Learning Spatiotemporal Occupancy Grid Maps for Lifelong Navigation in Dynamic Scenes
global mapper
목록 보기
2/37
abstract
- Spatiotemporal Occupancy Grid Maps (SOGM)를 생성/예측/사용 하는 새로운 방법을 제시
- 자동 생성 과정을 통해 이전 항해 데이터로부터
SOGM의 ground truth을 만들어냅니다. - 우리의 전 논문은, lidar points를, 그들의 dynamic properties를 기반으로 annotation해서 SOGMs에 projection합니다.
- 3D 라이다 프레임을 입력으로 받아 SOGM의 미래 시간 단계를 예측하도록 훈련된 3D-2D 피드포워드 구조를 설계했음
- 우리의 파이프라인은 전적으로 자기감독 학습 방식이기 때문에, 로봇의 평생 학습을 가능하게 합니다.
- 이 네트워크는 아래 2가지로 구성
- 라이다 프레임의 풍부한 특성을 추출하고 semantic segmentation을 가능하게 하는 3D 백엔드
- planning 내에 내장된 SOGM의 future information를 예측하는 2D front-end
- 우리는 이 예측된 SOGM을 사용하는 navigation 파이프라인도 설계했습니다.
Introduction
- 우리의 이전 논문(https://arxiv.org/pdf/2012.05897.pdf)에 기반하여, 우리는 매핑 및 레이 트레이싱 알고리즘을 사용한 자동 주석 과정을 사용하며, 개별 라이다 포인트에 네 가지 의미론적 라벨을 제공
- 땅,
- 영구적인(벽과 같은 구조물),
- 이동 가능한(의자와 같은 아직 움직일 수 있는 장애물),
- 그리고 동적인(사람과 같은).
- 또한, 우리는 주석이 달린 라이다 포인트 클라우드를 SOGM으로 변환하는 시공간 점유 그리드 맵(SOGM) 생성 알고리즘을 제안
- 각 장애물 라벨마다 하나의 채널을 가진 SOGM이 있습니다.
- 그런 다음 우리는 과거 3D 라이다 프레임을 입력으로 받아 SOGM의 미래 시간 단계를 예측하도록 새로운 3D-2D 피드포워드 구조를 훈련시킵니다.
- 그림 1에서 보듯이, 예측된 SOGM은 기존 궤적 계획 알고리즘에 의해 처리되고 사용될 수 있습니다.
- 우리는 SOGM을 각 그리드 셀이 다른 셀로부터 독립적이며,
- 주어진 global 위치와 시간에 대한, occupancy 확률을 포함하는 3D 그리드 맵으로 정의
- 이것은 각 셀에 추가적인 속도 특성이 있는 동적 점유 그리드 맵과는 다릅니다.
- 우리 방법의 첫 번째 핵심 특징은 포인트 중심적이라는 것
- 객체 중심적인 방법과는 달리, 우리는 원시 센서 데이터에 더 가까워지며 본질적으로 다중 모달 예측을 허용
- 두 번째 특징은 SOGM의 채널로서 3가지 유형의 장애물을 포함하는 것
- 우리가 동적 장애물에 대한 예측에만 관심이 있다고 해도, 이 기능은 우리 네트워크에 중요한 특성을 제공합니다:
- 우리 네트워크는 미래의 움직임을 예측할 때 상호 작용을 고려할 수 있습니다.
- 예를 들어, 동적 장애물은 벽에서 튕기거나, 물체를 피하거나, 열린 문을 통과할 수 있습니다.
- 우리의 새로운 3D-2D 피드포워드 네트워크 구조는 3D 라이다 프레임에서 SOGM을 예측할 수 있음
- 네트워크 입력은 글로벌 맵에 정렬되고 병합된 연속적인 프레임으로, 공간적 및 시간적 정보를 모두 제공합니다.
- 우리 네트워크는 3D 백엔드로 시작하여, KPConv 레이어로 lidar frames을 처리해 (2D 그리드에 투영할 수 있는) rich features을 추출하거나 point cloud semantic segmentation에 사용
- 2D 그리드 rich features은 2D 프론트엔드 네트워크에 의해 처리되어 SOGM을 출력
- 이 2D 프론트엔드의 특징은 순환 연결 없이 피드포워드 방식이라는 점
- 연속적인 시간 단계에서의 occupancy 예측은 독립적인 weight를 가진 연속적인 컨볼루션에 의해 계산
- 이 논문의 주요 기여는 다음과 같습니다:
- 자동 SOGM 생성 방법
- 3 채널 SOGM을 예측하는 새로운 3D-2D 피드포워드 신경망.
