Self-Supervised Learning of Lidar Segmentation for Autonomous Indoor Navigation
global mapper
목록 보기
3/37
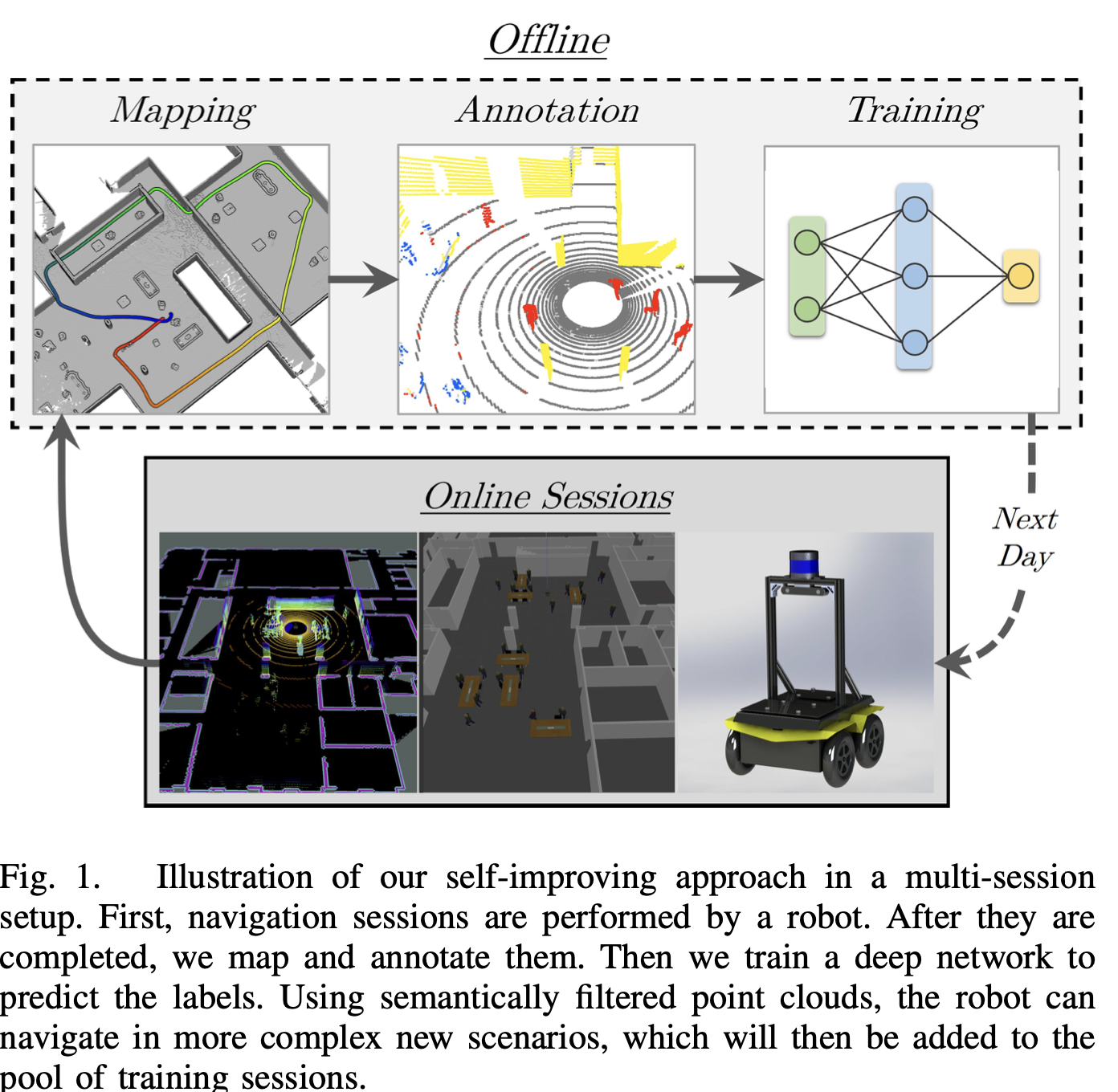
0. 그림 설명
- 장기적인 다중 세션 설정에서
라이다 포인트 클라우드의 segmentation을 위한 self-supervised 학습 접근법을 제안해 (아래 그림)- KPConv로 만들어진 포인트 컨볼루션 네트워크를 훈련시켜, 단일 라이다 프레임을 입력으로 받아 레이블을 예측하도록 훈련시켜.
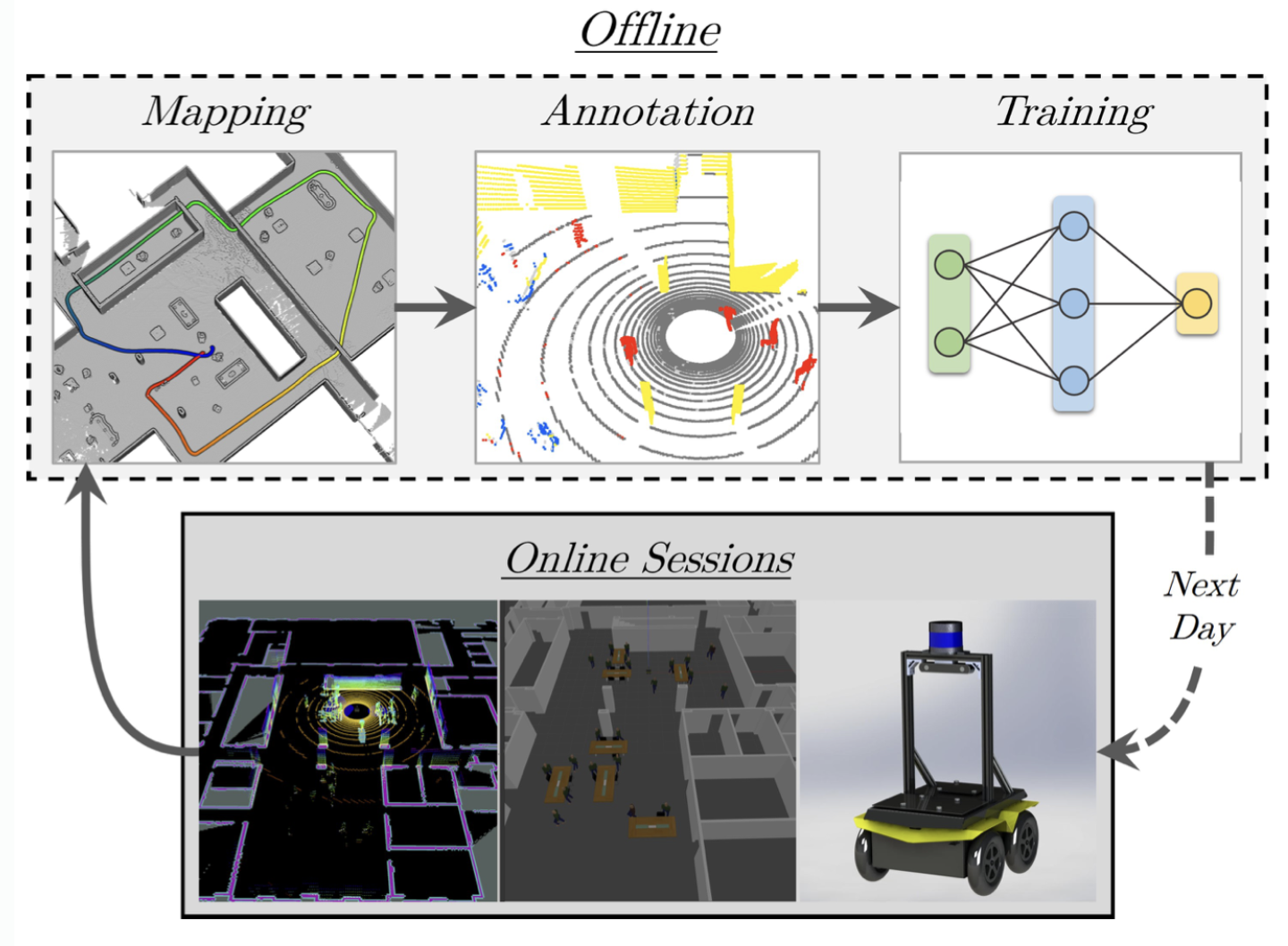
- 다중 세션 설정에서 우리의 self improving 접근 방식을 설명
- 첫 번째로, 로봇이 주행하며, 라이더 데이터를 모음
- 그 후, 라이더 데이터와 global map을 매핑하고, 주석을 답니다.
