
이 글은 2021년 3월 27일에 네이버블로그에 작성했던 내용을 조금 수정하여 작성.
쇼핑몰 뿐 아니라 장소, 서비스제공자(택시기사, 맘시터 등), 영화 등 모든 상품과 서비스에 대해 리뷰가 넘친느 시대이다. 플랫폼은 고도화된 방식으로 이 리뷰들을 분류/분석해서 쉽게 사용자들에게 보여주려 한다. Aspect-Based로 어떻게 이 리뷰들을 정리해서 보여주고 있는지 살펴보았다.
Amazon: 카테고리별 별점과 주요 aspect 단어 match
아마존은 자주 등장하는 주요 aspect term을 추출하고 (aspect extraction) pre-define된 카테고리에 따른 star rating을 제공한다. 아래는 수분 크림에 대한 리뷰를 보여주는 방식이다. 왼편에 'by feature'로 moisturizing, sheerness, thickness 등의 카테고리에 따른 별점을 공개하고 있다. (아마 리뷰에서 추출이 아닌 사용자에게 별점을 선택하라고 했을 것이다. 사용자가 고른 별점은 카테고리A에 대해 5점을 줬는데 모델이 분석한 리뷰 내용은 A에 대해 부정적(0점 수준)이라면 일관성이 낮은 리뷰로 분류할 수도 있지 않을까?)
