[Federated Continual Learning] Multi-modality를 활용한 1:N 관계의 Knowledge Transfer
소개
캡스톤 졸업 프로젝트로 진행하고 있는 연구에 대해 지금까지 공부하고 구현한 것들을 정리해보고자 한다.
개념 및 문제 상황은 아래와 같다.
- Continual Learning(지속 학습)이란 새로운 데이터를 학습하면서 기존에 학습한 지식을 잊지 않고 계속해서 학습을 이어가는 방식이다. 이때 새로운 데이터를 학습하는 과정에서 이전에 학습한 지식을 잃어버리는 catastrophic forgetting 문제가 발생한다.
- Federated Learning(연합 학습)이란 여러 장치가 각각의 로컬 데이터를 보유한 상태에서 협력적으로 모델을 학습하는 방법이다.
- 이 두 개념을 결합한 Federated Continual Learning은 엣지 장치들이 서로 이질적인 데이터를 처리하면서 지속적으로 학습을 이어가는 동시에, 장치 간의 간접적인 지식을 선택적으로 재사용하여 학습 성능과 일반화를 향상시키는 분산 학습 방식이라고 할 수 있다.
연구를 진행하면서 우리 팀이 해결하고자 한 세 가지 문제는 아래와 같다.
1. 먼저 실제 작업을 다룰 때는 multi-modality(이미지, 텍스트, 오디오 등)와 다양한 task 세팅이 존재하지만 우리 연구 분야에서 이러한 설정으로 연구한 사례가 없기 때문에 catastrophic forgetting 문제가 해결해야 한다.
2. 서버가 없는 decentralized 환경에서 raw data를 공유하면서 학습할 때에는 높은 communication cost, computation cost가 발생한다.
3. 이전 연구에서는 장치 간 1:1 관계에서 knowledge transfer을 진행했었는데 이 방식은 device 간 협력적인 knowledge transfer 방식보다 학습 효과가 낮을 것으로 기대된다.
따라서 우리 연구는 Multi-modality와 서버가 없는 decentralized한 세팅에서 1:N 관계의 knowledge tranfer의 실험을 통해 Federated Continual Learning 아키텍처를 구현하고자 하였다.
논문 스터디
지금까지 존재하는 관련 연구를 공부하기 위해 우리 팀은 8,9월 동안 함께 논문 스터디를 진행하였고, 개인적으로도 많은 논문을 읽어가며 연구에 대한 방향을 잡을 수 있었다.


선행 실험
우리 연구는 ECCV 2024에 채택된 연구논문인 'Pick-a-back: Selective Device-to-Device Knowledge Transfer in Federated Continual Learning'를 기반으로 연구 방향을 잡았다. 따라서 공개된 코드를 돌려보면서 어떤 구조의 아키텍처인지 분석하는 과정이 필요했다. 돌려본 코드는 baseline, wo_backbone, w_backbone으로 ipynb파일로 analysis 하였다.

Multi-modality 설계
엣지 환경에서의 Continual Learning 실험을 설계하기에 앞서, 다양한 형태의 입력 데이터를 처리하기 위한 아키텍처를 구상하였다.
task
먼저 예비 실험을 위해 간단한 image-text classification task를 선택하였다.이는 주어진 이미지와 텍스트 데이터를 결합하여 특정 클래스를 예측하는 작업으로, 예를 들어 이미지와 이미지를 설명하는 캡션이 입력값으로 주어졌을 때 이를 바탕으로 카테고리를 분류하는 것이 가능하다.
dataset
우리 팀은 N24News dataset을 선택하였다. N24News 데이터셋은 뉴스 데이터를 기반으로 수집된 데이터셋이다. 각 뉴스는 24개의 카테고리 중 하나에 속하고, 카테고리 당 3000개의 샘플을 포함하며 각 샘플은 하나의 이미지와 하나의 이미지 캡션을 포함하는 데이터를 가지고 있다. 데이터셋과 관련하여 나의 역할은 이 데이터셋에서 샘플 당 이미지와 캡션을 추출하여 데이터 전처리를 거쳐 입력 데이터를 구축하였다.

