 표현 (같은 대상에 대해 다른 표현 가능)
- 불연속적 데이터 (작은 변화에도 큰 영향, esp. 딥러닝에 치명적)
Ch.2~3 자연어처리와 머신러닝
인공지능과 머신러닝
머신러닝이란?
작업 T와 성능측정 P에 대해 경험 E로 학습하는 것
머신러닝의 종류
- 지도 vs 비지도 vs 준지도 (vs 강화학습)
- 온라인 vs 배치 학습
- 사례기반 vs 모델기반 학습
지도학습
지도학습의 목표
분류: 가능성이 잇는 여러 클래스 중 하나 예측
회귀: 연속적인 숫자 (실수)를 예측하는 것
지도학습 알고리즘들
- K-최근접 이웃 (K-nearest neighbors)
- 선형회귀
- 로지스틱 회귀
- 서포트 벡터 머신
- 결정트리
- 신경망
비지도학습
비지도학습 알고리즘들
군집
- K-평균
- DBSCAN
- 계층 군집 분석
이상치 탐지 & 특이치 탐색
- 원-클래스 SVM
- 아이솔레이션 포레스트
시각화 & 차원 축소
- 주성분 분석 (PCA)
- 커널
- 지역적 선형 임베딩
- T-SNE
연관 규칙 학습
- 어프라이어리
- 이클렛
머신러닝의 작업 순서
- 데이터를 분석
- 모델 선택
- 훈련데이터로 모델 훈련
- 새로운 데이터를 모델에 적용해서 예측
나쁜 데이터
1. 충분하지 않은 양의 훈련 데이터
2. 대표성이 없는 훈련 데이터
3. 낮은 품질의 데이터 (많은 오류)
4. 관련없는 특성
- 특성 선택: 훈련에 가장 유용한 특성을 만듦
- 특성 추출: 특성을 결합하여 더 유용한 특성을 만듦
나쁜 알고리즘
1. 훈련 데이터 과대적합
- 파라미터 수가 적은 모델 선택
- 규제 적용 (모델 단순화)
- 충분하고 품질이 좋은 데이터 활용
- 훈련 데이터 과소적합
- 모델 파라미터가 더 많은 모델 선택
- 더 좋은 특성을 제공
- 모델의 제약을 줄임
자연어처리 기초
자연어처리 시작하기 - 전처리
- 토큰화
- 표제어추출 & 어간 추출
- 표제어: 단어의 뿌리를 의미하는 기본 사전형 단어
- is, am -> be- 어간: 어형 변화의 기초가 되는 부분이자 단어의 의미를 담고 있는 단어의 핵심 부분
- fishing, fished, fisher -> fish
- 불용어처리
- 벡터화
등장횟수 기반의 단어 표현, 희소표현
- one-hot encoding: 단어의 존재 여부로 벡터 표현
- bag of words: 단어의 등장 횟수로 벡터 표현
- TF-IDF: 특정문서에만 더 자주 등장하는 단어에 가중치를 두는 벡터 표현 (중요한 단어에 가중치)
분포 기반의 단어 표현, 밀집표현
- word2vec
- GloVe
- ELMO
- BERT
자연어처리 시작하기 - 전처리(2)
사전 / 어휘집합 (Vocabulary)
코퍼스에 있는 모든 문서, 문장을 토큰화한후, 중복을 제거한 토큰의 지합
- 유한한 단어의 집합
발화 (Utterance)
의사소통 맥락에서 화자 or 작가가 생성하는 말/글의 단위
- 발화는 의사소통 기능이 있는한 완전한 문장, 구 or 단일 단어일 수 있음
파싱 (Parsing)
문법 구조와 의미를 결정하기 위해 문장이나 일련의 단어를 분석하는 프로세스
엔티티 (Entity)
일반적으로 명사구로 텍스트로 표현되는 실제 개체, 개념 or 사물
전통적인 자연어처리의 단계
자연어 문장 → 형태소 분석 → 구문 분석 → 의미 분석 → 화용 분석
형태소 분석
문장을 의미를 가진 가장 작은 단위인 형태소로 분리
- stemming, lemmatization 과정과 동일
구문 분석
문장을 구성하는 성분들간의 관계 분석
- 의존 구문 분석: 문장 구성 성분간의 의존 관계 분석
의미 분석
문장이 나타내는 의미를 분석하여 표현
-
단어 중의성 해소
- 단어가 현재 문장에서 어떤 의미였는지 분석
- ex. 나는 차였다 → tea? car? dump?