- 그 다음에는 딥 네트워크를 훈련시켜 lidar pointcloud의 라벨을 예측하게 함
- semantically filtered 포인트 클라우드를 사용함으로써, 로봇은 더 복잡한 새로운 시나리오에서 탐색할 수 있게 되며, 이는 training 세션의 풀에 추가될 것
- 아래 그림은 학습 데이터 생성을 위한,
annotation과정 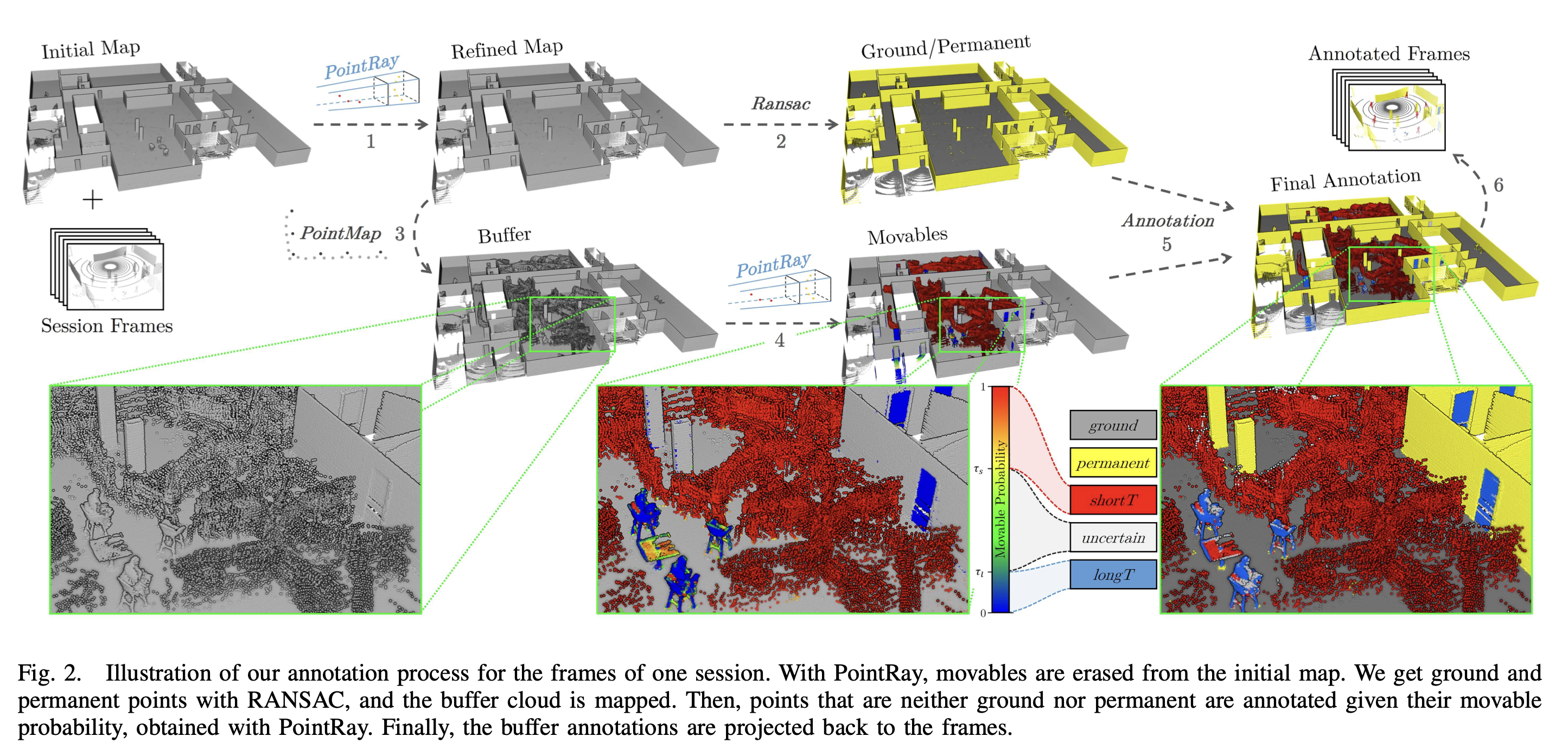
PointRay를 이용하여, initial map에서 movables를 지웁니다.
- point ray는, 라이다에서 취득한 데이터와, 저장되어 있던 맵 데이터를, frustum grid에 두고 같이 비교함으로써, movable 확률을 rule-based로 업데이트 하는 로직을 의미함.
- 그 다음, RANSAC를 이용하여, ground and permanent points(벽과 바닥)을 얻고,
- buffer cloud(수집된 라이더 포인트들이) 가 mapping됩니다.
- ground 나 permanant 둘 다 아닌 points는, (PointRay로부터 얻은) "movable probability"에 따라 annotation 됩니다.
- 5.~6. 최종적으로, buffer annotations이 다시 frames로 project됩니다.
1. abstract
라이다 프레임의 semantic segmentation을 위한 self-supervised learning 접근 방법을 제시- 우리의 방법은 사람의 annotation 없이 deep point cloud segmentation architecture를 훈련시키는 데 사용
- annotation 처리 과정: SLAM 및 레이-트레이싱 알고리즘의 조합으로 자동화
- 같은 환경에서 여러 navigation 세션을 수행함으로써,
- 벽과 같은 영구 구조물을 식별하고,
- 사람과 테이블과 같은 단기 및 장기 이동 가능 객체를 구별할 수 있음
- 그런 다음 (위 방식으로 생성된) semantic label을 예측하도록 훈련된 네트워크를 사용하여 새로운 세션을 수행할 수 있음
- 우리는 접근 방식이 시간이 지남에 따라, 한 세션에서 다음 세션으로 스스로 개선할 수 있는 능력을 보여줍니다.
