Abstract
Over the past few years, Federated Learning (FL) has become an emerging machine learning technique to tackle data privacy challenges through collaborative training. In the Federated Learning algorithm, the clients submit a locally trained model, and the server aggregates these parameters until convergence.
연합 학습(Federated Learning, FL)은 데이터 프라이버시 문제를 해결하기 위한 새로운 ML 기법으로 떠오르고 있는 추세이다. 연합 학습 알고리즘에서 client는 로컬에서 학습한 모델을 서버에 제출하고, 서버는 이를 종합한다.
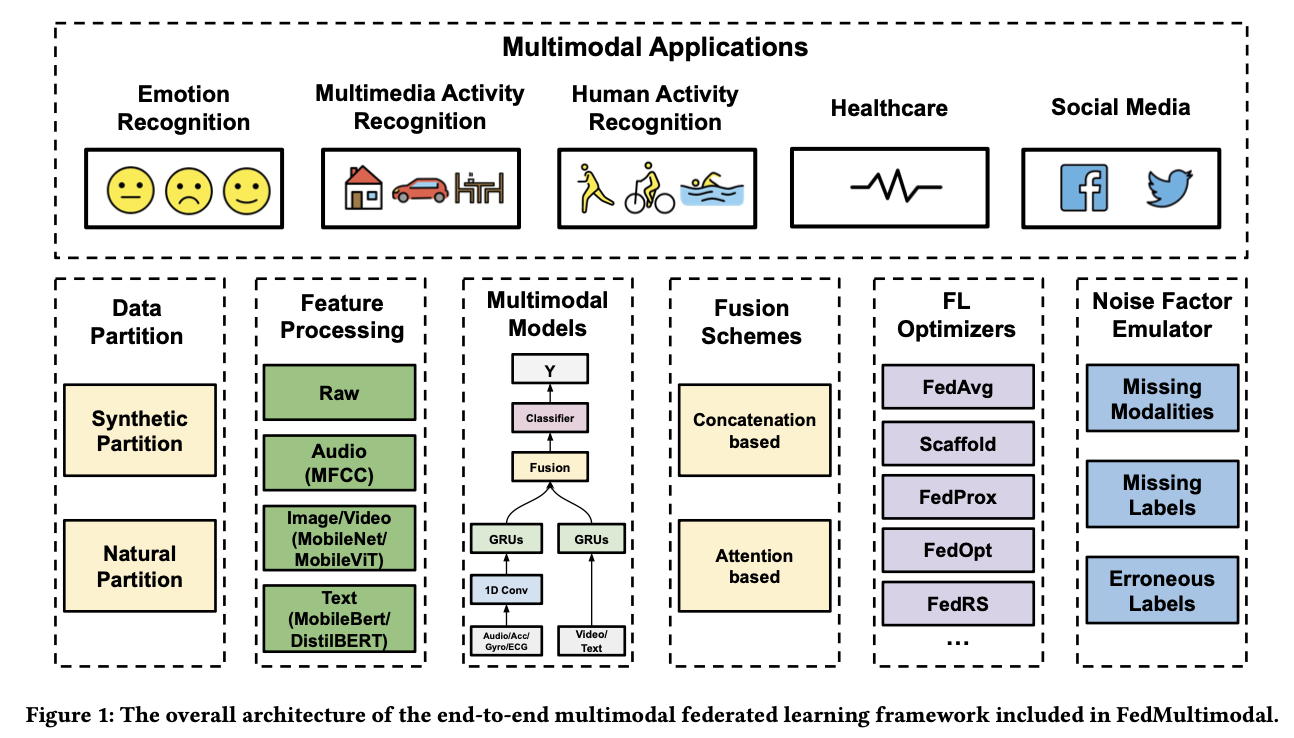
... In order to facilitate the research in multimodal FL, we introduce FedMultimodal, the first FL benchmark for multimodal learning covering five representative multimodal applications from ten commonly used datasets with a total of eight unique modalities. FedMultimodal offers a systematic FL pipeline, enabling end-to-end modeling framework ranging from data partition and feature extraction to FL benchmark algorithms and model evaluation.
다중 모달(multimodal) 연합 학습 연구를 촉진하기 위해 FedMultimodal을 소개한다. 이는 다중 모달 학습을 위한 첫 번째 연합 학습 벤치마크로, 10개의 흔히 사용되는 데이터셋에서 5가지 대표적인 다중 모달 응용 프로그램을 다루며 총 8개의 고유한 모달리티를 포함합니다. FedMultimodal은 데이터 분할, 특성 추출부터 연합 학습 벤치마크 알고리즘과 모델 평가까지 포괄적인 연구 프레임워크를 제공한다.