그리고 리뷰 상단에는 'Read reviews that mention' 파트를 만들어서 'eye cream', 'face wash', 'dark circles', 'sensitive skin' 등의 주요 aspect term을 선택할 수 있도록 해두었다. 단순히 빈도에 의한 추출일지 아니면 aspect extraction 모델을 활용한 추출일지는 알 수 없지만 이러한 term이 등장하는 리뷰들을 필터링 해서 볼 수 있다는 점이 매우 유용하다.
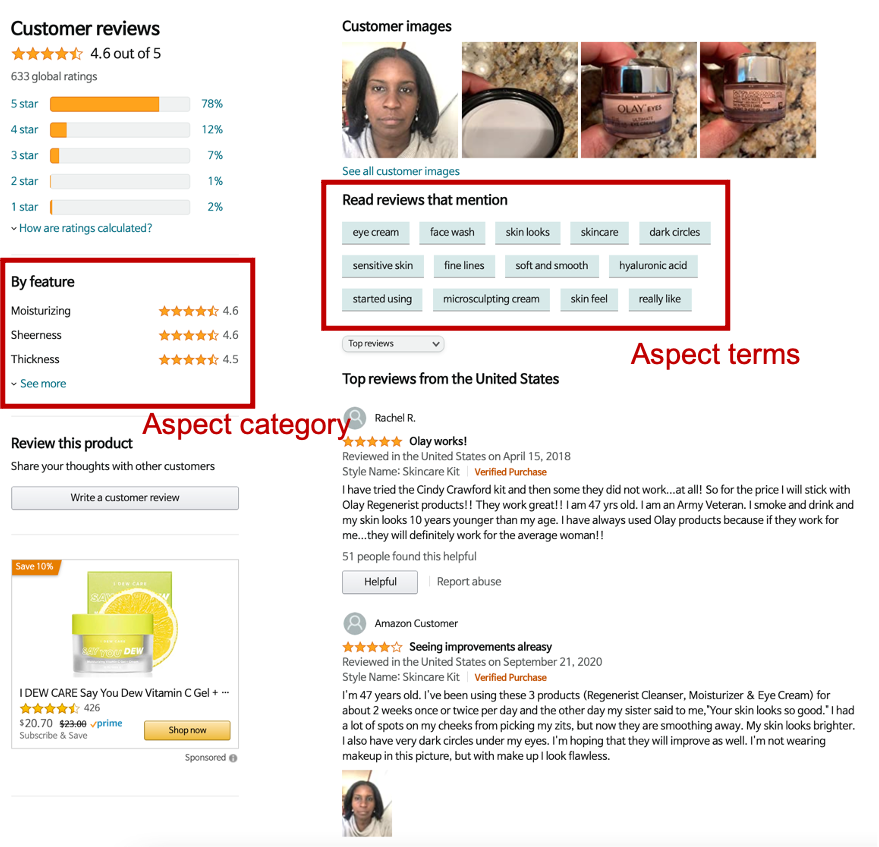
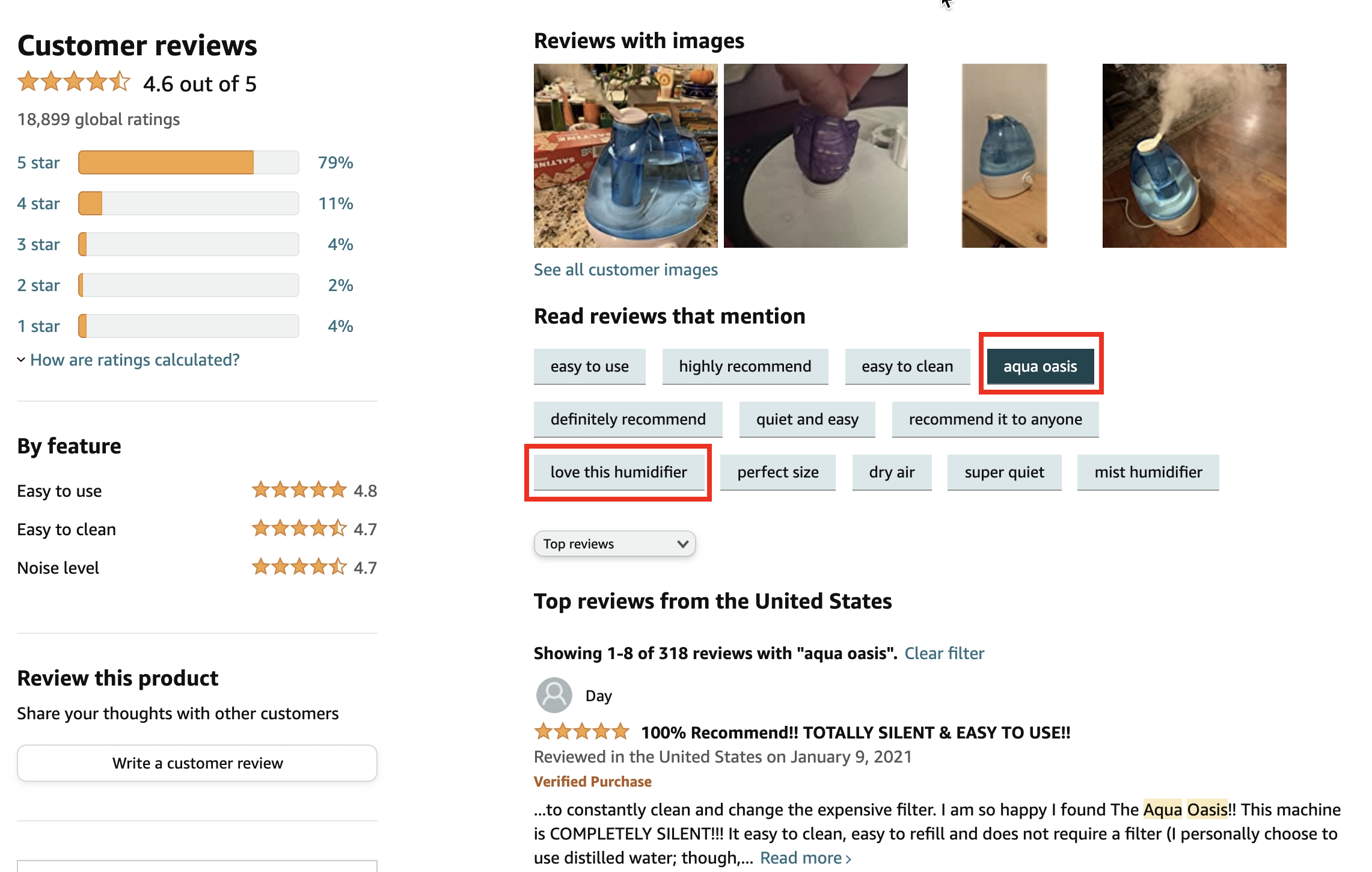
다만, aspect에 따른 리뷰 필터는 단순하게 그 단어가 들어있는 리뷰들을 걸러서 보여주고 있었다. 리뷰에 자주 등장하는 표현들을 선택할 수 있도록 보여주고, 선택했을 때 그 단어가 직접 언급된 리뷰들을 보여줬다. 유사한 느낌의 연관 단어들까지 잡아주는 경우는 찾아보지 못했다.
그리고 그 단어들도 단순 빈도로 추출한 느낌이 있었는데, 아래 가습기 리뷰를 보면 "aqua oasis"라는 브랜드명이 그대로 들어있었다. 사실 이미 그 브랜드의 상품 페이지에 들어왔을 때엔 그 브랜드 이름이 관한 내용보다는 상품에 관한 내용이 궁금할 텐데 리뷰가 워낙 unstructured 데이터이기 때문에 단순 빈도로 추출해주는 느낌을 받았다.