- 우리는 네트워크 예측에 대한 통찰력을 제공하고, 우리의 접근 방식이 일반적인 위치 추정 기술의 성능을 개선할 수도 있다는 것을 보여줌
2. Introduction
- 붐비는 건물에서는 내 위치 확인이나 path planning 같은 기본적인 네비게이션 작업이 어려울 수 있어.
이런 복잡한 환경에서도 위 2가지의 성능을 더 견고하게 만들려면, 각각의 알고리즘이 semantic information를 사용할 수 있어.- 예를 들어, 위치 확인 알고리즘은 벽처럼 영구적인 객체에 집중해야 하고,
- 경로 계획 알고리즘은 움직이는 객체를 마치 정적인 것처럼 취급해서는 안 돼.
- 실시간으로 semantic 정보를 예측하기 위한 supervised 학습 접근법은 좋은 후보지만,
- 이런 supervised 방법은 사람들이 손수 annotation을 해야해서 귀찮아.
- 이 논문에서는 장기적인 다중 세션 설정에서, 라이다 포인트 클라우드의 segmentation을 위한 self-supervised 학습 접근법을 제안해 (그림 1)
- 네트워크 예측은 우리의 로봇이 점점 더 복잡한 시나리오에서 진화할 수 있게 해주고, 더 복잡한 시나리오를 볼수록 그 예측이 더 나아지게 돼.
- 우리의 annotation 방법론은 두 가지 주요 구성 요소를 사용해:
PointMap: ICP 기반의 3D SLAM 방법으로 서버에 pointcloud 맵을 구축하거나 localize할 수 있고,PointRay알고리즘: 레이-트레이싱(frustum 형태)을 사용하여, 서버의 pointcloud 맵에서 occupancy 확률을 추정해.
- 우리는 네 가지 semantic 레이블을 식별할 수 있어:
바닥영구적인 것(벽처럼 절대 움직이지 않는 객체들의 포인트)단기(사람처럼 단기적으로 움직이는 것)장기(세션 사이에 재배치될 수 있지만 여전히 있는 가구 같은 장기적으로 움직이는 것)
- 라벨이 불확실한 일부 포인트는 학습 데이터로 쓰이지 않아.
- 로봇이 환경을 탐색하는 동안, 딥러닝 네트워크의 prediction은 포인트 클라우드에 대한 선별 시스템으로 사용되어.
우리는 localization algorithm에 영구적인 것과 바닥 포인트만을 사용.- 로컬 및 글로벌 planning에 대해서는, 단기적으로 움직이는 포인트(예: 사람)를 제거한 후 planning, 이들이 알아서 길을 비켜갈 것이라고 가정
- 시뮬레이션은 포인트 라벨링과 위치 확인 모두에 대한 ground truth을 제공하는 장점이 있어, 우리 접근법의 철저한 검증을 가능하게 해.
3. related work
3.1. 이 논문의 SLAM 접근법
- ICP 기반의 PointMap SLAM 을 썼는데, 단순함과 효율성에 중점을 두고 설계했어.
3.1.1. 포인트 클라우드와 normal을 맵으로 사용
- 이 pointcloud는 각 점의 방향성을 나타내는 normal 벡터 정보도 함께 저장
- 라이다로부터 새로운 데이터 프레임을 받을 때마다,
우리는 이 노멀을 서버 맵에 직접 업데이트하는데, 이때 '구면 좌표 neighbor' 방식을 사용- 구면 좌표 시스템 개념:
- 3차원 공간에서 점의 위치를 표현하기 위해 사용되며, 일반적으로 반지름(r), 경도(θ), 위도(φ) 세 가지 값으로 구성
여기서 '구면 좌표 neighbor'이란, 어떤 점 주변의 다른 점들을 이 구면 좌표를 기반으로 식별하는 방식
- 구면 좌표 neighbor 시스템 용도:
lidar 센서로부터 얻은 3D 포인트 클라우드 데이터에서 주변 점들을 찾아내기 위해사용- 특히,
점들의 normal 벡터(표면의 방향을 나타내는 벡터)를 계산하거나 업데이트할 때 유용 normal 벡터는 표면의 형태를 이해하고, 객체 간의 경계를 식별하는 데 필수적
- 구면 좌표 시스템 개념:
- 즉,
각 점의 위치를 더 잘 이해하기 위해, 주변 점들과의 관계를 구면 좌표계를 통해 계산하고 업데이트
3.1.2. pose graph 를 유지하지 않고, lidar frame-맵 정렬에만 의존
- 일반적으로는 로봇의 정확한 위치를 추적하기 위해 'pose graph'(각 시점에서의 로봇의 위치와 방향을 나타내는 그래프)를 사용할 수 있어요.
- pose graph
- 개념:
포즈 그래프는 로봇이 이동하면서 취한 포즈(위치와 방향)들을 노드로 하고,이 포즈들 사이의 상대적인 움직임을 edge로 나타내는 그래프
- 용도:
- 포즈 그래프를 통해 로봇이 어떤 경로를 따라 움직였는지, 어떤 지역을 탐험했는지 파악할 수 있음
- 또한, 위치 추정의 정확도를 높이기 위해 사용되기도 함
- 개념:
- 하지만 우리 방식에서는 이런 복잡한 시스템을 사용하지 않아요.
- 대신, 우리는 단지
새로운 라이다 데이터 프레임이 우리가 이미 가지고 있는 3차원 map에 어떻게 맞는지를 보며 내 위치를 추정
3.1.3. loop closure을 고려하지 않았음
- 'loop closure'는 로봇이 같은 위치를 다시 방문할 때, 이전 위치 데이터와 새 위치 데이터를 맞추는 과정
- 개념:
- loop closure는 로봇이 일정 경로를 이동한 후, 시작 지점이나 이전에 방문했던 지점으로 돌아오는 것을 인식하는 과정
- 이는 위치 추정에서 발생할 수 있는 오류를 수정하는 데 중요한 역할을 함
- 용도:
- loop closure를 통해, 로봇이 지도상에서 자신의 위치를 더 정확하게 재조정할 수 있음
- 예를 들어, 오랜 시간 동안 이동하면서 발생한 미세한 위치 추정 오류들이 누적될 수 있는데, loop closure를 통해 이러한 오류를 줄이고 전체 지도의 일관성을 유지할 수 있음
- 개념:
- 하지만, 논문의 방법이 이미 충분히 정확하기 때문에, 복잡한 루프 폐쇄 과정을 진행할 필요가 없는 거죠.
