
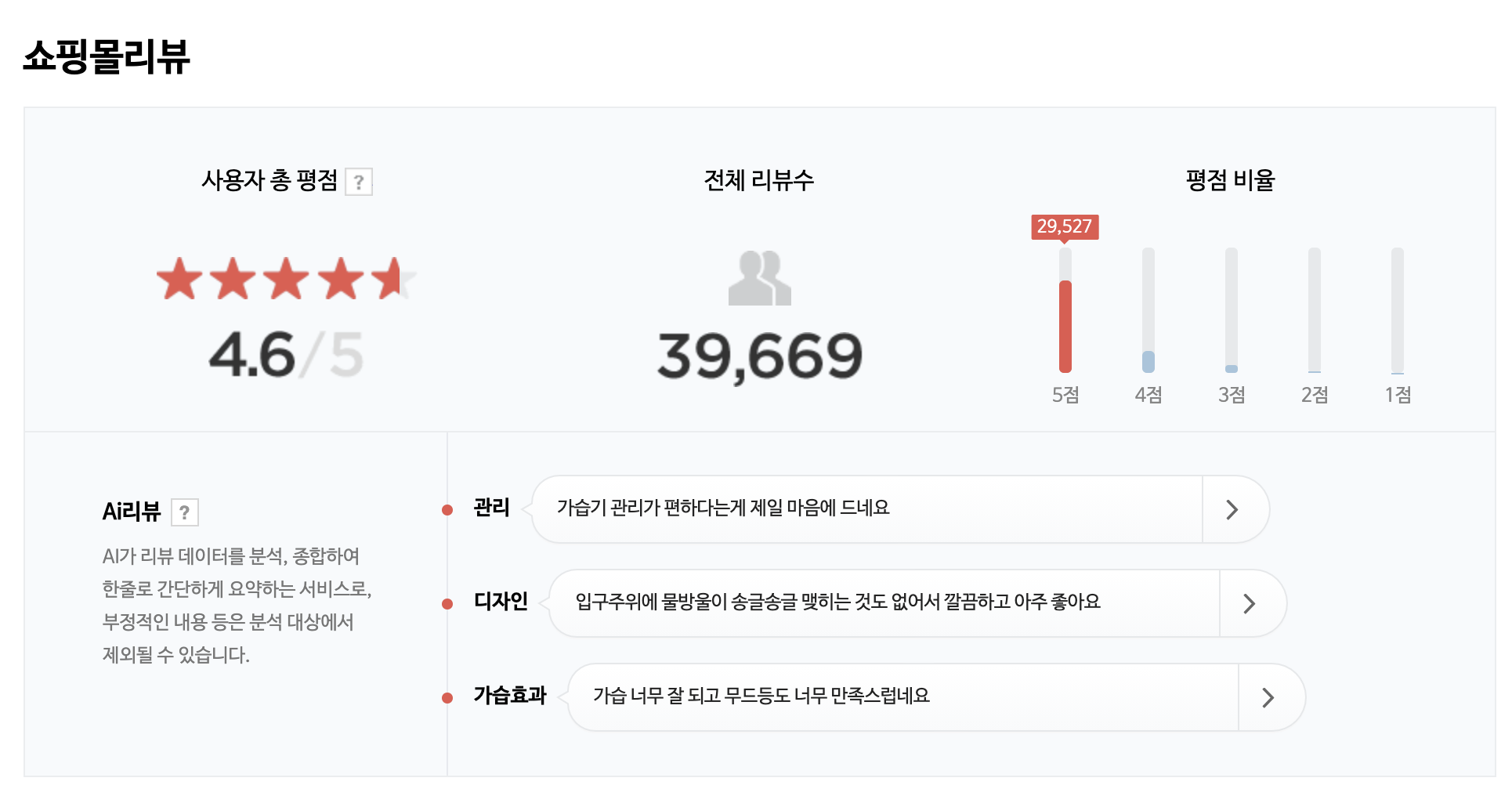
새롭게 도입된 리뷰 요약
네이버 쇼핑몰 리뷰에 새로운 부분이 생겼다. 아래처럼 4만 개의 리뷰들 중 주요 내용들을 뽑아서 주요 단어(aspect)별로 한 줄 의견요약을 해서 보여준다. 관련 기사: 네이버AI, 쇼핑리뷰 한줄로 요약
올해 상반기 장소 평가에서 별점을 폐지한다고 했던 방향의 연장선이다. 간단히 별점으로만 어떤 스토어나 상품을 평가하지 않고 다양한 의견들을 쉽게 눈에 들어오도록 만들어주는 것이다.