모델
Perceiver 모델의 아키텍처는 Transformer 모델의 한계를 해결하여 다양한 입력 데이터를 효율적으로 학습시킬 수 있는 딥러닝 모델이다. 우리 팀은 Perceiver 모델을 활용하여 이미지와 텍스트 입력 데이터를 처리하는 image-text classification 작업을 수행하고자 했다.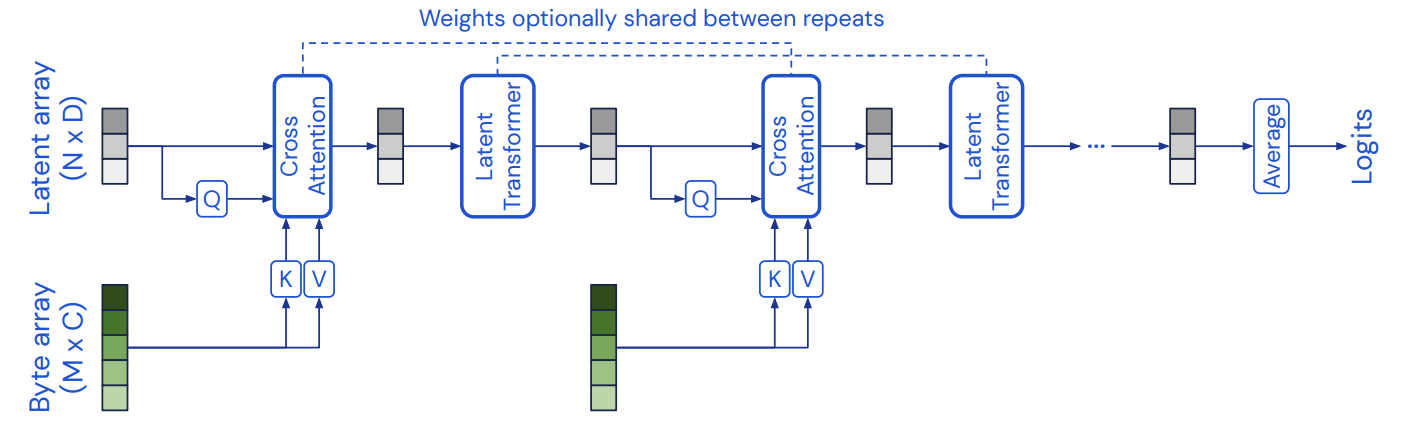
이전에 유명했던 CNN이나 BERT는 이미지가 인풋일 때 공간적인 관계를 특정해놓고 있기 때문에 다른 모달리티에 적용하기가 어렵다. 반면, Perceiver 모델의 경우에는 파라미터 수가 일반 오토인코더보다 적고, 다양한 모달리티를 입력으로 처리할 수 있기 때문에 우리의 연구에 적합한 모델이라고 판단했다. Perceiver 모델의 코드를 사용하여 multi-modality의 입력값을 처리할 수 있는 모델을 구현하고 있는 중이다.
앞으로의 작업
image-text classification에 대한 성능이 괜찮다면 이제 엣지 장치들에게 각각 주어진 task를 할당시키고 선택적으로 지식 전이를 했을 때의 catastrophic forgetting 문제가 발생하는지 확인이 필요하다. 그리고 해당 문제에 대한 솔루션을 하나씩 적용해봐야 한다. 가장 먼저 pick-a-back 연구에서 적용했던 piggyback, CPG, PackNet을 통해 지속 학습에서의 개선을 수행할 예정이다. 또한 이전 실험에서는 1:1 관계에서 장치 간의 지식 전이를 수행했다면, 추후에는 1:N 관계에서의 지식 전이를 수행할 예정이다. 여러 정치의 지식을 aggregate 후, 다른 장치에 전달했을 때 catastrophic forgetting 문제가 해결되는지 검증하는 것이 또 하나 해결해야할 문제이다.