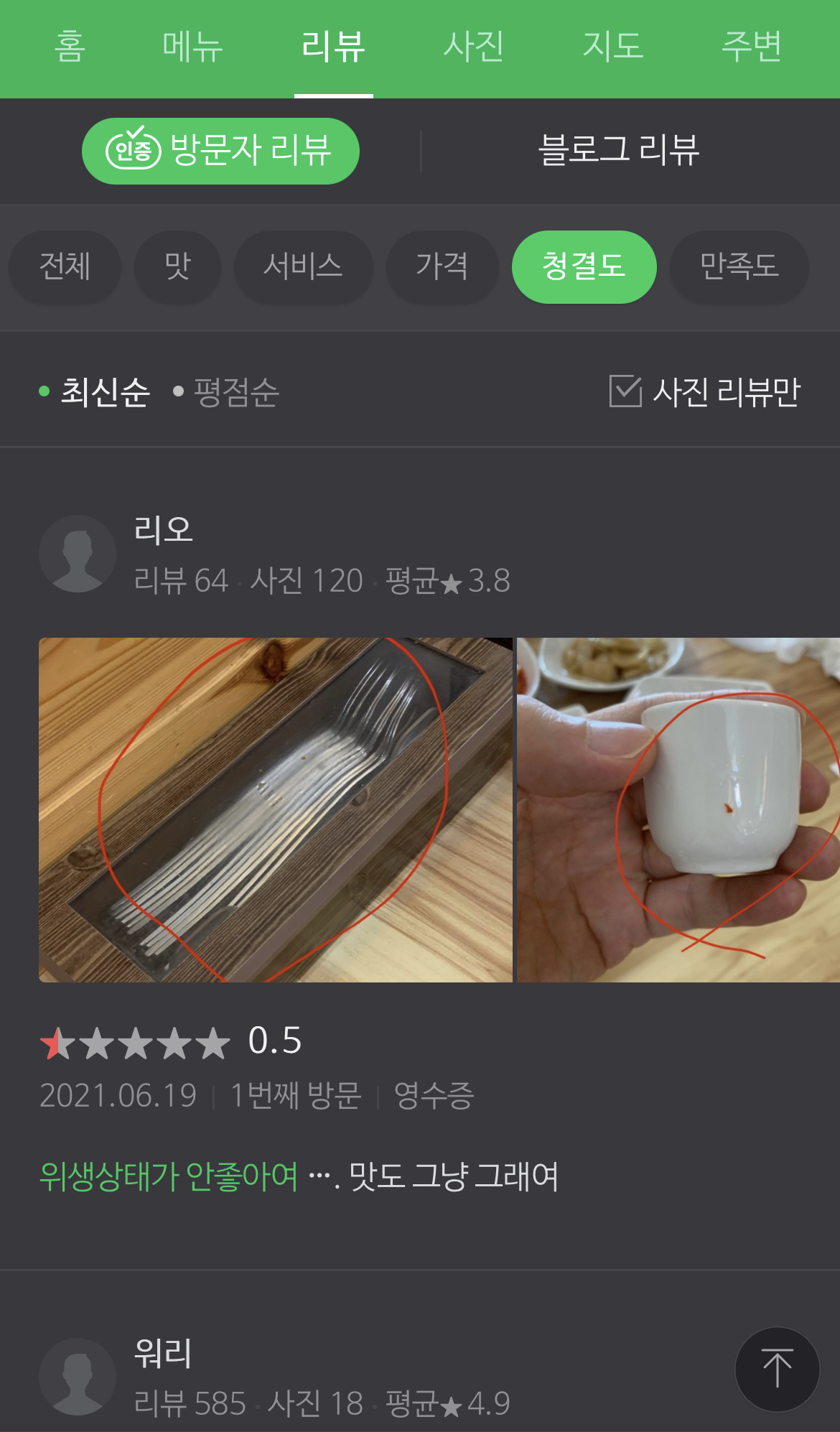
NAVER: 주요 카테고리와 관련된 단어도 찾아주는 고도화된 한국어 이해(NLU) 모델
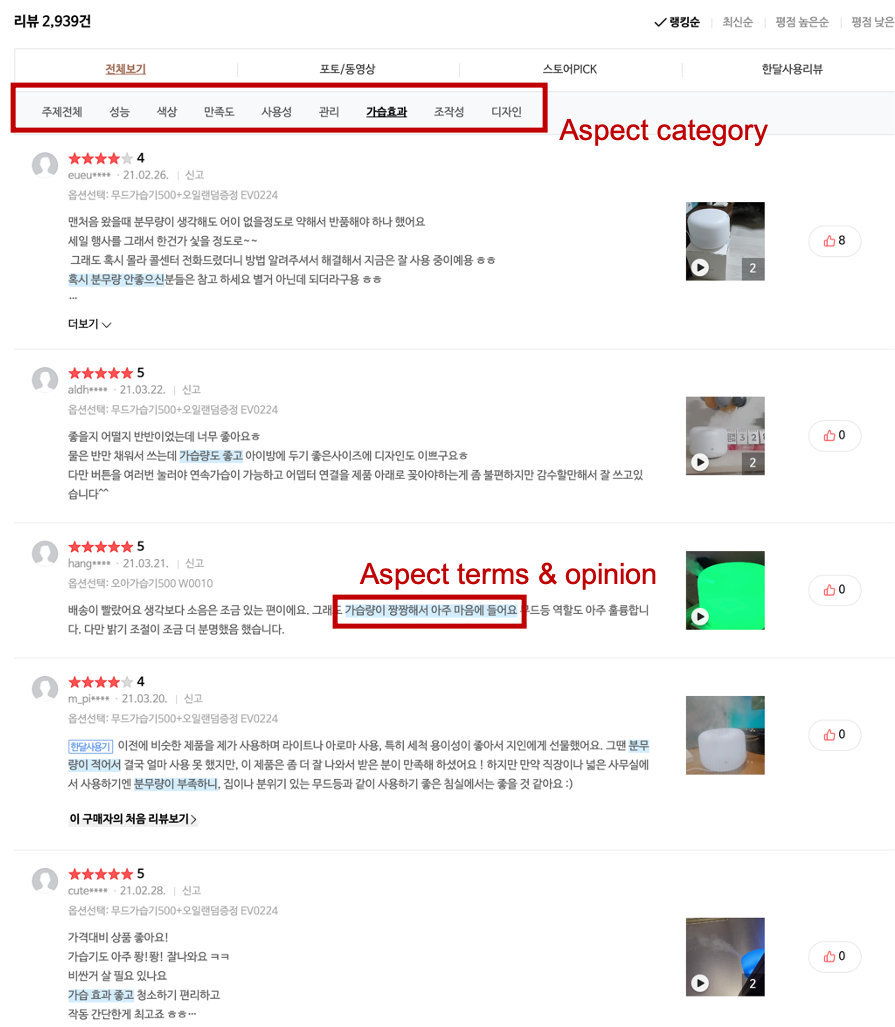
네이버는 Aspect Extraction 모델이 꽤 고도화된 것으로 보인다. 우선 식당 방문자 리뷰를 보면, 상단에 카테고리로 분류를 해두었다. 그리고 해당 카테고리를 눌렀을 때 관련된 리뷰들이 필터링 되는데 카테고리와 관련된 aspect와 opinion이 하이라이트 되어 보여진다.
아마존 리뷰의 경우 '청결도'를 선택한다면 청결도, 청결 등의 단어가 직접 들어있는 리뷰들을 보여줬다면, 네이버의 경우엔 위생상태가 좋지 않다는 내용을 하이라이트 하고 있었다. 현재 대량의 쇼핑 리뷰 데이터를 가지고 이런 비슷한 연구를 진행해보려고 애를 쓰고 있는데.. 어떤 기준으로, 어떻게 학습시킨 모델로 이런 걸 찾아서 보여주고 있는지 너무 궁금하다.
추가로 쇼핑 리뷰들을 볼 때에도 남자친구, 아버님, 어머니, 아빠, 할머니 등의 사람이 등장해서 누구에게 유용할지에 대한 정보를 주고 있는 리뷰들이 많았는데 '목적' 이라는 카테고리로 분류해놓고 있는 점이 좋았다.