-
의미역 결정
- 서술어와 관계있는 논항의 역할을 결정
- ex. 행위의 주체: 나 / 행위의 대상: 사과
화용 분석
문장을 해석해서 화자의 의도를 파악하는 단계
- 상호참조해결
- 그는 어제 사과를 책상위에 두었다. 그것은 아주 빨간 색이었다.
- 그것: 사과
- 화행분석
- 방이 좀 추운 것 같지 않아?
- 의도: 온도 향상 요청
테스트와 검증
홀드아웃 검증
홀드아웃 검증: 훈련세트의 일부를 떼어내어 여러 후보 모델을 평가하는 검증세트로 사용
검증 세트가 작을 경우, 반복적으로 교차 검증 수행
- K-fold Cross Validation
: 일반화된 성능 결과를 얻기 위해 데이터를 여러번 반복해서 나누고 여러 모델을 학습하여 성능을 평가하는 방법
데이터와 학습에의 영향
- 학습 데이터: 학습 사용 (O), 기여 (O)
- 검증 데이터: 학습 사용 (X), 기여 (O)
- 테스트 데이터: 학습 사용 (X), 기여 (X)
자연어처리 기초(2) - 통계 기반의 자연어처리
언어모델
단어들의 확률 분포
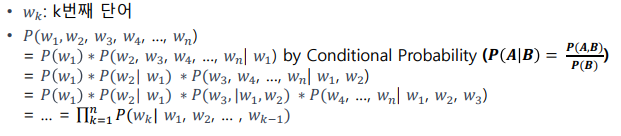
문장에 대한 확률 구하는 법
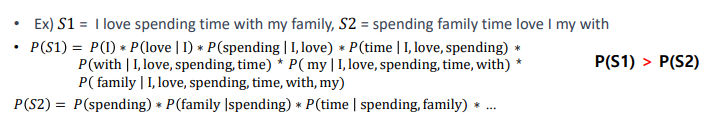
통계적 언어 모델
코퍼스에서 카운트 기반으로 확률을 구함

N-gram
- Uni-gram, Bi-gram, Tri-gram

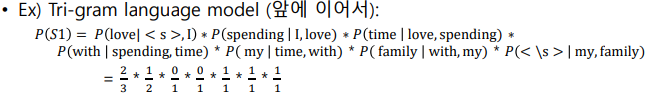
N-gram 언어 모델의 한계
- 정확도 문제: 문자 전체를 다 보는것보다 낮은 정확도를 보일 수 있음
- 희소성 문제: N개의 단어가 항상 코퍼스에서 나타나는 것은 아님
- 상충 문제:
- N이 너무 크면 실제 코퍼스에서 n-gram을 카운트 할 수 있는 확률이 낮아짐
- N이 너무 작으면 근사의 정확도가 현실의 확률분포와 멀어짐
딥러닝 기반의 언어모델
- 비정형 데이터를 사용해서 단어의 확률을 예측하는 딥러닝 모델 학습
- 시퀀스에서 단어를 예측하는 방식에 따라 두 가지 유형으로 분류
- Autoregressive (Causal) Language Model: 다음 단어를 예측하는 언어모델 (GPT, T5, ...)
- Masked Language Model: 특정 단어를 예측하는 언어모델 (BERT, BART, ELECTRA, ...)
- 만들어진 언어모델을 사전학습으로 사용하고 목적 task 데이터셋에 미세조정 (Fine-Tuning)함.