요약 프로세스
관련 기사에는 요약 프로세스가 잘 정리되어 있다.
1. 주요 키워드 추출: 수만 개의 리뷰 덩어리 속에서 주요 키워드를 추출해낸다. AE(Aspect Extraction)이 될 것이다. 수많은 AE 데이터들을 학습시킨 모델을 사용할 수도 있을 것이고, 간단하게 명사 토큰을 추출한 후 TF-IDF 처럼 해당 제품 리뷰에서만 특별하게 더 자주 등장하는 단어들을 뽑아내는 과정을 거칠 수도 있을 것이다.
2. 유사 문장 클러스터링: 의견들을 종합적으로 봐야 하기 때문에 크게 어떤 종류의 의견들이 있는지 클러스터링한다. Sentence BERT나 LSTM과 같은 seq 모델로 문장을 공간에 embedding 시키는 방식이 있을 것이고, 아니면 BoW 기반으로 등장 단어에 따라 묶어줄 수도 있을 것이다. 두 가지를 적절하게 혼합해서 선정된 벡터들을 클러스터링 해보면 좋을 것 같다.
3. 요약문 생성: 어떤 데이터를 input으로 요약문을 생성하는지 모르겠다. 나라면 1)주요 대형 클러스터를 서너 개 뽑은 후 2)각 클러스터를 대표하는 문장들을 선정(또는 생성)하고 3)generation을 시도해볼 것 같다.
모든 과정에서 초거대 언어모델(hyper CLOVA)이 유용하겠지만 특히 이 과정에서 중요한 역할을 할 것이다. 리뷰 데이터, 그리고 해당 도메인, 상품의 리뷰로 튜닝을 시키지 않더라도 자연스러운 요약문이 생성되려면 큰 모델이 중요하기 때문이다.
4. 검수: 아마 기존에 활용하던 댓글 클린봇과 같이 비문이나 비속어들을 classification하는 모델을 사용할 것이다. 이러한 데이터들은 네이버에 워낙 많을 것이다.

더 편리해질까?
사용자 입장에서는 기존과 큰 차이가 있을 것 같지는 않다. 리뷰를 살펴볼 때 다각도로 평을 보고 싶다. 부정적인 이야기들도 보고 싶고 사람마다 편리/불편했던 케이스들을 다양하게 접해야 도움이 될 것이다. 수만 개의 리뷰를 한두 문장으로 보여주는 것 자체는 그닥 유용하지 않을 것 같다.