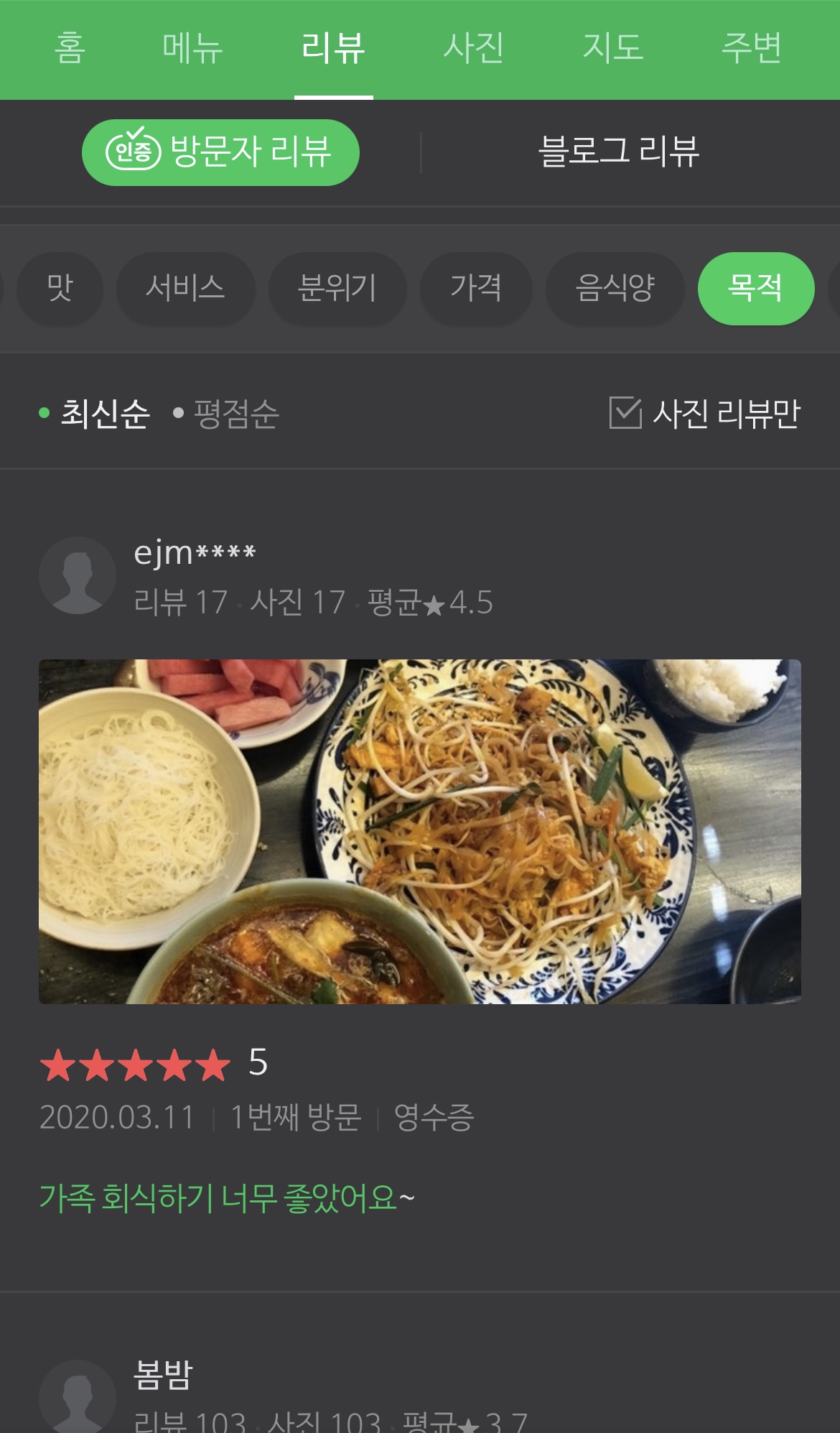
플레이스 뿐 아니라 쇼핑 리뷰도 아래처럼 주요 카테고리를 정의해두고(pre-define) 거기에 적합한 단어들을 하이라이트해주고 있다. 단순히 '가습' 이라는 단어가 등장하지 않더라도 '분무량이 부족하니' 부분을 찾아내고 있는 걸 보면 네이버의 큰 리뷰 데이터를 기반으로 rule-based와 단어 embedding 방식 등이 잘 자리잡혀 있는 것으로 보인다.