SVM
Support Vector Machine (SVM)
- 분류에 대표적으로 쓰이는 머신러닝 알고리즘
- 분류 오차를 줄이면서 동시에 여백을 최대로 하는 결정 경계를 찾는 이진 분류기
- 선형이나 비선형분류, 회귀, 이상치 탐색에도 사용할 수 있는 머신러닝 모델
- 여백: 결정 경계와 가장 가까이에 있는 학습데이터까지의 거리
- 서포트벡터: 결정경계로부터 가장 가까이에 있는 학습데이터들
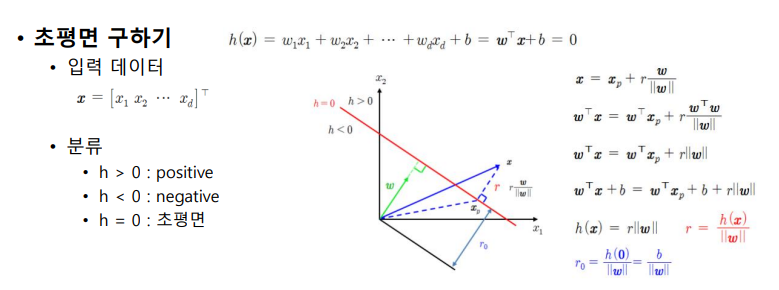
초평면
- 4차원 이상의 공간에서 선형방정식으로 표현되는 결정 경계
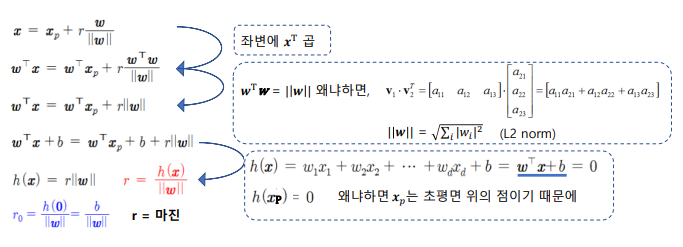
비선형 SVM
- 데이터를 고차원으로 사상(mapping)해서 비선형 특징을 학습할 수 있도록 확장하는 방법
- 고차원으로 변환을 하지 않고 계산할 수 있는 커널함수 사용
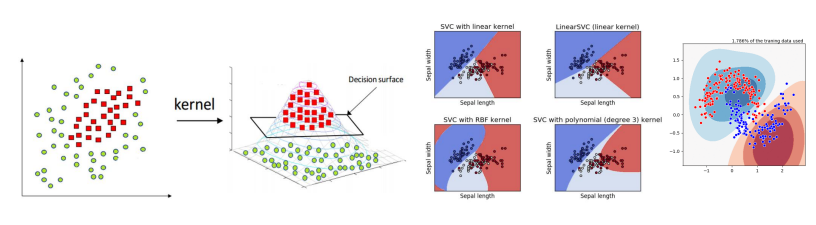
딥러닝 vs SVM
| 딥러닝 | SVM | |
|---|---|---|
| 장점 | - 뛰어난 성능 - 데이터의 복잡한 관계 학습 가능 대규모 데이터를 학습할 수 있음 | - 적은 데이터셋으로도 효과적으로 작동 - 단순한 작업에서 효율적임 학습시간이 빠름 - 오버피팅이 덜 됨 |
| 단점 | - 성능 보장을 위한 많은 비용 필요 - 결과 해석이 어려움 - 오버피팅의 가능성이 있음 | - 커널 선택에 영향을 많이 받을 수 있음 - 노이즈 데이터에 크게 영향 받을 수 있음 - 매우 큰 데이터 처리가 어려움 |
초평면을 잘 찾으려면?