3.2. ray-casting
- 레이-캐스팅을 사용한 occupancy probabilities 계산
- 우리의 경우, PointRay는 grid 대신 point cloud에서 occupancy 확률을 계산해
- 그래서 측정된 포인트가 있는 곳에서만 free space을 모델링해
- 우리의 주요 추가 사항:
- 다중 세션을 결합하여
단기적이고 장기적으로 움직이는 물체들을 구분하는 개념 도입 - 라이다 광선 주위에 원뿔 대신 프러스텀을 사용했음
- 확률 업데이트 규칙을 단순화했음
- 다중 세션을 결합하여
4. Approach
- 먼저, 두 가지 주요 모듈인 PointMap과 PointRay를 소개
- 다음, 각 연속 세션의 lidar 프레임이 어떻게 annotation 처리되는지 설명
- 마지막으로, prediction에 사용된 네트워크 구조와 training 방법에 대해 자세히 설명
4.1. PointMap: ICP 기반 3D SLAM
- 우리는 annotation 과정에 사용될 수 있는 pointcloud 맵을 제공하는
ICP 기반 SLAM 알고리즘을 설계 - PointMap은 두 가지 구성 요소
- 맵에 lidar 프레임을 정렬하는 ICP 솔루션
- 정렬된 lidar 프레임으로 맵을 업데이트하는 매핑 함수
4.1.1. [PointMap] 맵에 프레임을 정렬하는 ICP 솔루션
- ICP 알고리즘에 대한 자세한 설명은 https://hal.science/hal-01143458/document 의 심층 리뷰를 참고했음
- 그들의 연구를 따라, 우리 ICP도 아래 요소들로 이루어져 있음 (각각 뭘 선택했는지는 표 I를 보자!)
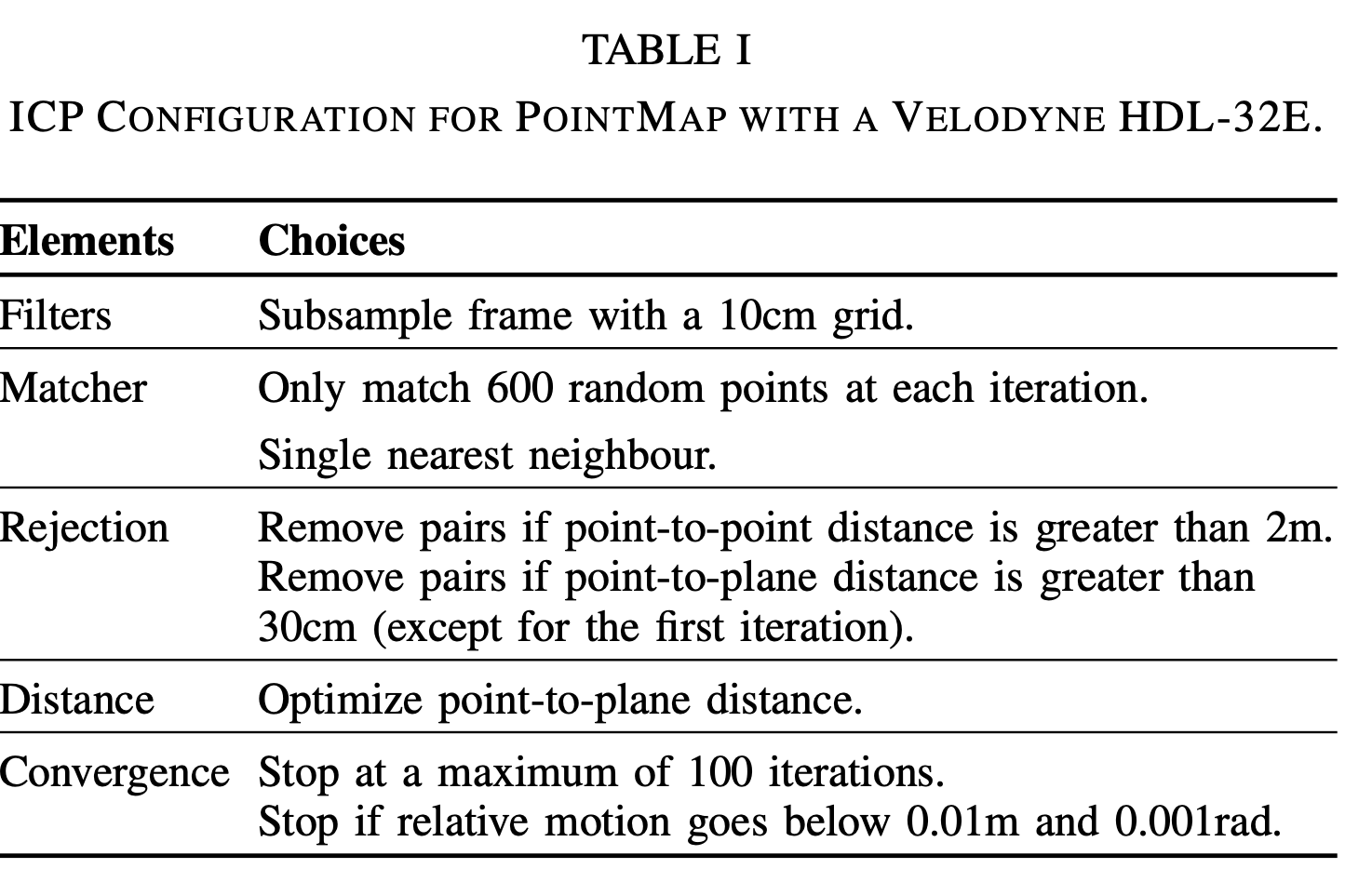
표 1에서는 Velodyne HDL-32E를 사용한 PointMap에 대한 ICP 구성을 설명합니다.
4.1.1.2. 필터: 10cm 그리드로 프레임 서브샘플링
- 입력 데이터인 lidar 포인트 클라우드 frame 의 밀도를 줄임(10cm 간격의 그리드에 맞춰 서브샘플링)
- 목적
- 데이터 양을 감소시키고 계산 비용을 줄임
- 노이즈를 줄이는 효과도 있음
4.1.1.3. matcher: 각 iteration 마다 600개의 랜덤 포인트만 매칭. single nearest neighbor
- 매칭 단계에서는
pointcloud frame에서 선택된 포인트와,서버의 map pointcloud에서의 해당 포인트를 서로 매칭시키는 과정 - 여기서는 각 반복(iteration)마다
600개의 랜덤 포인트만을 선택하고, 각 포인트에 대해 가장 가까운 이웃을 찾아 매칭
4.1.1.4. Rejection
- 잠재적으로 잘못된 매치를 걸러내는 중요한 과정
- 이 단계는 매칭된 포인트 쌍 사이의 거리를 기반으로 결정
- Point-to-point distance
- 매칭된 포인트 쌍이 서로 2m 이상 떨어져 있으면, 제거
- Point-to-plane distance
- 이 기준은 포인트가 맵 상의 해당 평면으로부터 30cm 이상 떨어져 있을 경우(수직거리) 해당 포인트 쌍을 제거
이는 plane에 가깝게 분포하는 포인트들이 더 신뢰할 수 있는 매치를 제공한다는 가정하에 설정- 첫 번째 반복을 제외하고 이 조건을 적용하는 이유: 초기 정렬이 아직 충분히 정밀하지 않을 수 있기 때문
- 이 과정은 데이터의 지역적인 특성을 반영하기 때문에,
특히 건축 환경과 같이 평면적인 특성이 두드러진 곳에서 효과적으로 사용
4.1.1.5. 거리(Distance):
- Point-to-plane distance optimization
- 이 과정에서는 매칭된 포인트 쌍 사이의 평면 거리를 최소화하는 것을 목표
- 평면 거리를 최소화함으로써, 매칭된 포인트 쌍이 실제로 서로에 대해 잘 정렬되어 있음을 보장
- 이것은 특히 평면적 특성이 강한 실내 환경에서 효과적이며, 벽이나 만들어진 객체와 같이 뚜렷한 평면을 제공하는 환경에서 특히 유용
- 위 선택의 이유는, Velodyne HDL-32E 센서를 사용한 이전 연구들을 따라했습니다.
