Intro: 기존 Diffusion Model의 한계
Diffusion Model(Glide, Imagen, DALLE2 등)의 한계는
- 특성 상 이미지 픽셀값을 바로 생성해야 하기 때문에 저화질 이미지만을 생성한다는 것
- computational cost가 너무 크다는 것 → training, evaluating 과정에서 모두 큰 시간과 메모리 비용이 소모됨
⇒ Training과 sampling 모두의 계산 복잡성을 줄일 수 있는 방법이 필요함, 성능을 저하시키지 않으면서 계산 요구량을 줄여야 함!
💡 제안된 Latent Diffusion Models(LDMs)의 훈련 방식: 1. 지각적으로 동등하면서도 낮은 차원의 표현 공간을 사용하도록 autoencoder를 훈련시킴. 2. pretrained autoencoder는 여러 diffusion model 학습에 재사용되거나 서로 다른 task(image-to-image 또는 text-to-image) 탐색에 사용됨.Method
Autoencoding 모델을 활용하는 방식으로 학습 단계에서 압축 과정을 별도로 분리한다. 이를 통해 이미지 공간과 perceptual하게 동등한 공간을 학습하지만 상대적으로 복잡성이 덜한 계산을 할 수 있다.
Perceptual Image Compression
image data x가 있다고 치자, 인코더 E(x)로 잠재 표현(latent representation) z가 인코딩되어 도출된다. 그리고 z는 디코더로부터 이미지를 재구성한다.
이 과정에서 인코더는 이미지 x를 downsample한다.
LDM은 latent space을 이용해 기존 DM과 다르게 약한 압축률을 사용하기 때문에 우수한 재구성 가능하다.
Latent Diffusion Model
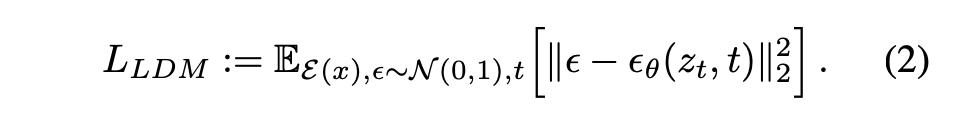
Latent Diffusion Model의 Loss Function은 위와 같다. Autoencoder로 정보를 압축하기 때문에 latent space에 접근하게 되고, 이로써 perceptual하지 않은 noise 정보는 최대한 제거되어 semantic한 특성은 증대되고 계산 복잡성은 감소한다.
이는 기존에 attention-based transformer model을 사용해 많이 압축했던 것과 다르게 이미지별 inductive bias를 활용하여 2D convolutional layer로 U Net을 구성하기 때문에 perceptual하게 관련성이 높은 비트에 목적 함수를 더 집중시킨다.
Conditioning Mechanisms
LDM은 다양한 modality를 인풋(y)으로 적용하기 위해 cross attention mechanism을 사용한다. 여기서 다양한 modality로부터 y를 전처리하기 위해 도메인별 인코더 를 사용한다. 이를 통해 중간 representation으로 보내고, cross-attention layer를 통해 U Net의 중간 layer에 맵핑한다.
Cross-attention layer는 아래와 같다.
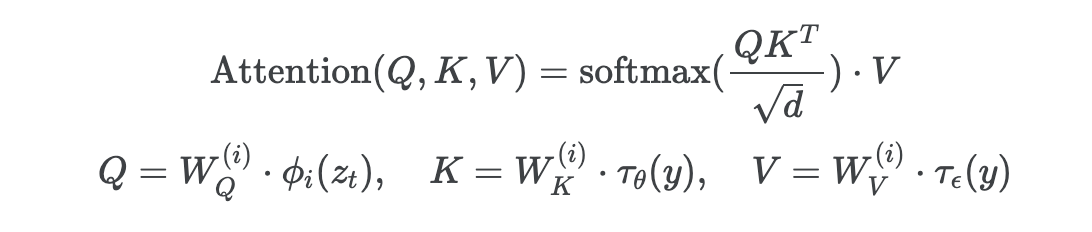
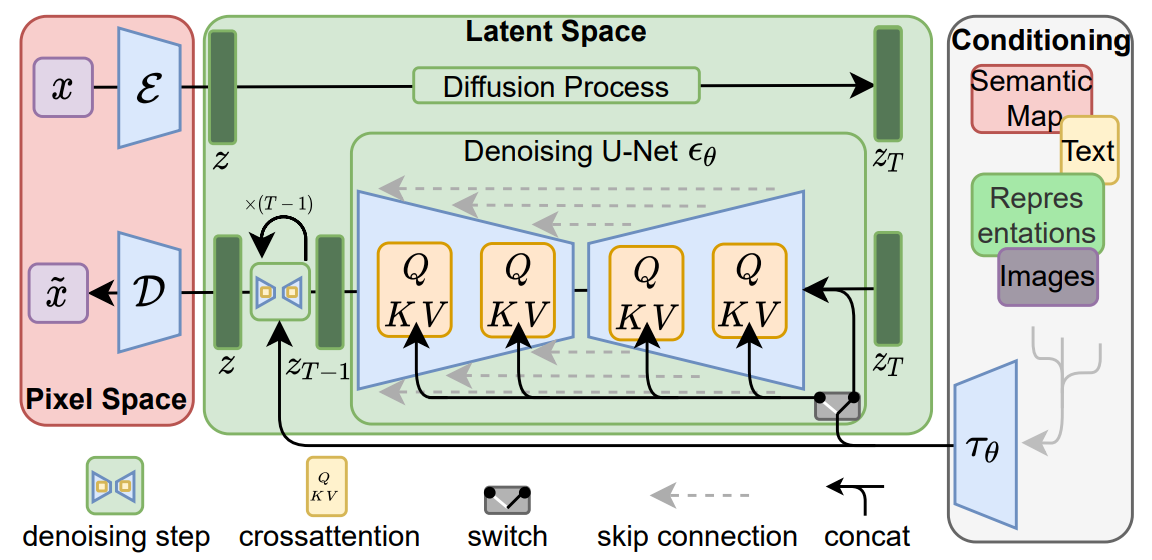
LDM의 자세한 아키텍처:
다음 식을 통해 Conditional LDM을 학습시킨다.