Feature Engineering
- 도메인 지식을 활용하여 데이터에서 특징을 추출하는 작업
- 데이터를 초평면 찾기 좋게 표현하기 위함
자연어처리에서 사용되는 자질
TF-IDF
-
용어
- 문서: d, 단어: t, 문서의 총개수: n
-
tf(d,t)
- 단어의 빈도수, 특정문서 d에서의 특정 단어 t의 등장횟수
- 단어 t가 d에서 나타난 횟수 / d에서의 총 단어
-
df(t)
- 등장 문서 수, 특정 단어 t가 등장한 문서 수
-
idf(d,t)
- df의 역수를 취한 값
- {(전체 문서수) / t}를 포함하는 문서수
, standard version
, scikit-learn version
Ch.4~5 자연어처리 머신러닝 실습

머신러닝 과정 실습 (감정분석)
데이터 탐색 시각화
plt.hist(data['train']['label'], color='red')데이터 준비
sklearn의 fit, transform, fit_transofrm
fit
- 데이터를 학습시키는 메소드
- 데이터의 통계량을 계산하기 위해 사용
- train data 활용
transform
- fit에 의해 계산된 통계량을 기준으로 입력을 변환하는 메소드
- 실제 학습시킨 것을 적용하는 과정
- train, dev, test data에 적용
fit_transform
- fit과 transform을 동시에 하는 메소드
벡터화
vectorizer = CountVectorizer(ngram_range=(1, 3))
vectorizer.fit(train_data['text'])
train_vectors = vectorizer.transform(train_data['text'])
dev_vectors = vectorizer.transform(dev_data['text'])
test_vectors = vectorizer.transform(test_data['text'])선택 훈련
SVM 분류 모델 사용
svm = LinearSVC()
svm.fit(train_vectors, train_data['label'])교차 검증을 사용한 평가
- 전체 데이터를 n개로 나눈 후, n-1개를 학습 데이터로, 나머지 1개를 테스트 데이터로 사용
5-fold 교차 검증 구현
all_data = train_data['text'] + dev_data['text'] + test_data['text']
all_label = train_data['label'] + dev_data['label'] + test_data['label']
all_vectorizer = vectorizer.transform(all_data)
scores = cross_val_score(svm, all_vectors, all_label, cv=5)모델 조정
그리드 탐색
탐색하고자 하는 하이퍼파라미터와 시도해볼만한 값을 조합해서 테스트
- param_grid 설정에 따라 사이킷런이 하이퍼파라미터의 조합으로 모델 평가