- 일부 요소들(예: matching)은 효율성을 위해 간소화
4.1.2. [PointMap] 정렬된 프레임으로 맵을 업데이트하는 매핑 함수
- TODO: 아래 문장들 이해하기
- 높은 score을 가진 normal을 선택하여 업데이트 한다.
- frame normal은, 구면 좌표계의 radius neighbors를 이용하여 계산한다.
- PointMap의 두 번째 구성 요소인 맵 업데이트 함수는 정렬된 프레임의 정보를 맵에 추가
- 점들의 밀도를 조절하기 위해,
서버에 저장된 맵 point cloud는 sparse 3D grid(hashmap으로 구현된)와 짝을 이룸 - hashmap?
각 포인트(또는 voxel)는 키로 사용되며,관련 메타데이터(예: 법선 벡터, 점수, 포인트의 실제 좌표)는 값으로 저장- 이 구조는 맵의 포인트에 대한 빠른 검색, 업데이트 및 삭제를 가능하게 함
- point cloud의 많은 양의 데이터를 효율적으로 관리하고, SLAM과 같은 알고리즘에서 빠른 데이터 액세스를 필요로 하는 경우에 이상적
- 그리드는 원점
x_origin = (0,0,0) ∈ R3과 셀 크기dlmap = 3cm에 의해 정의 - 각 voxel =
하나의 점+점의 법선+ scores ∈ [0, 2] ⊂ R - 업데이트 규칙은 매우 간단
- 맵에 추가되는 프레임이 점점 많아질 때 생기는 드리프트를 줄이기 위해,
각 voxel에서 처음 기록된 점을 계속 유지
- 맵에 추가되는 프레임이 점점 많아질 때 생기는 드리프트를 줄이기 위해,
- 점 x ∈ R3에 대한 해당 voxel은 다음과 같음
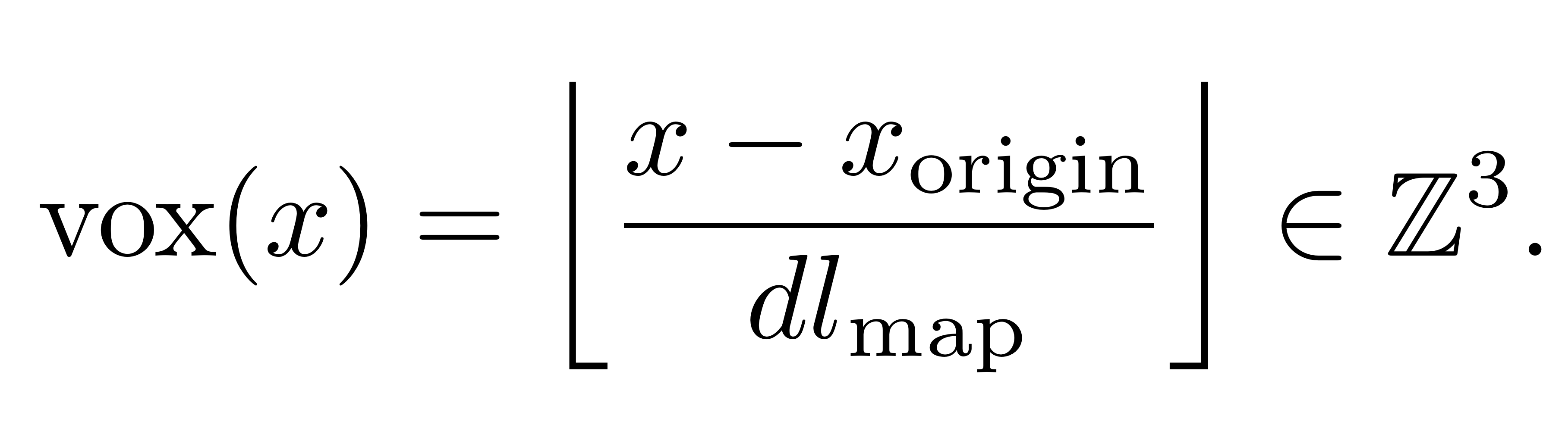
- 하지만, 법선은 지속적으로 업데이트됩니다:
- 프레임 법선들을 계산 하는법:
구면 좌표에서 반경 neighbors을 사용- 각 이웃이
스캔의 3개 연속 라인의 점들을 포함하도록1.5 × θres(센서 각도 해상도)의 반경을 사용 우리는 가장 높은 점수를 가진 법선을 선택(법선마다 점수가 있음)
- 법선 계산:
- 포인트 클라우드에서 각 포인트의 법선: 주변의 다른 포인트들과의 상대적인 위치를 기반으로 계산
- 법선의 방향 설정:
- 계산된 법선은 '입사각(incidence angle)' theta가 예각이 되도록 설정
- 즉,
법선이 라이다 센서를 향하도록 방향을 조정
- 점수 부여:
- 법선에는 점수가 부여되며, 높은 점수의 법선 -> lidar가 가까운 거리에서 정면으로 해당 점을 획득했다는 뜻!
- 법선의 점수는
라이다가 대상 표면을 '정면으로 바라보고(facing)' 있을 때라이다로부터 대상 표면까지의 거리가 가까울 때 더 높아짐
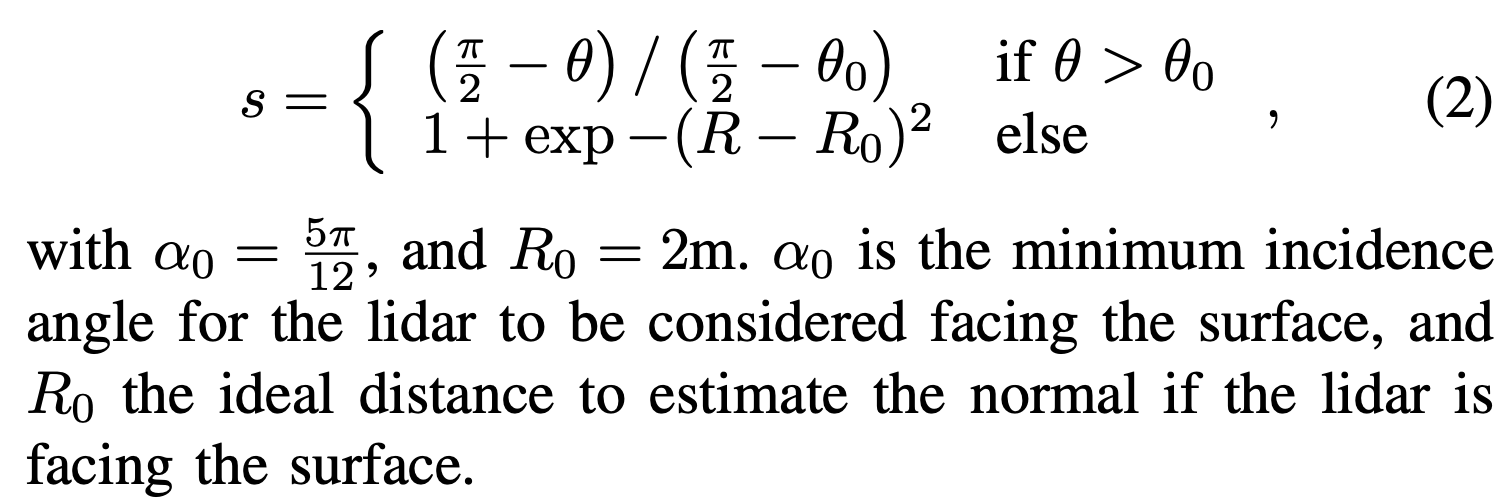
- 수식은 이러한 점수를 계산하기 위한 식입니다. 이 식은 두 가지 상황을 고려합니다:
- θ가 θ₀보다 클 때:
- 여기서
θ는 법선과 라이다 광선 사이의 각도 θ₀는 라이다가 대상 표면을 바라보고 있다고 간주되는 최소 각도(74도나 됨)
- 여기서
- θ가 θ₀보다 작거나 같을 때: 라이다와 표면 사이의 거리 R이 이상적인 거리 R₀에서 얼마나 벗어났는지에 따라 점수가 계산됩니다. 이는 지수 함수를 사용한 복잡한 식으로, 라이다가 대상을 바라볼 때 이상적인 거리에서 법선이 계산되도록 유도합니다.