Coupang: 가장 원하는 리뷰를 직접 찾아볼 수 있도록
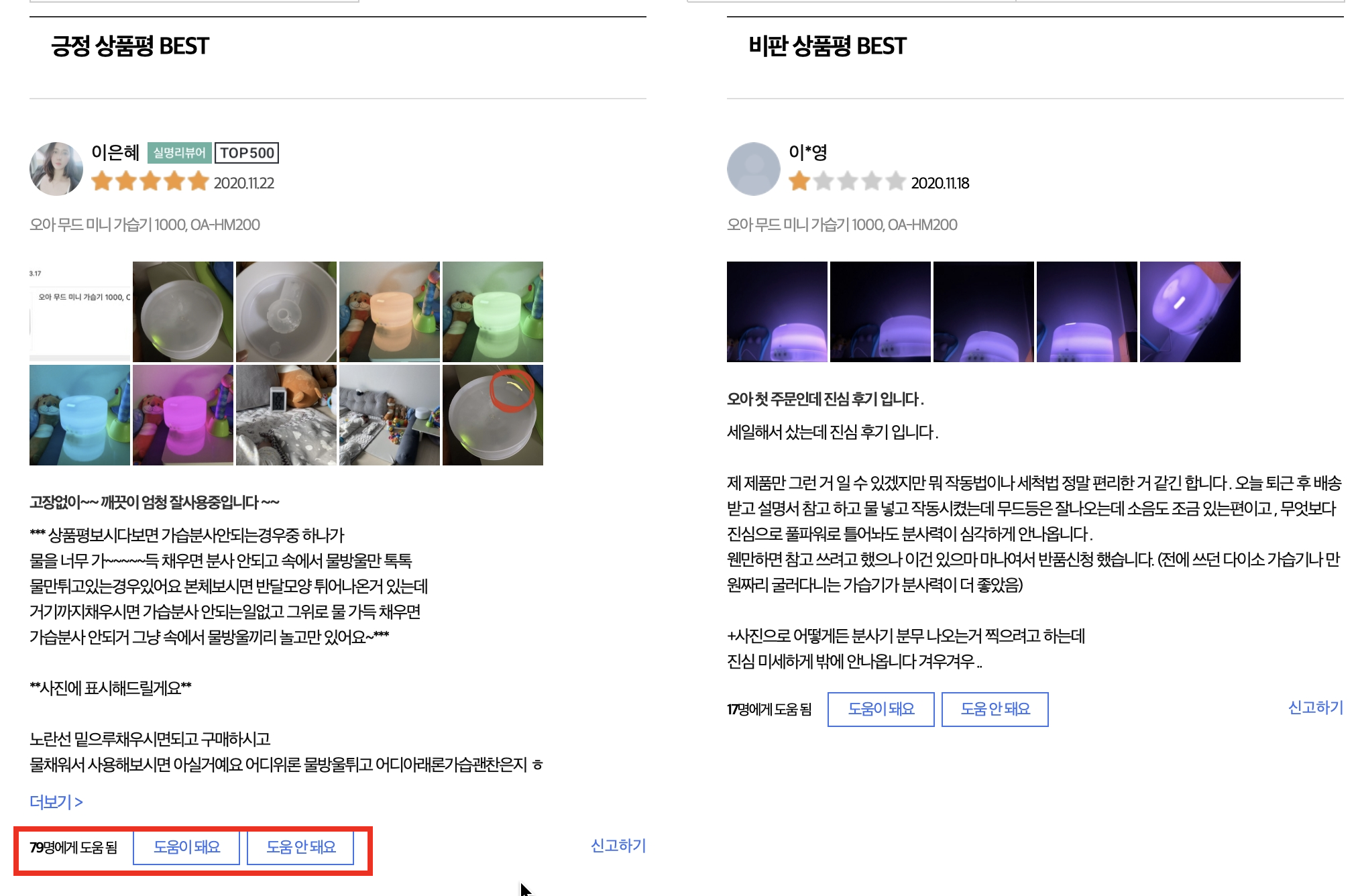
쿠팡은 크게 두 가지의 특징이 있었다. 하나는 사용자들에게 도움이 된다는 평을 많이 받는 리뷰를 베스트 리뷰로 선정하고 긍정과 부정적인 내용을 담은 베스트 리뷰를 하나씩 선정하여 우선 노출해준다. 사용자 참여도가 높았다.
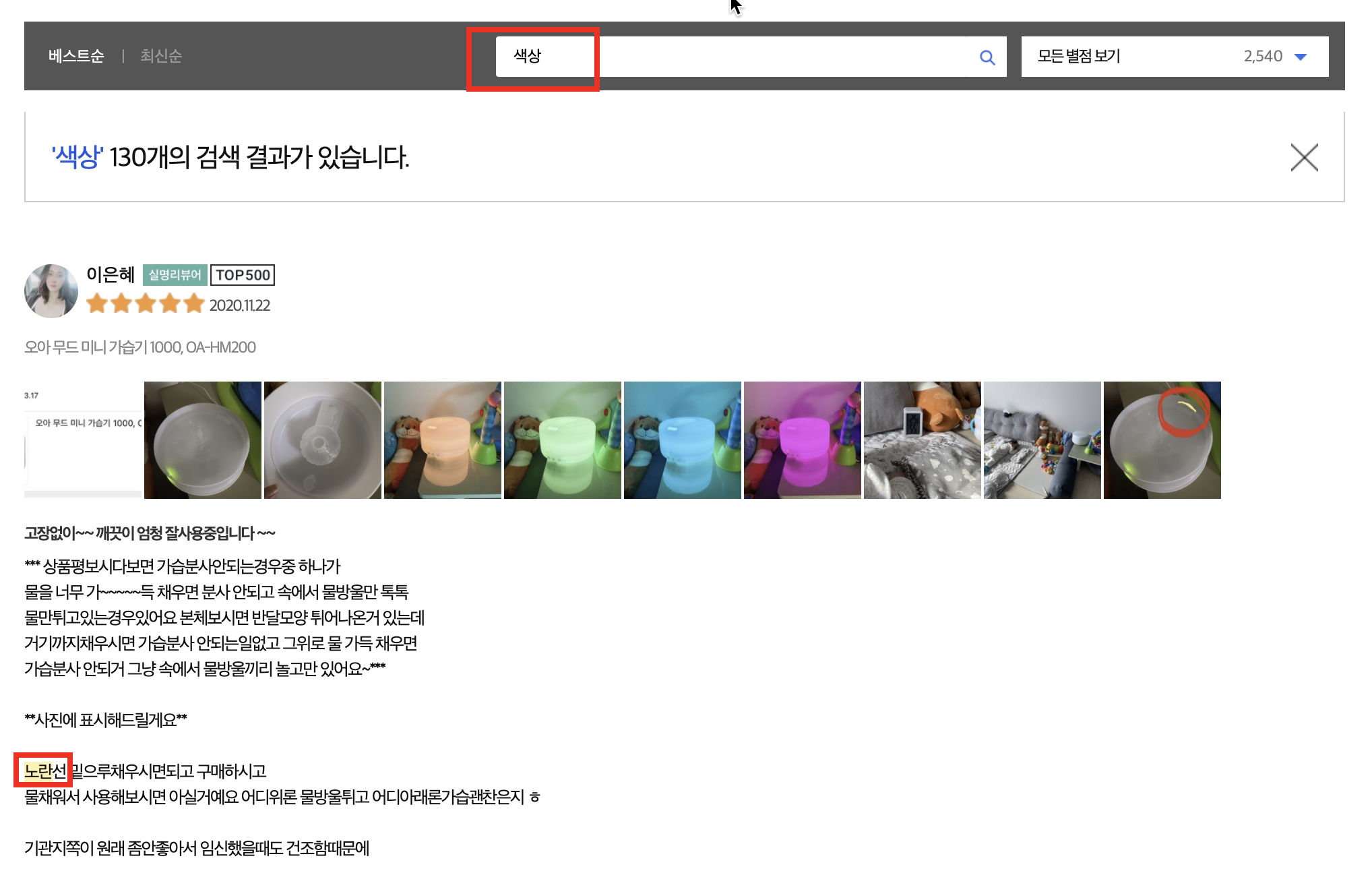
또 하나는 리뷰를 직접 검색할 수 있도록 해두었다. 아마존이나 네이버가 플랫폼 측에서 주요 내용을 추출해서 제안하는 반면, 쿠팡은 직접 단어를 검색해서 찾아볼 수 있도록 했다. '청소', '관리' 등을 검색했을 때는 그 단어가 등장해야만 잡히는 것으로 보였는데 '색상'에는 '노란', '흰색' 등의 색 이름까지 잡힌다. 다만 언어를 이해한다는 느낌보다는 단순 단어 embedding이 비슷한 것들을 뽑아주거나 아니면 rule-based로 처리하고 있다는 느낌이 든다. 무드가습기에서 '색상'을 찾아볼 때는 무드등의 색이 궁금했을 텐데 "노란선 밑으로 물을 채워라"라는 내용이 잡히는 건 단순 '노란'이라는 단어 벡터와의 유사성 만으로 찾았기 때문일 것이다.
이러한 쿠팡의 사용자 자유도가 높은 방식은 원하는 정보를 찾아낼 수 있도록 돕는 간단하고 강한 방식이다. 다만 플랫폼에서 수많은 리뷰에 숨은 implicit 특성을 뽑아내 recommendation에도 반영할 수 있는 단계는 멀어보였다.
SKT 11번가: 유사한 단어들은 찾아주는 것 같은데..