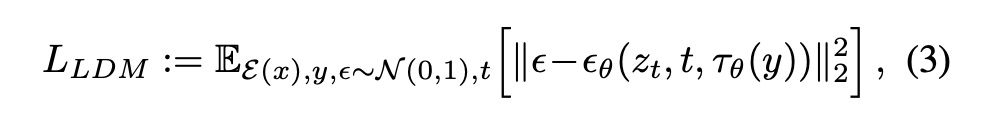
이 식에서 Condition encoder 와 DDPM 는 연결되어 동시에 최적화된다. Latent Embedding z, Process Time t, Condition y까지 모두 반영되었다.
Experiments
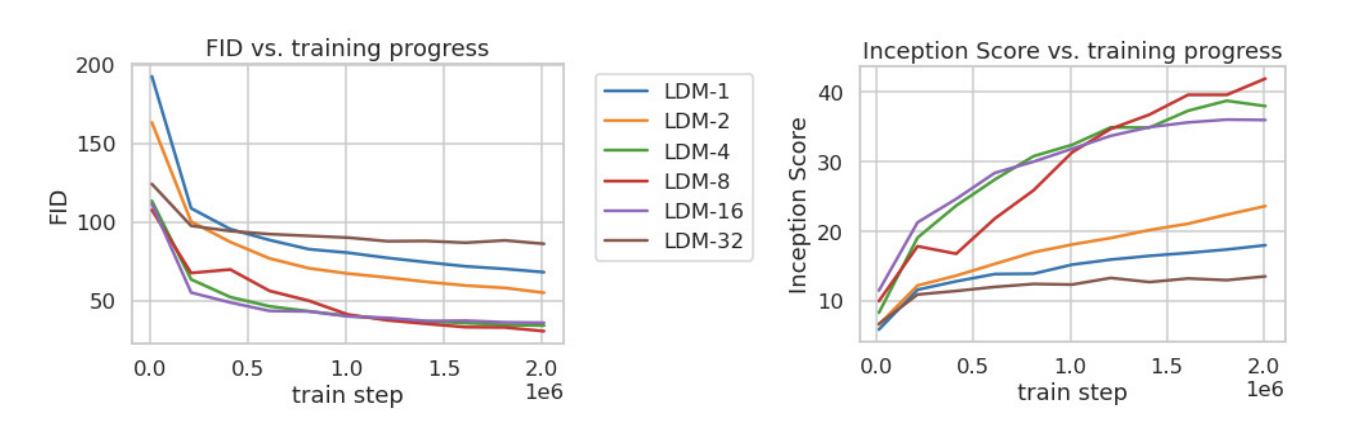
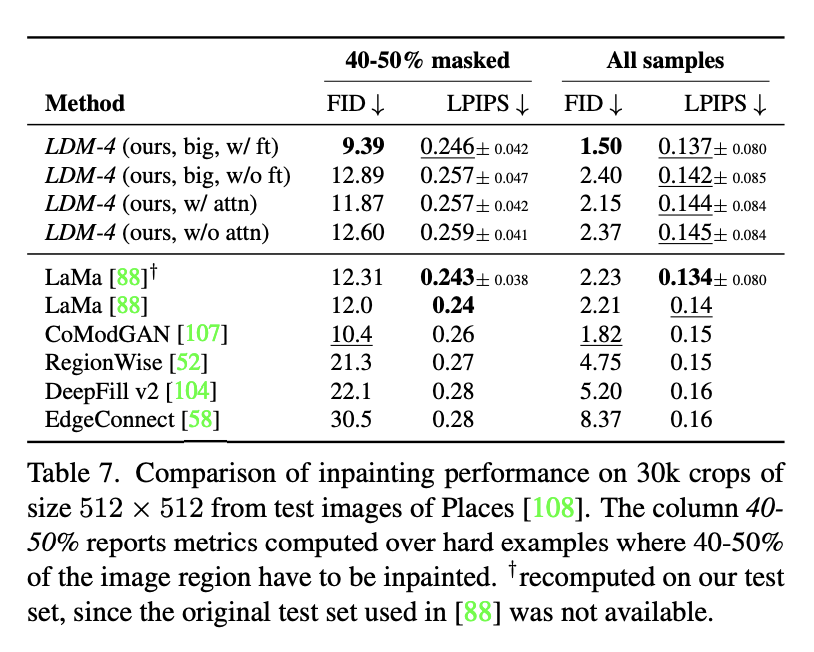
LDM - f의 f는 downsampling scale factor이다. 따라서 다양한 f로 훈련을 해봤을 때 f가 4-16로 적용했을 때 좋은 FID가 도출되었고, LDM-32의 경우엔 너무 많은 다운 샘플링을 적용해서 성능이 낮았다. (LDM - 1는 다운샘플링하지 않은 기존 pixel-based DM이라고 생각하면 된다.)