데이터셋과 벤치마크 결과: https://github.com/usc-sail/fed-multimodal
기존 모델: FedAvg
local model update -> submit to the server
=> data heterogeneity로 인한 gradient drift 발생 & slow convergence
FedMultimodal Framework
1. non-IID data partitioning
- unique client identifier - realistic client partition 있음 -> 같은 ID끼리 partition
- 일부 datasets(MAR, SM) - requires ML practitioners(to synthesize non-IID data) => use Dirichlet distribution
2. feature processing
효율적인 컴퓨팅을 위해 mobile-friendly feature extraction에 집중
-> swift computation, efficient storage, ease of deployment
Visual - MobileNetV2, MobileViT
Text - MobileBERT, DistillBERT
Other Modalities - raw data로 사용
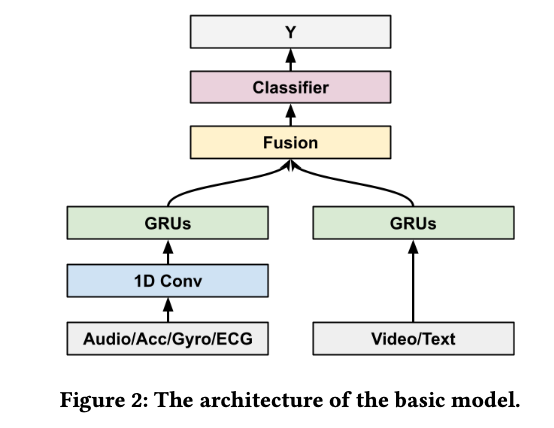
3. multimodal models
- principle
resource-constrained 디바이스이기 때문에 parameter 개수 최소화가 중요 - model architecture - mainly based on the 1D Conv-RNN/MLP
설계 = enocoder + modality-fusion block + downstream classifier
encoder -> Conv+RNN (audio, accelerometer, gyroscope and ECG info) or RNN-only(otherwise)
modality-fusion block -> 서로 다른 modality를 combine하기 위해서 late-fusion mechanism 사용
downstream classifier -> 2 dense layers
4. fusion schemes
approaches: concatenation-based fusino & attention-based fusion
(우리는 여기에 local weight, attention score 와 meta-learning 도입 예정)
concatenation-based fusion - GRU output 때 average pooling operation 실행 -> pooling embeddings를 concat
attention-based fusion - average pooling 없이 각 modality의 temporal output을 concat
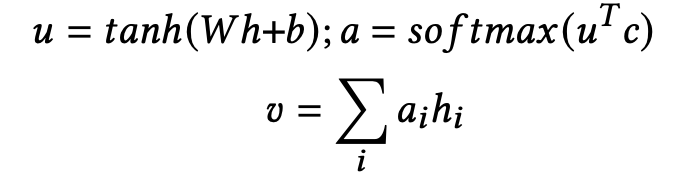
h = concatenate된 multimodal 데이터
h 인풋 → 1 layer MLP ⇒ u (representation)
softmax function ⇒ a (normalized importance score)
⇒ v 계산(final multimodal embedding)
5. federated optimizers
주로 FL training 알고리즘은 unimodal에서 검증됨.
multimodal로 학습시켰을 때 알고리즘 중에서는 FedOpt가 성능 면에서 좋았음.
6. real-world noise factor emulator
=> Missing modalities, labels, erroneous label 등 real-world에서 적용 가능
-
Missing modality
modality 정보가 불완전한 경우에 synthesize할 수 있는 emulator module 필요.
-> q(equal misiing rate)를 설정 -
Missing labels
실제로는 label 없는 data가 많을 수 있음 -> robustness 줄어드는 위험 -
Erroneous labels
bias로 인한 label noise, 사람으로 인한 label error가 발생할 수도 있음
-> label error generation process 적용
Experiments and Discussion
Setup
RNN-only: video & text
Conv(feature 추출)-RNN(분류): 나머지 modality
→ 3 Conv layers (filters {16, 32, 64}, filter kernel size 5x5) + RNN의 hidden layer size 128
→ ReLU : activation function (dropout rate: 0.2)
→ #attention heads: 6
Performance
attention-based fusion >> concatenation-based fusion
→ 특히 high data heterogeneity 일 때 attention-based가 성능↑
data heterogeneity 이슈가 있는 Federated learning에서는 fusion mechanism이 중요.
Uni-modality vs. Multi-modalities
uni모달일 때도 경쟁력 있긴 하지만 multimodal learning still outperforms unimodal learning
Missing modalities 의 경우
attention-based fusion을 사용하면 modality missing의 경우에도 적용o
결과
→ missing rate이 30%아래 : 성능 비슷
→ 50%이상부터 성능이 급격히 줄어들음.
=? CrisisMMD data와 HAR application일 때 다른 multimodal dataset에 적용했을 때보다 크게 성능이 줄어든 것 발견.
Limitations and future work
Scale of Datasets & Models
→ FedMultimodal는 medical image analysis나 autonomous driving, virtual reality 등의 application은 적용하지 못했음.
Scale of Modality Fusion Schemes
여기서는 concatenation & attention based fusion mechanism 만 다룸
→ FL에서의 Modality fusion 는 더 다양하게 개발될 필요가 있음
Data Heterogeneity
FL에서 data heterogeneity를 다루는 것 중요.
Label Scarcity
FL에서 lack of qualitative labels 문제가 있음. → self-supervised learning(자기지도학습) 알고리즘으로 multimodal FL을 개선할 수도 있겠음
Privacy Leakage
FL는 model update만 공유하기 때문에 더 private하지만, 여전히 privacy attack에 취약함.
→ membership inference attacks, reconstruction attacks, attribute inference attacks 등의 공격에 방어해야 함.