param_grid = [{'max_iter':[500, 1000, 5000], 'C':[1, 10, 100]}] # max_iter & c를 변동 하이퍼파라미터로 설정
grid_search = GridSearchCV(svm, param_grid, cv=3)
grid_search.fit(train_vectors, train_data['label'])
print(grid_search.cv_results_['mean_test_score']) # 파라미터 서치 결과
print(grid_search.best_params_) # 최고의 모델 파라미터SVM의 하이퍼파라미터 'c'
- 데이터들이 하나의 초평면으로 딱 나눠지지 않을 수있음
- 기존에는 margin이 아무리 좁아져도 margin 안에 다른 관측치가 못 들어오게 했었음.
- soft margin: margin 안에 관측치가 들어오는 것을 허용
- C가 높아지면 training error를 많이 허용하지 않음 → overfitting의 우려가 있음
- C가 낮아지면 training error를 많이 허용함 → underfitting의 우려가 있음
랜덤 탐색
RandomizedSearchCV
- 가능한 모든 조합을 시도하는 대신 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가
앙상블 방법
각기 다른 형태의 오차를 만드는 여러 모델을 함께 사용
최상의 모델과 오차 분석
- 추가 특성 포함
- 불필요한 특성 제거
- 이상치 제외
솔루션 제시
최적의 하이퍼파라미터를 갖는 모델을 최종 모델로 선택하고 test 실행 결과 확인
final_model = grid_search.best_estimator_
pred_results = final_model.predict(test_vectors)
accuracy = accuracy_score(test_data['label'], pred_results)
print("Accuracy: {.2f}%".format(accuracy * 100))피쳐 엔지니어링을 통한 성능 향상
피쳐 엔지니어링
- 도메인 지식을 활용하여 데이터에서 특징을 추출하는 작업
- 문제 해결에 유용한 관련성 있는 추가 정보를 제공하여 기계 학습 모델의 정확성 개선
자연어처리에 대표적으로 쓰이는 피쳐
- N-gram feature
- TF-IDF feature
형태소 분석 실습
- 토큰화
- 표제어 추출 & 어간 추출
- 불용어 처리
- 벡터화
자연어처리 전처리 실습
- nltk
- 학계 타겟
- 분류, 토큰화, 스테밍, 태깅, 파싱, 시멘틱 추론, 스탠포드 파서 등 가능
- spacy
- 64개 언어 지원 (한국어 x)
- 산업용
- 음성태깅, 종속성 파싱, 명명 엔티티 인식, 토큰화, 규칙 기반 매칭 작업, 워드 벡터 등 가능
- konlpy
- 한국어용 nlp 라이브러리
형태소 단위로 tokenized된 텍스트를 데이터로 사용