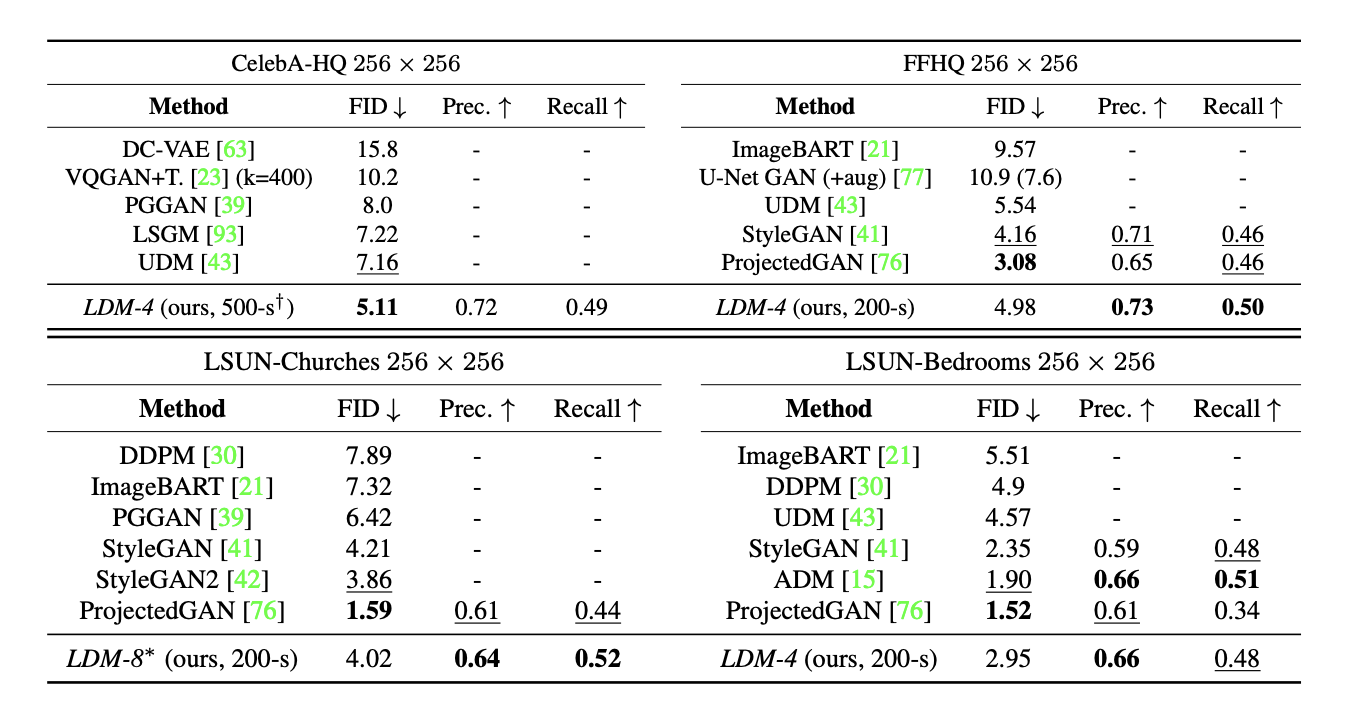
Unconditional image synthesis에 대한 평가로는 여러 데이터셋과 모델에 대한 FID(낮을수록 좋음)와 Precision(정밀도, 높을수록 좋음), Recall(재현율, 높을 수록 좋음)을 비교했을 때 LDM-4이 대체로 좋은 FID와 정밀도, 재현율을 보여주었다.
Conditional imge synthesis로는 inpainting만 보겠다.
Inpainting with Latent Diffusion
Inpainting
이미지 inpainting이란 이미지의 손상된 부분을 복구하거나 기존의 부분을 새로운 부분으로 교체하는 작업이다.
→ 인페이팅 모델 LaMa의 프로토콜로 Fast Fourier Convolutions을 사용하는 아키텍처로 설계함.