- θ가 θ₀보다 클 때:
- α₀와 R₀는 각각 라이다가 표면을 바라보고 있다고 간주되는 최소 각도와 법선을 추정하기 위한 이상적인 거리를 나타냄
- 마지막 그래프 이상함 (수식이 이상함)
- 간단히 말해, 이 모든 과정은 라이다 데이터에서 각 포인트의 '품질'을 평가하여, 법선을 계산하고, 그 법선을 사용하여 라이다 데이터의 각 포인트가 어느 정도 '유용한' 정보인지를 결정하기 위한 것
- 결국
휴리스틱 score(0~2점 사이)는 두 가지 아이디어를 전달- 법선은 이상적으로 라이다가 표면을 마주보고 있는 경우 가까운 거리(R)에서 계산되어야 하지만, 오직 라이다가 표면을 마주보고 있을 때만 가능합니다:
4.2. PointRay: 레이-트레이싱을 통한 movable 확률 계산
- movable 확률은 occupancy 확률의 반대 개념
지도상에 존재하는 특정 위치가, online 세션 내내 점유되지 않았다면, 지도상의 특정 위치는 이동 가능한 객체에 속한다는 의미- lidar frame 으로부터 제공되는 데이터를 통해, 지도에서 이동 가능 확률을 파악할 수 있음
- 실제로, 각 lidar 프레임은 점유된 공간(점들이 위치한 곳)과 라이다 광선을 따라 있는 자유 공간의 두 가지 정보를 제공
- 우리는 [21]에서의 아이디어를 따라,
서버 global 지도를 프레임의 구면 좌표에 투영하여, 라이다 광선을 모델링하는 방법을 사용movable 확률은 프레임 점들과 지도 점들 간의 거리 차이에서 유추
- 지도의 각 점, xi에 대해, ni번의 p_i^k(if 0=occupied, 1=free space) 를 할당
- 여기서 ni는 이 점이 라이다 프레임 시퀀스 처리를 통해 관측된 횟수
- 하나의 프레임에 대해, 식 1을 사용하여 occupied voxel 목록을 얻음
- 이 voxel i에 대해 ni가 이미 증가된 경우, 우리는 새로운 값 p_i^ni = 0을 추가하고 ni를 1만큼 증가시킴
- 또한, lidar 프레임의 희소성을 보완하기 위해, 같은 방식으로 map 그리드의 직접적인 이웃도 업데이트
- 그런 다음, lidar 프레임을 프러스텀 그리드에 투영하여 자유 공간을 인코딩
- 프러스텀 그리드는 θ와 φ 구면 차원의 2D 그리드로, 픽셀은 라이다 원점까지의 최소 점 거리를 저장
- 이것은 라이다의 깊이 이미지로 볼 수 있으며, 해상도는 dθ = 1.33°와 dφ = 0.1°(HDL-32E 각도 해상도)의 파라미터로 정의
- global 맵도 같은 프러스텀 그리드에 투영되며, 불필요한 계산을 피하고 프레임 포즈에 맞추기 위해 프레임 차원으로 자름
- 이 시점에서, 우리는
잘라진 맵의 각 점의 반지름 ρ을 해당lidar frame 프러스텀의 깊이 ρ0과 비교할 수 있습니다.
- 이 시점에서, 우리는
- global map 점이 free space으로 업데이트되기 위해서 만족해야하는 아래 2가지 조건
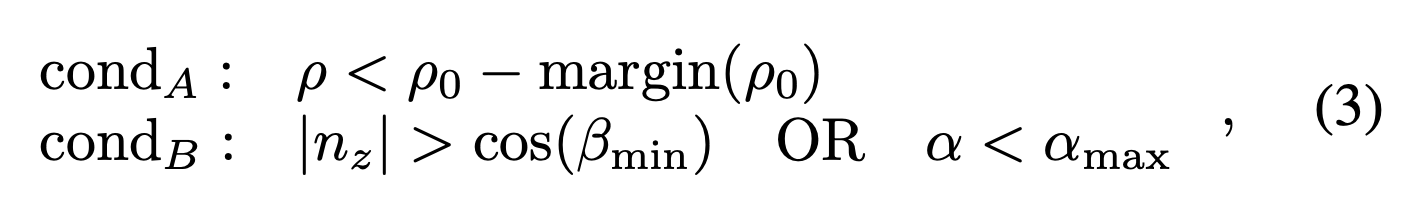
- cond_A
- 새로 검지된 깊이(ρ0)가, 기존 map의 깊이(ρ)보다 깊어야 합니다.
- 여기서 margin(ρ0) = ρ0 max(dθ, dφ)/2는 이 특정 범위에서 프러스텀의 가장 큰 반지름의 절반 크기
- cond_B
- 조건1: nz(normal vector 중, 지면과 수직한 요소)가 특정 기준 이상인 경우 (예: 테이블 표면)
- 조건2: α(라이다 광선과 이 법선의 입사각)이 특정 기준 이하인 경우
- αmax = 5π 및 βmin = π/12는 경험적 임계
우리는 극단적인 입사 값에 대해 업데이트하고 싶지 않지만, 테이블 같은 경우는 (표면이 거의 라이다 광선과 평행하므로) 법선이 수직일 때만 업데이트
- condB 때문에, 지면 점들은 높은 이동 가능 확률을 가질 가능성이 더 커지는 부작용이 있지만, 우리는 지면을 레이-트레이싱의 영향을 받지 않는 별도의 의미론적 클래스로 추출함으로써 이를 처리
- condA와 condB가 충족되고, 아직 업데이트되지 않았다면, 맵 점은 새로운 값
p_i^ni = 1(free space)을 할당, ni가 1만큼 증가 - 전체 세션이 레이-트레이싱되면, 맵의 모든 점 xi에 대한 movable 확률을 얻을 수 있습니다:
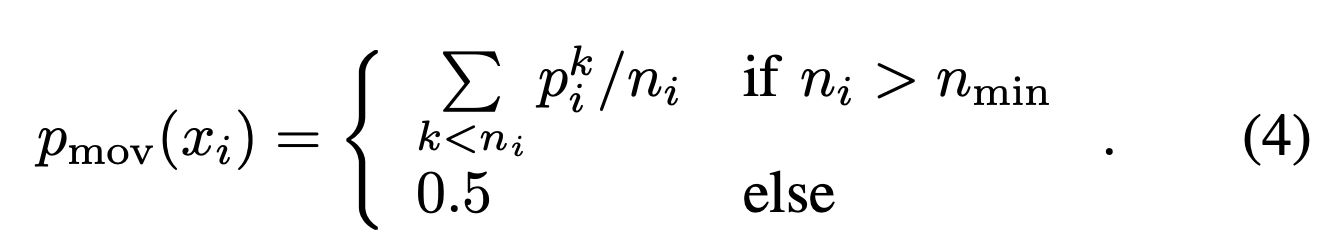
- nmin = 10번 이상 관측된 점은, movable 확률을 계산합니다.