train_data = train_data.map(lambda example: {'label': example['label'], 'text': ' '.join(mecab.morphs(example['text']))})
dev_data = dev_data.map(lambda example: {'label': example['label'], 'text': ' '.join(mecab.morphs(example['text']))})
test_data = test_data.map(lambda example: {'label': example['label'], 'text': ' '.join(mecab.morphs(example['text']))})CountVectorizer 토큰 소실 문제 해결
vectorizer = CountVectorizer(strip_accents='unicode', token_pattern=r"(?u)\b\w\w+\b|'\w+")Ch.6~7 딥러닝 기초
기초 수학
이차함수와 최솟값
이차 함수
이면 아래로 볼록
이면 위로 볼록
의 그래프 평행이동
- x축으로 p만큼, y축으로 q만큼 평행이동
- 점 p와 q를 꼭짓점으로 하는 포물선
- 꼭짓점(p, q)은 이차함수의 최솟값이 됨
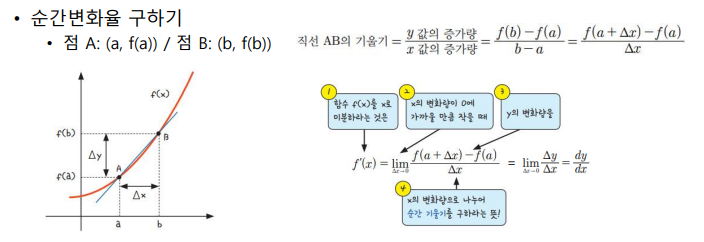
미분
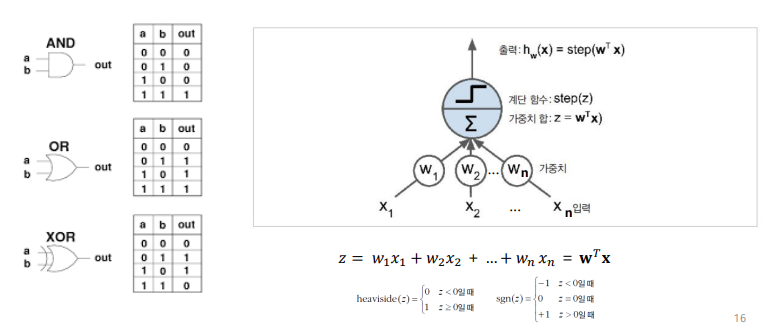
인공신경망
퍼셉트론
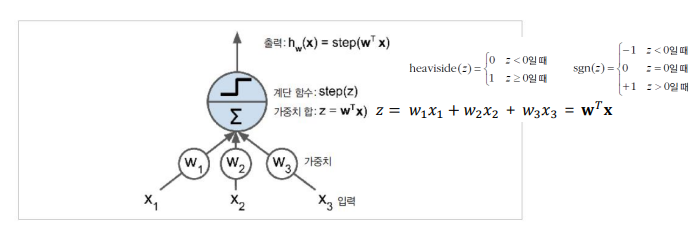
퍼셉트론의 학습
개념: 뉴런이 다른 뉴런을 활성화시킬때, 두 뉴런의 연결이 더 강해짐

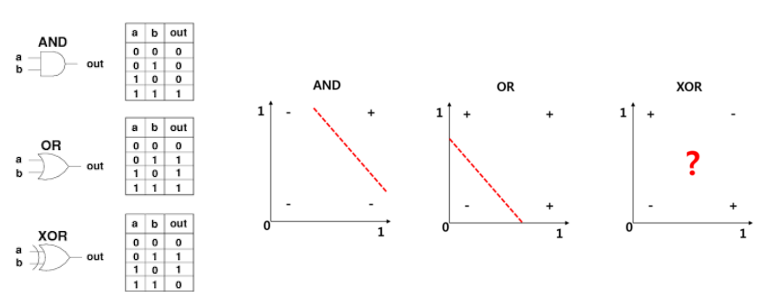
퍼셉트론의 한계
- 논리 게이트 표현
- 퍼셉트론은 XOR 연산문제를 풀 수 없는 한계가 있었음
다층 퍼셉트론의 개념
- 퍼셉트론을 여러개 쌓아올린 형태
- 피드포워드 신경망 (FeedForward Neural Network)의 한 종류
- 입력층에서 출력층으로 신호가 한 방향으로만 전달되는 구조
- 이 구조때문에 역전파를 통해 네트워크 학습
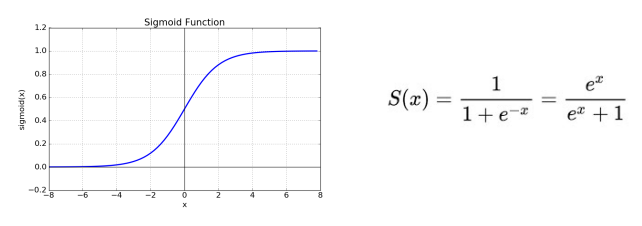
(참고) 시그모이드 함수
- 입력값을 0과 1 사이의 값으로 압축시키는 비선형 함수
- 미분 가능한 함수

오차 역전파 알고리즘
경사하강법
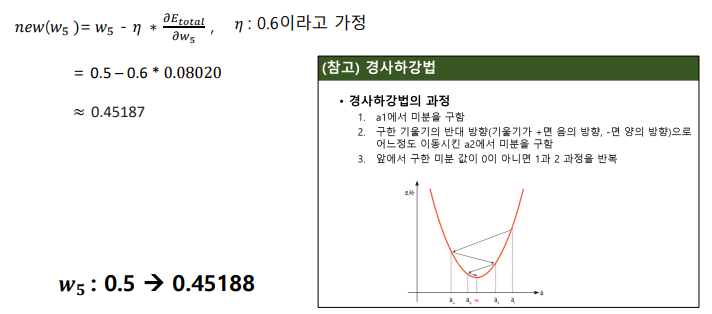
경사하강법의 과정
- a1에서 미분을 구함
- 구한 기울기의 반대 방향 (기울기가 +면 음의 방향 / 기울기가 -면 양의 방향)으로 어느정도 이동시킨 a2에서 미분을 구함
- 앞에서 구한 미분 값이 0이 아니면 1 & 2 과정을 반복
학습률 (Learning Rate)
- 과정 2에서 어느정도 이동할 것인지 결정하는 변수
- 학습률이 크면 많이 이동하고, 학습률이 작으면 적게 이동
다층 퍼셉트론의 학습
순전파와 역전파
- 순전파
- 입력 데이터는 네트워크 입력층으로 전달되어 첫번째 은닉층으로 보내짐