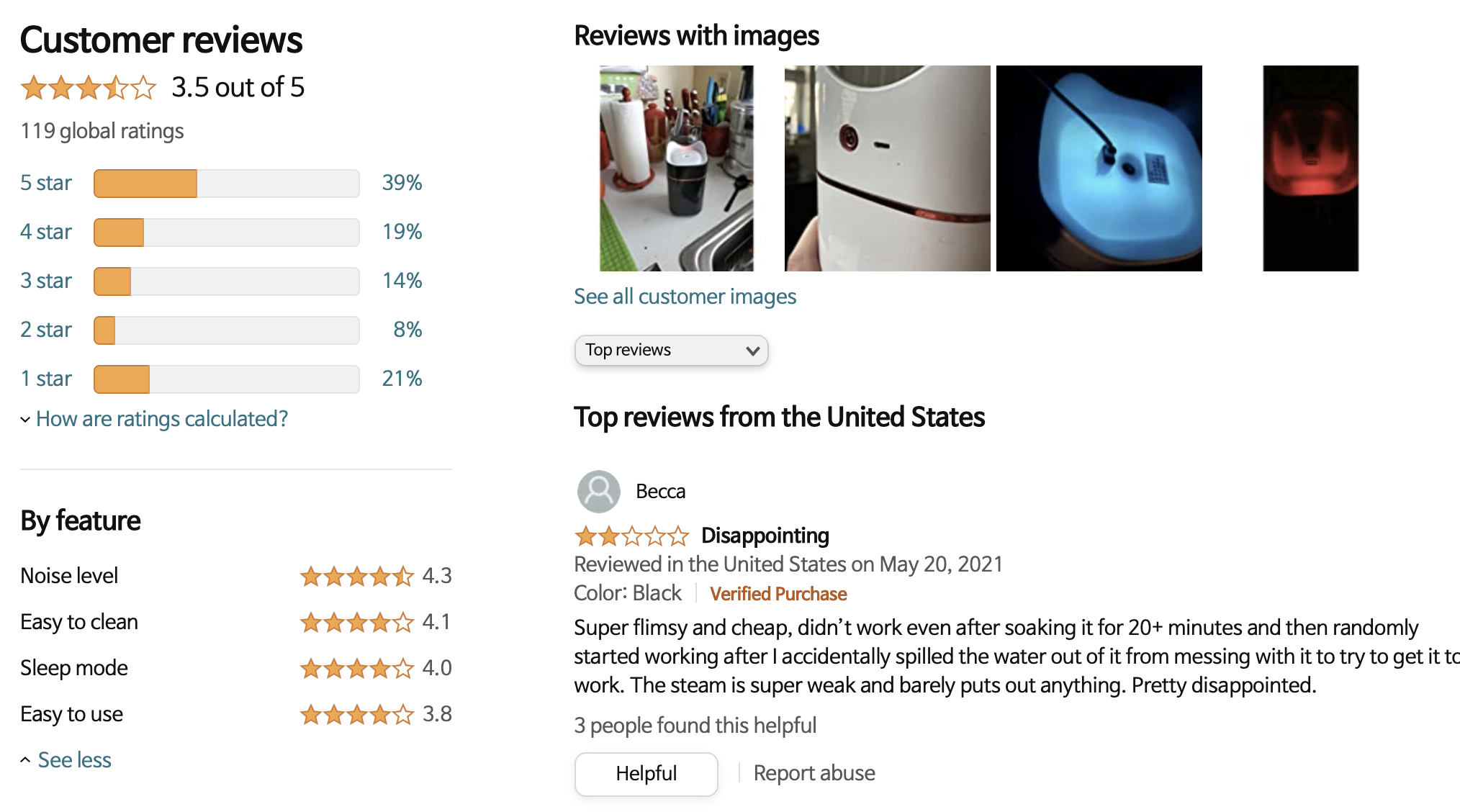
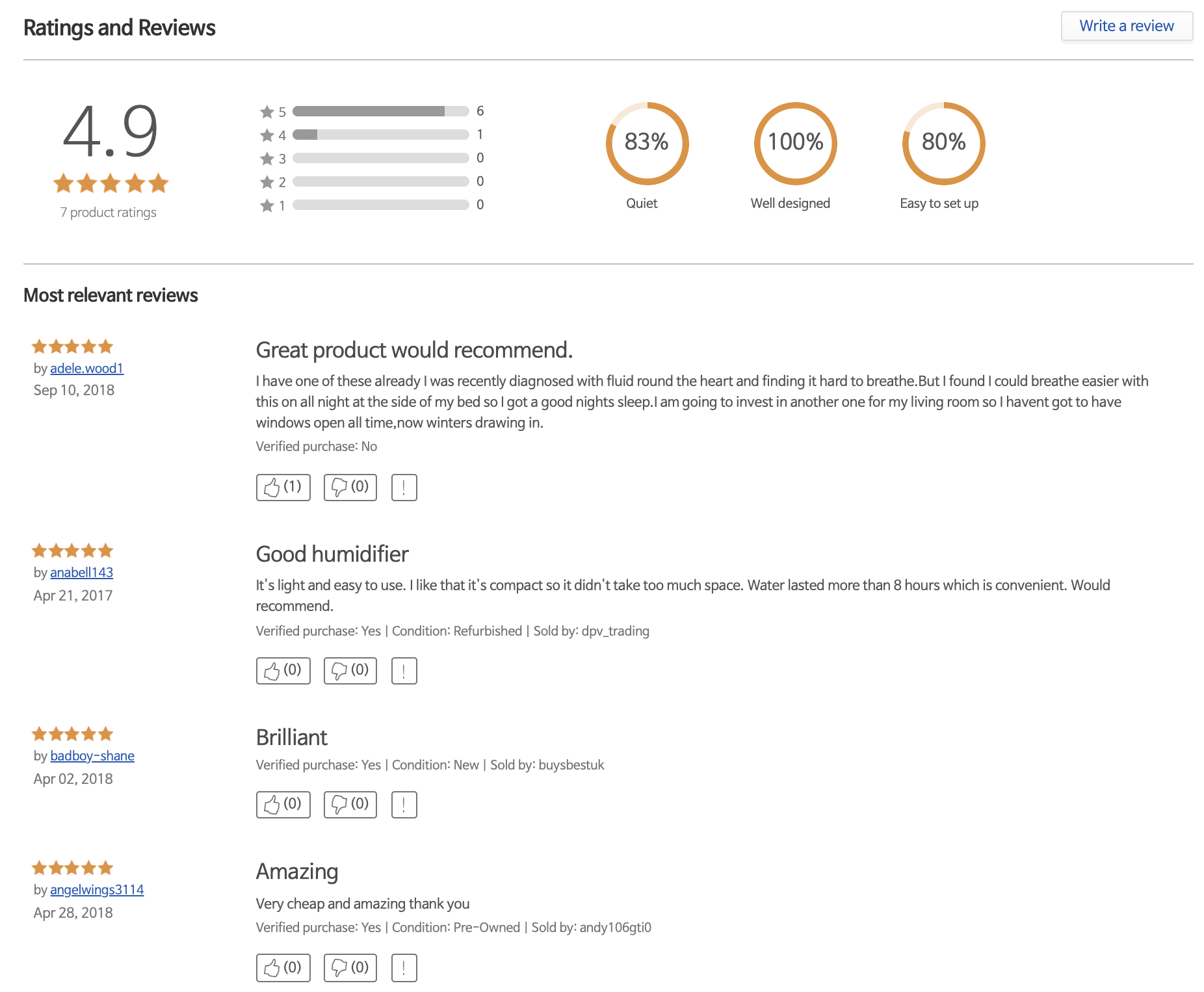
위는 아마존, 아래는 이베이의 리뷰 노출 방식이다. 둘 다 aspect별로 별점을 간단히 보여준다. 아마 리뷰 작성 전에 주요 카테고리별 별점을 선택하도록 하여 간결하게 데이터를 모을 것이다. 네이버는 더 나아가 직접 카테고리나 별점을 필터링해서 리뷰를 파악할 수 있는데, 사실 이 정도만 되면 원하는 정보를 쉽게 얻는 데 문제가 없다.