- 적어도 nmin = 10번 관측되지 않은 점은 이동 가능한 것으로 간주하지 않습니다. (확률을 0.5로 둔다.)
4.3. multi 세션 레이-트레이싱 annotation
- PointMap과 PointRay를 사용하면, 한 세션의 지도에서 movable 확률을 계산할 수 있음
- 이 섹션에서는 movable 확률을 여러 세션에 주석을 달기 위해 어떻게 확장하는지 설명
- 여러 세션을 다룰 때 고려해야 할 첫 번째 사항은 movable 객체의 개념
- 단일 세션에서 객체가 움직이면
- 한 프레임에서의 그 점들이 다른 프레임에 의해 자유 공간으로 볼 수 있습니다. 따라서, 이동 가능합니다.
- 그러나, 다른 세션에서 프레임이 보는 것을 확인함으로써 '크로스 세션' 레이-트레이싱을 수행한다고 상상해보세요.
- 움직이지 않았던 객체, 예를 들어 의자가 다음 날 다른 위치에 있을 수 있으므로 이동 가능하게 보일 수 있습니다.
- 이것이 우리가 단기 이동 가능한 것과 장기 이동 가능한 것의 개념을 도입하는 이유
- 이 두 가지 의미적 클래스와 함께, 우리는
모든 세션에 걸쳐 이동하지 않는 것으로 남아 있는 영구적인 점들을 분류
- 이 두 가지 의미적 클래스와 함께, 우리는
- 우리는 또한 실내 시나리오에서 쉽게 추출할 수 있는
지면 라벨도 추가
- 또 다른 고려할 사항은
세션 정렬 - PointRay를 쓰기 위해서는, 프레임이 주석을 달고자 하는 지도와 완벽하게 정렬되어 있어야 함
- 여러 세션의 정렬을 보장하는 간단한 방법은 같은 초기 환경 지도에 대해 위치를 지정하는 것
- 다중 세션 시나리오에서, 프로젝트 시작 시 환경이 매핑되었다고 가정하는 것은 완전히 받아들일 수 있습니다.
- 다음에서는 전체 실험 공간을 커버하는 초기 매핑 투어가 수행되었다고 가정합니다.
- 아래 그림은 학습 데이터 생성을 위한,
annotation과정 PointRay를 이용하여, initial map에서 movables를 지웁니다.
- point ray는, 라이다에서 취득한 데이터와, 저장되어 있던 맵 데이터를, frustum grid에 두고 같이 비교함으로써, movable 확률을 rule-based로 업데이트 하는 로직을 의미함.
- 그 다음, RANSAC를 이용하여, ground and permanent points(벽과 바닥)을 얻고,
- buffer cloud(수집된 라이더 포인트들이) 가 mapping됩니다.
- ground 나 permanant 둘 다 아닌 points는, (PointRay로부터 얻은) "movable probability"에 따라 annotation 됩니다.
- 5.~6. 최종적으로, buffer annotations이 다시 frames로 project됩니다.
- 우리는 이
초기 지도를 알고리즘의 시작점으로 사용합니다. 초기 지도는 지면과 영구적인 점들의 수신자가 될 것 - 한 세션의 주석 과정은 그림 2에서 설명됩니다.
- 우리는 초기 지도에 PointRay를 적용하여(단계 1),
τ_refine = 0.9보다 높은 이동 가능 확률을 가진 점들을 제거 이 정제된 지도는 이 시점부터에서 초기 지도를 대체하며, 모든 미래 세션에서도 이 정제된 지도를 씁니다.- 지도가 모든 세션에 의해 정제될 것이기 때문에,
- 우리는 높은 τrefine 임계값을 사용할 여유가 있으며 일부 이동 가능한 것들을 놓칠 수 있습니다.
- 그들은 결국 다른 세션에 의해 포착될 것
- 지도에 남아 있어야 할 영구적인 점들을 제거하지 않는 것이 더 안전
- 정제된 지도의 점들은 지면 추출 알고리즘을 사용하여 permanant 또는 groud(단계 2)으로 분류
- RANSAC
- 다음 단계에서, 우리는 이 세션의 모든 프레임에서 점들을 집계하여 지도를 생성하기 위해 PointMap을 사용(단계 3).
- PointMap: 정렬된 프레임으로 맵을 업데이트하는 매핑 함수
- 이것은 임시 지도이며 프로세스의 끝에서 폐기될 것이므로 buffer라고 합니다.
- buffer의 역할은 annotation을 달고,
nearest-neighbor interpolation을 통해 그 annotaiton을 프레임으로 전송하는 것
- 확대된 부분에서 보여주듯이, 우리는 먼저 정제된 지도에서 오지 않은 버퍼 점들의 이동 가능 확률을 얻기 위해 PointRay를 사용(단계 4).
- 이 확률은
pmov > τshort인 경우 shortT,pmov < τlong인 경우 longT로 두 남은 클래스에 매핑(단계 5).- 나머지 점들은 불확실로 주석
- 마지막으로, 우리는 주석을 프레임에 다시 투영하여(단계 6) 우리의 딥 뉴럴 네트워크를 위한 훈련 세트를 얻습니다.
D. 네트워크 training 및 inference
- 우리의 작업은 어떠한 라이다 segmentation architecture에 대해서도 자가 지도 학습 전략을 제안하는 것을 목표
- 우리는 다양한 작업에서 뛰어난 성능을 보이고, PyTorch에서 포괄적인 소스 코드를 제공하는 최근의 3D 포인트 클라우드 컨볼루션 네트워크 KPConv를 선택[1]
- 대부분의 경우, 우리는 원래 KPConv 구조와 동일한 파라미터를 사용
- 나머지 부분에 대해서는 다음에서 중요한 파라미터에 대한 우리의 선택을 설명할 것입니다.
- KPConv는 원래 lidar-frame segmentation이 아닌 full scene segmentation을 위해 설계되었으며, training 시 sphere 샘플링 전략을 사용
- 네트워크는 임의로 선택된 장면의 sphere 부분 집합에서 훈련됨
- 훈련 시 전체 라이다 프레임을 사용하지 않는 것이 부적절해 보일 수 있지만, 우리는 이 sphere 입력 샘플링이 우리의 경우에 잘 작동한다는 것을 발견
- 이는 클래스 균형을 맞추는 종류의 효과를 만들어 내기 때문입니다.