- 해당 층에 있는 모든 뉴런의 출력을 계산하고 결과를 다음 층에 전달
- 2의 단계를 마지막 출력층의 출력을 계산할때까지 반복
- 출력층의 결과와 정답 간의 오차를 계산
- 역전파
- 계산된 오차에 각 출력 연결이 기여하는 정도를 계산
- 연쇄법칙을 적용하여 이전 층의 가중치가 오차에 기여하는 정도 계산
- 2의 방법을 반복하여 입력층까지의 오차 그래디언트 계산
- 경사하강법을 사용하여 오차 그레디언트를 이용해서 네트워크의 가중치를 수정
오차 계산하기
대표적인 손실 함수
- 선형 회귀의 경우
- 평균 제곱 오차 손실 (MSE; Means Squared Error Loss)
- 로지스틱 회귀의 경우
- 교차 엔트로피 손실 (Cross-Entropy Loss)
평균 제곱 오차 손실 (MSE Loss)
- 예측한 값과 실제 값 사이의 평균 제곱 오차
- 데이터가 예측으로부터 얼마나 퍼져있는지를 나타낸 손실 함수

교차 엔트로피 손실 (Cross-Entropy Loss)
-
예측한 확률 분포와 실제 분포 사이의 차이를 최소화하려는 목적을 가진 손실함수
-
예측분포가 실제 분포에 대해 얼마나 잘 맞는지 측정
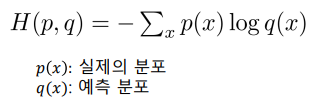
-
Pytorch에서의 Cross Entropy 종류
- BCELoss()
- 이진분류 문제에서 사용되는 손실함수
- CrossEntropyLoss()
- 다중분류 문제에서 사용되는 손실함수
- BCELoss()
BCELoss()
- 이진 분류 문제의 손실을 구할때만 사용
- 출력 레이어에서 하나의 뉴런을 사용하고 sigmoid 함수를 활성화 함수로 사용

CrossEntropyLoss()
- 다중 분류 문제의 손실을 구할때 사용
- 출력 레이어에서 각 클래스마다 하나의 뉴런을 사용하고 softmax 함수를 활성화 함수로 사용

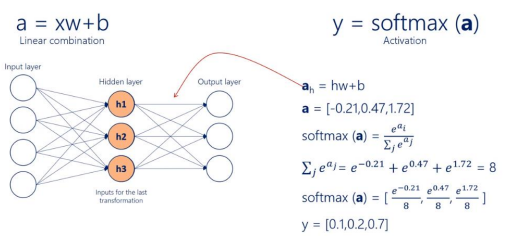
(참고) 소프트맥스 함수
- 다중 클래스 분류 문제에 자주 사용되는 함수
- 각 클래스에 대한 예측 확률을 계산하는데 사용
- 출력층의 각 뉴런에 대한 입력값을 0과 1사이로 변환하고, 이들 값의 합이 1이 되도록 정규화
- 해당 값이 클래스의 예측 확률로 사용됨
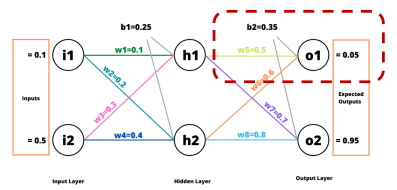
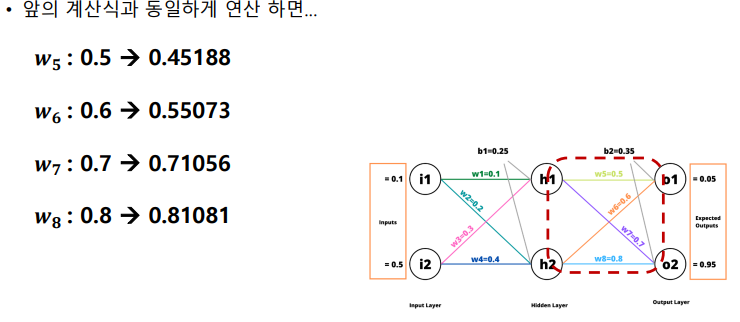
오차 역전파 계산
순전파 (Forward Pass)
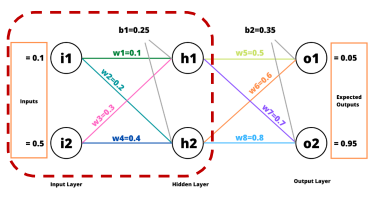
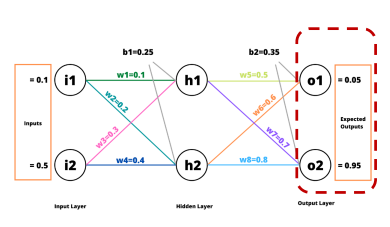
역전파 (Back Propagation)
에 가 미치는 영향
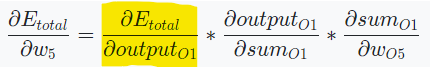
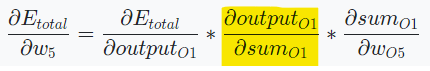
참고
,
sigmoid 함수의 경우, 미분하면 f(x)(1-f(x))로 계산할 수 있다.