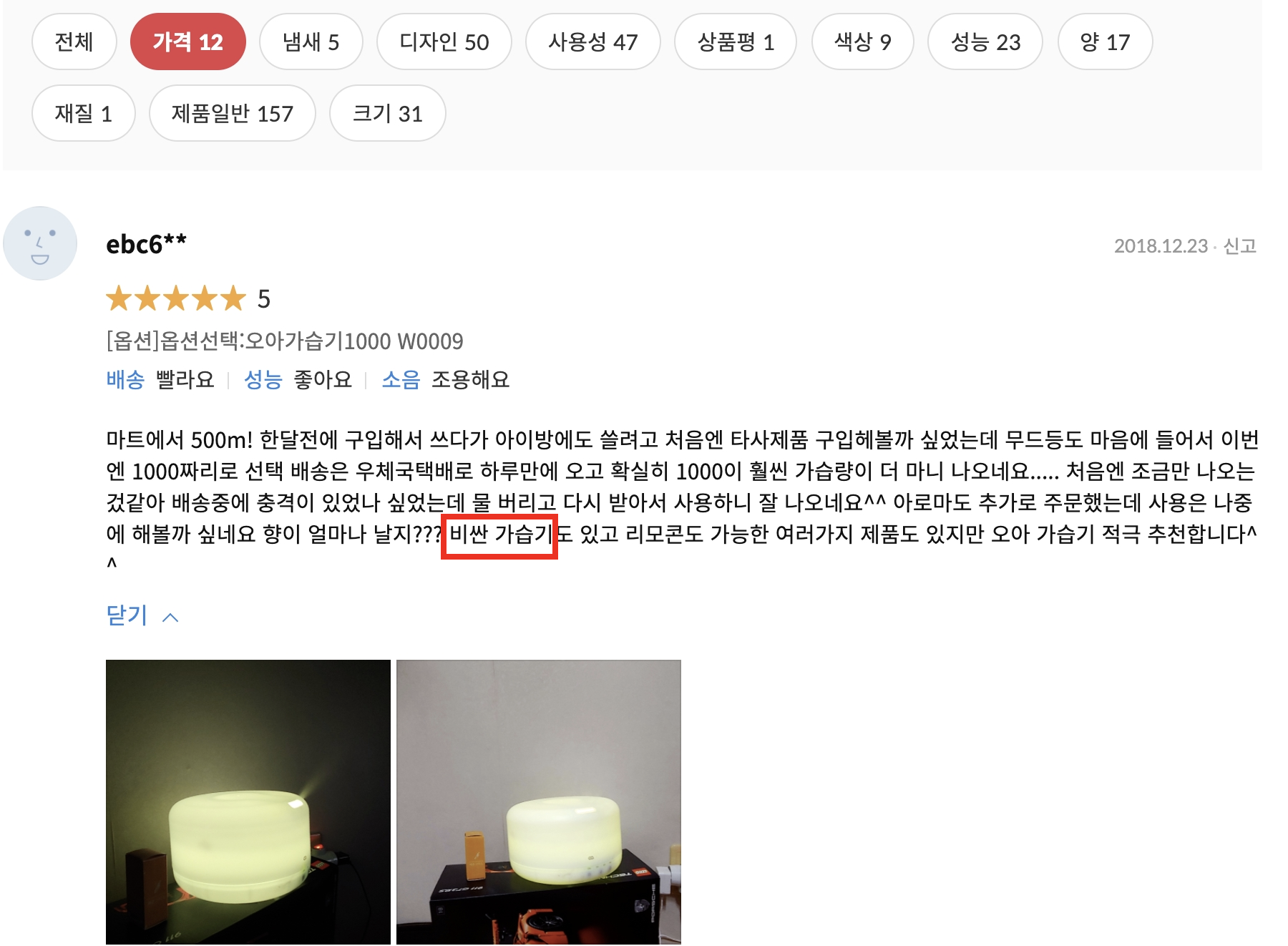
11번가 또한 카테고리를 추출해두고 사용자가 필터링을 해볼 수 있게 했다. 그리고 카테고리명이 직접 등장하지 않더라도 유사한 단어가 등장하는 리뷰들을 보여주고 있다. ("가격" -> "비싼")
다만 카테고리를 어떻게 선정했을지 궁금하다. ("사용성", "성능", "제품일반") / ("디자인", "색상") 등 겹치는 내용들도 다른 카테고리들로 구분해두었다.
정리
쿠팡을 제외한 아마존, 네이버, 11번가의 리뷰들은 플랫폼에서 추출한 키워드 기반으로 리뷰를 볼 수 있었다. 이 분야에서는 연관된 단어와 단어구가 등장하는 부분을 하이라이트 해주는 성능을 보면, 네이버의 언어 모델의 성능이 좋게 느껴졌다.
카테고리는 어떻게 구분하고 있는지, 어떤 학습 방식으로 연관된 부분을 찾아내는지 궁금했다.
카테고리 단어를 결정하는 데에는 이런 방법들이 있을 것이다.
- 상품군에 따른 사전 정의
- Rule-base로 단어 빈도 기반 추출과 embedding 벡터 클러스터링 등
- Summarization 처럼 전체 리뷰에서 주요 내용 extraction
또한 네이버나 11번가에서는 카테고리가 정해지면 그 단어가 직접 등장하지 않더라도 관련된 단어를 찾아내게 되는데 문장 내 parsing tree나 pos tag를 활용하는 것인지, 아니면 딥러닝 모델에서 카테고리와 관련 깊은 토큰들을 찾아내는 것인지 궁금하다.

와 이런건 정말 신기하네요 잘읽었습니다!