- 추가적으로, 우리는 SOGM을 전체 항법 스택에 통합
- 먼저, SOGM은 충돌 위험을 반영하는 Spatiotemporal Risk Maps (SRM)로 변환되어, 점유된 공간과의 거리가 멀어질수록 선형적으로 감소
- 그런 다음 SRM은 수정된 Timed Elastic Band (TEB) local planner에 의해 사용
- TEB는 보통 세 차원 공간( x, y, t)에서 궤적을 최적화하여 이산 장애물과의 거리를 최대화하지만, 대신 SRM의 위험 값을 최소화하도록 조정되었습니다.
- 우리는 또한 몇 가지 개선사항과 함께 [1]에서의 triaging 아이디어를 유지
- 우리는 맵에 대해 라이다 프레임을 사용하여 위치를 찾음으로써 위치 파악에서의 지연을 줄이고,
- 분류된 프레임으로만 맵을 업데이트함으로써 triaging의 장점을 유지
related work
- 기존 논문들은 우리 접근법과는 두 가지 주요 차이점이 있습니다.
- 첫째, 과거 방법들은 모두 이전 OGM을 입력으로 사용하여, 일반적인 3D 센서가 포착할 수 있는 형태 패턴에서 소중한 정보를 잃습니다.
- 우리가 알기로, 우리는 3D 특성을 OGM의 예측에 통합함으로써 문헌에서 이 공백을 메운 최초의 사람들입니다. 우리 네트워크의 3D 백본을 사용하죠.
- 첫째, 과거 방법들은 모두 이전 OGM을 입력으로 사용하여, 일반적인 3D 센서가 포착할 수 있는 형태 패턴에서 소중한 정보를 잃습니다.
RISK-AWARE NAVIGATION SYSTEM
A. 자동 SOGM 생성
- SOGM의 groundtruth를 자동으로 생성함으로써, 우리는 인간의 개입 없이, self-supervised 방식으로 네트워크를 훈련시킬 수 있음
- 우리는 로봇의 생애 동안 만나는 새로운 상황에서 배울 수 있도록 [1]과 동일한 평생 학습 원칙을 따릅니다.
- 우리는 먼저 [1]의 방법을 사용하여 라이다 프레임을 주석 처리합니다.
- 포인트 클라우드 SLAM 알고리즘과 포인트 클라우드 레이-트레이싱 알고리즘의 조합이 사용되어 각 이전 항해 세션에 대한 포인트 클라우드 맵을 생성하고 주석을 답니다.
- 지면, 영구적, 이동 가능, 동적인 네 가지 의미적 라벨이 맵에 식별되어 각 세션의 라이다 프레임으로 되돌려지며, 이는 우리 네트워크의 3D 의미론적 분할 부분을 훈련시키는 데 사용됩니다.
- 그 다음 우리는 영구적, 이동 가능, 동적인 세 가지 장애물 클래스를 가진 SOGM을 생성할 수 있음
- rotating 그리드의 문제를 피하기 위해, 우리는 intermediate 2D 포인트 클라우드를 사전 계산하여, 훈련 중 그 2d pointcloud를 쉽게 회전시키고 SOGM으로 변환할 수 있습니다(그림 2 참조).