- 실제로, 선택 전략은, 데이터셋의 모든 클래스 에 걸쳐, 동일한 수의 구가 선택되도록 보장합니다.
- 따라서, 소수 클래스가 더 자주 보이고 더 잘 분류됩니다.
- 따라서 우리는 입력에 대해 설정해야 할 두 가지 파라미터, 구의 반지름 R_in(4m)과 입력 서브샘플링 그리드 크기 dl_in(0.04)을 가집니다.
- 이 값을 선택하여, 라이다 프레임의 상당 부분을 커버하고 예측이 정확해지기에 충분한 세부 정보를 유지하도록 했습니다.
- 프레임의 작은 부분을 사용함으로써, 우리는 10개의 입력 포인트 클라우드 배치 크기를 가질 수 있습니다.
- 표준 입력 증강 전략을 따라, 우리는 입력 포인트 클라우드에 무작위 수평 뒤집기와 수직 축을 따른 무작위 회전을 추가
- 구조와 훈련 파라미터에 대한 자세한 내용은 원래의 KPConv 논문과 그 보충 자료를 참조하십시오.
- inference 중에, 우리는 전체 lidar 프레임을 네트워크에 공급
- 프레임은 먼저 sub-sampling되고, 네트워크는 각 서브샘플링된 점에 대해 우리의 네 가지 라벨을 예측
- 그런 다음, 우리는 이 분류된 서브샘플링된 프레임에 대해 삼단 분류 시스템을 사용합니다.
- 단기 이동 가능 점들은 움직이는 사람들로부터 비롯될 가능성이 높으며, 그들은 스스로 로봇을 피해야 합니다.
- 그들을 둘러싼 계획을 세우는 것은 의미가 없으므로, 우리는 그들을 글로벌 및 로컬 planning 시스템에서 제거
위치 추정을 위해, 우리는 또한 지도에 포함되지 않은 장기 이동 가능 물체도 제거
- 네트워크가 라이다 프레임의 부분 집합에서 훈련되었다는 사실이 문제가 되지 않는 이유는, KPConv 논문에서 자세히 설명한 바와 같이, 네트워크의 마지막 단계에서 실제 수용 필드가 몇 미터를 넘지 않기 때문입니다.
- 우리는 또한 네트워크가 아직 실시간으로 최적화되지 않았으며, 우리의 설정에서
초당 2프레임만 처리할 수 있다는 사실을 강조하고 싶습니다. - 이는 우리가 현재 시뮬레이션에서 작업하고 있기 때문에 문제가 되지 않습니다.
- 그러나, 우리는 구현의 병목 현상을 잘 알고 있으며 실제 실험을 위해 최적화를 염두에 두고 있습니다.
- 코드를 최적화하는 것 외에도, 성능과 계산 속도 사이의 절충점은 파라미터 dlin으로 설정할 수 있습니다.
- 예측 정확도의 손실을 감수하면서 실시간을 달성하기 위해 더 큰 서브샘플링 크기를 사용할 수 있습니다.
A. 실험 설정
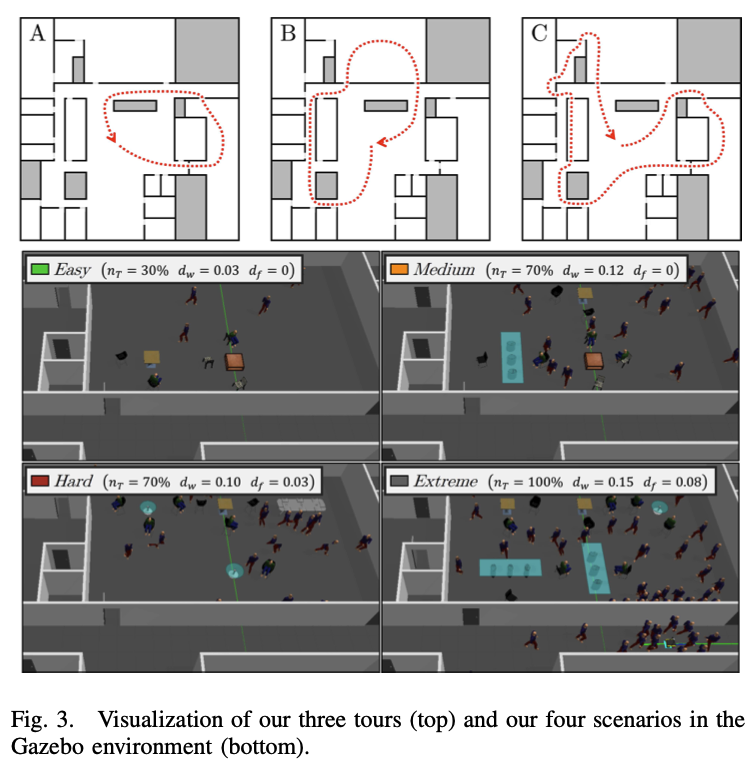
- 우리는 Gazebo 시뮬레이션에서 자가 주도 학습 접근법을 평가합니다.
- 각 시나리오는 그림 3에서 파라미터와 함께 볼 수 있습니다.
- 실험은 Intel(R) Xeon(R) E5-2698 v4 CPU와 네 개의 Tesla V100 DGXS GPU를 탑재한 DGX 스테이션에서 수행됩니다.
- 주석 처리 과정은 CPU만을 사용하며 평균 30분 이내에 1,000개의 라이다 프레임으로 구성된 전체 세션을 계산하는데, 이는 오프라인 작업으로 완전히 합리적입니다.
- 네트워크 훈련을 위해, 우리는 단일 GPU를 사용하고 약 10시간 만에 수렴에 도달합니다.
온라인 세션 동안, 우리는 위치 추정 알고리즘으로 PointMap을 사용- 그것의 ROS 구현은 평균 30fps 이상으로 실행
- 그러나, III-D 항에서 설명한 바와 같이, 네트워크 추론은 훨씬 느리며 한 프레임을 처리하는데 약 500ms가 걸립니다.
- 현재로서는 필요할 때 시뮬레이션을 일시 중지함으로써 이 문제를 해결하고 있으며, 향후 작업을 위한 최적화에 대해 확신하고 있습니다.
C. 네트워크 예측 평가
- 예상대로, 대부분의 지면, 벽, 움직이는 사람들의 점들은 우리 네트워크에 의해 각각 지면, 영구적, 단기로 예측되며, 최소 95%의 리콜을 가짐
- 나머지 클래스는 대부분 장기로 예측되지만 그렇게 확실하지는 않음
D. 다른 위치 추정 방법에 대한 개선
- 우리의 마지막 실험은 우리의 접근 방식이 다른 일반적인 네비게이션 시스템에 일반화될 수 있음을 보여줍니다.
- 위치 추정 방법인 AMCL과 두 가지 SLAM 알고리즘인 Gmapping, 초기 맵 없는 PointMap∗
V. 결론
- 시뮬레이션에서만 실행했음

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.