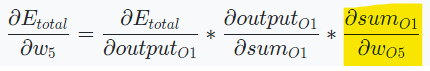
에 가 미치는 영향
경사하강법을 사용하여 오차 그레디언트를 이용해서 네트워크 가중치 수정


딥러닝 학습하기
딥러닝 학습을 위한 용어
Epoch
- 모델을 학습시키는 동안 전체 데이터셋을 몇번 학습할 것인지 정의하는 하이퍼파라미터
Iteration
- 1 epoch를 진행하기 위해 몇번의 파라미터 업데이트가 되는지 의미하는 숫자 (자동으로 설정)
- ex. 데이터 샘플 수가 100이고, 배치 사이즈가 10이면 iteration: 10
Optimizer
- 최적화 알고리즘 (ex. 경사하강법)
- 속도/효율이 개선된 다른 방법들이 존재함
- Momentum, SGD, AdaGard, RMSProp, Adam 등
- RMSProp & AdaGard를 함께 사용한 Adam Optimizer을 많이 사용
Activation Functions
- 활성화 함수
- 시그모이드 or 소프트맥스 외에도 다양한 함수들이 존재함
- Tanh, ReLU, GELU 등
- GPT는 GELU 활성화 함수로 사용
딥러닝 학습하기 (실습)
훈련세트에서 훈련하고 평가하기
import torch
import torch.nn as nn
import torch.optim as optim
# MLP 모델 정의
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
#Todo --> layer 정의, 모델 정의
self.layer1 = nn.Linear(input_size, hidden_size)
self.layer2 = nn.Linear(hidden_size, int(0.5*hidden_size))
self.layer3 = nn.Linear(int(0.5*hidden_size), output_size)
self.gelu = nn.GELU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
#Todo --> 모델을 실행
out1 = self.layer1(x)
out2 = self.gelu(out1)
out3 = self.layer2(out2)
out4 = self.gelu(out3)
out5 = self.layer3(out4)
out6 = self.softmax(out5)
return out6output layer는 활성화함수로 gelu가 아닌 softmax를 쓴 것에 유의!
# 하이퍼파라미터 셋팅
input_size = len(vectorizer.vocabulary_) # input size
hidden_size = 100 # hidden size
output_size = 2 # output size is 2 (positive/negative)
learning_rate = 0.00001
batch_size = 128
num_epochs = 10# 모델 정의 (초기화)
model = MLP(input_size, hidden_size, output_size)
device = torch.device("cuda") # use GPU
model = model.to(device)
# optimizer, loss function 정의
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_function = nn.CrossEntropyLoss()
# dev_vectors와 dev_data['label']을 텐서 자료형으로 변환 -> 딥러닝 코드 학습하고, 계산하기 위해서
dev_tensors = torch.cuda.FloatTensor(dev_vectors.toarray(), device=device)
dev_labels = torch.tensor(dev_data['label'], dtype=torch.long, device=device)텐서 자료형으로 변환
- train: 학습하면서
- dev: 학습 전에
- test: 평가 전에
# 학습 시작 (총 num_epochs 만큼)
for epoch in range(num_epochs):
# model을 학습하겠다고 선언
model.train()
# 출력용
epoch_loss = 0
best_accuracy = 0
# train_vectors를 텐서 자료형으로 변환
train_tensors = torch.cuda.FloatTensor(train_vectors.toarray(), device=device)
# batch size 단위로 학습 진행 --> batch size에 대해서 한번 파라미터 업데이트
for i in range(0, len(train_tensors), batch_size):
# batch 단위 데이터 생성
batch_data = train_tensors[i:i+batch_size]
batch_labels = torch.tensor(train_data['label'][i:i+batch_size], device=device)
# 1. 순전파
outputs = model(batch_data)
# 2. 오차 계산
loss = loss_function(outputs, batch_labels)
# 3. 역전파
optimizer.zero_grad()
loss.backward()
# 4. 가중치 업데이트
optimizer.step()
# loss 저장 for 출력
epoch_loss += loss.item()
# 매 epoch마다 dev 성능 측정
# 모델을 평가용으로 셋팅
model.eval()
with torch.no_grad():
dev_outputs = model(dev_tensors)
dev_preds = torch.argmax(dev_outputs, axis=1)
dev_accuracy = torch.sum(dev_preds == dev_labels).item() / len(dev_labels)
# save best model on dev data
if dev_accuracy > best_accuracy:
best_model = model
best_accuracy = dev_accuracy
print(f"Epoch {epoch+1}, Accuracy: {dev_accuracy} , loss: {epoch_loss/len(train_tensors)}")테스트 세트로 시스템 평가하기
from sklearn.metrics import accuracy_score # Accuracy 측정 함수 import
final_model = best_model # dev에서 성능이 제일 좋았던 모델
test_tensors = torch.cuda.FloatTensor(test_vectors.toarray(),device=device)
pred_results = final_model(test_tensors) # 최종 모델로 test 데이터 예측
pred_labels = torch.argmax(pred_results, axis=1)
accuracy = accuracy_score(test_data['label'], pred_labels.tolist()) # 정확도 측정
print("Accuracy: {:.2f}%".format(accuracy*100)) # 정확도 출력 