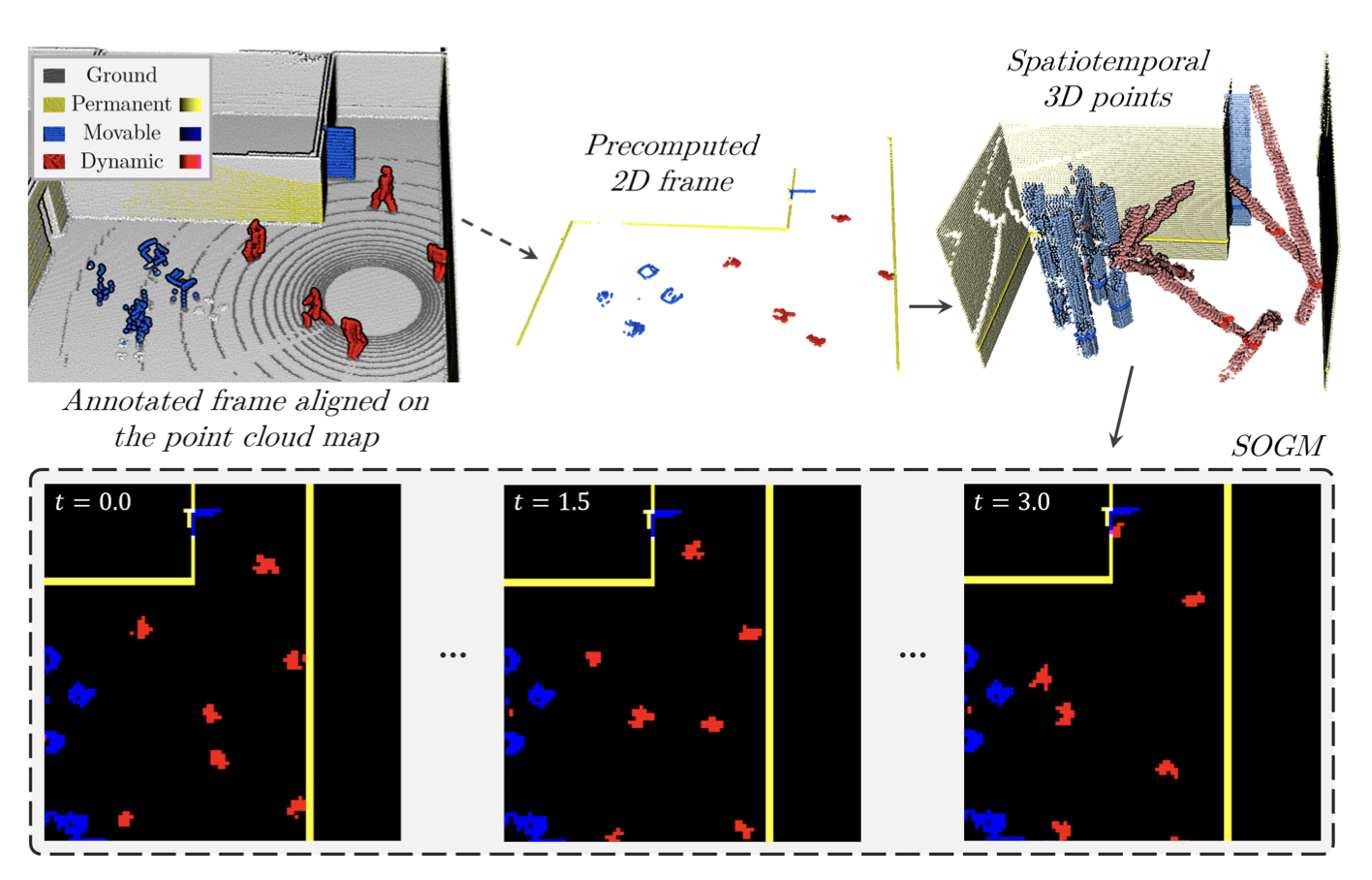
- 또한 이러한 sparse 구조는 전체 그리드보다 저장하기가 더 가볍습니다.
- 먼저, 각 주석 처리된 라이다 프레임은, 지면 포인트를 제거하기 위해 필터링
- 지면 평면에서 20cm보다 가까운, 또는 장애물 클래스로 주석 처리되지 않은 모든 포인트를 제거
- 그런 다음 모든 포인트를 지면 평면에 투영하고 3cm의 그리드 크기로 얻어진 2D 포인트 클라우드를 서브샘플링
- At training time, the 2D point clouds we need are loaded and stacked along a third dimension according to their timestamp.
- 데이터 증강을 위해 회전된 후, 이 시공간 포인트 클라우드는 공간 해상도 dl_2D = 12cm와 시간 해상도 dt = 0.1s의 SOGM 구조로 투영됩니다.
- SOGM의 모든 시간 단계에서 영구적 및 이동 가능 점유는 이동하지 않기 때문에 병합
- 따라서, 동적 장애물의 미래 위치뿐만 아니라, 우리 네트워크는 부분적으로 보이는 정적 객체를 완성하는 것도 배웁니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.