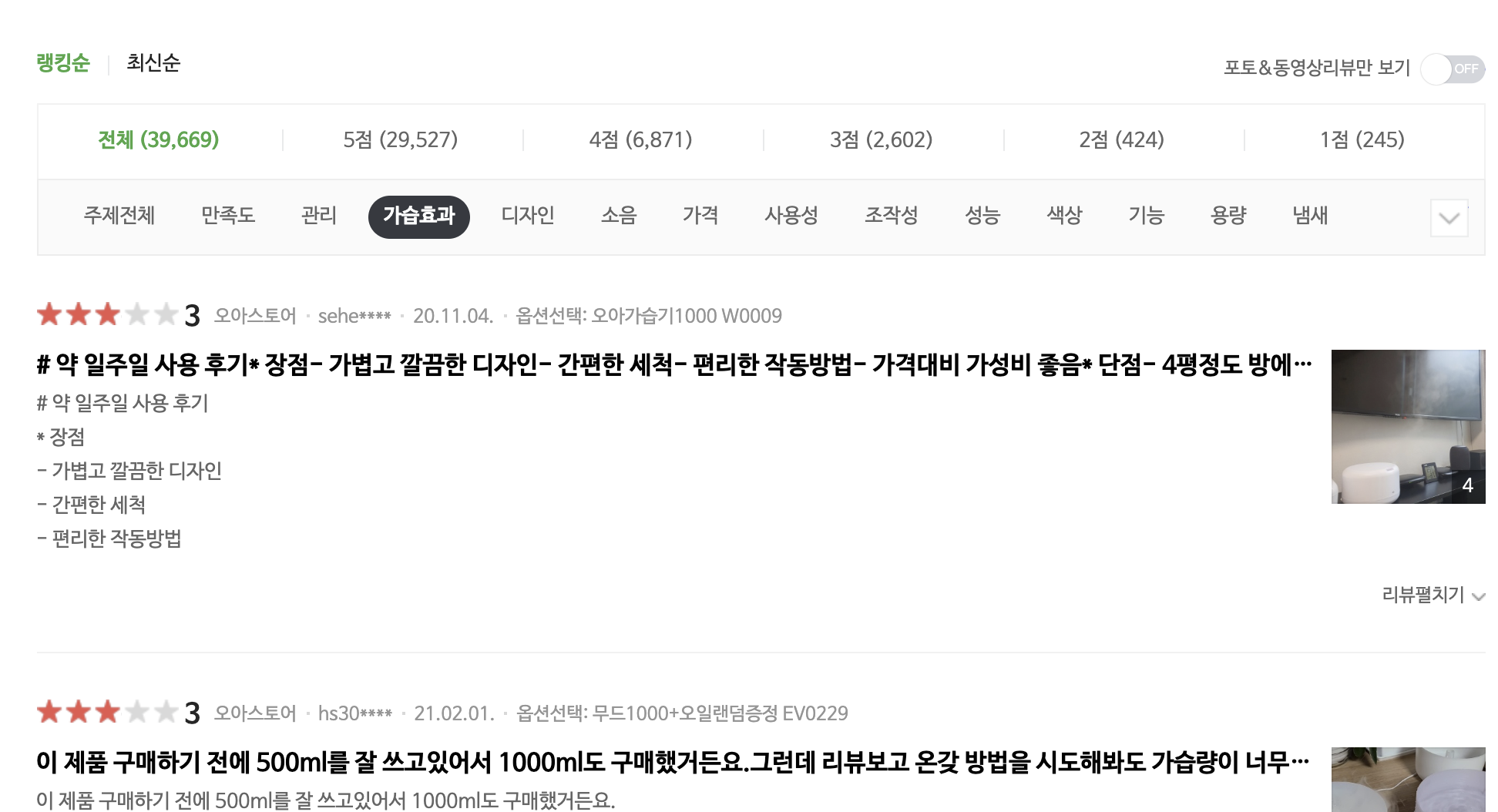
그럼에도 리뷰의 Summarization이나 Opinion Extraction이 필요한 이유는?
개인적으론 추천시스템이 중요한 이유 중 하나라 본다. 기존의 시스템이 메타 정보나 다른 유저의 정보(collaborate)에 의존하여 이뤄졌다면, NLP가 여기에 더할 수 있는 역할은 수많은 유저가 남긴 비정형적인 리뷰 데이터를 추가로 활용하여 더 다양한 아이템이 추천될 수 있도록 하는 것이다.
A 상품, 그리고 A 상품의 다섯 가지 측면(예를 들어 만족도, 가습효과, 디자인, 가격, 조작성)에 대한 의견을 잘 요약할 수 있다면, 이를 기반으로 디자인을 중요하게 생각하는 유저, 가격을 중요하게 생각하는 유저에게 눈에 띌만한 상품을 추천해주는 데 큰 도움이 될 수 있을 것 같다. 기존 패턴으로 보아 디자인을 중요하게 여기는 구매자에게 아래와 같은 추천 문구와 함께 피드에 띄워준다면 클릭할 확률이 높아지지 않을까?
이 상품은 다른 구매자들로부터 "무드등 색이 다양해서 좋다"는 평을 많이 받고 있습니다.
