[Federated Continual Learning] PerceiverIO+CUB 데이터로 학습시킨 모델 간의 DDV 거리 기반 유사도 분석하기
이제 25-1 졸업 연구도 막바지에 이르러 전반적인 실험이 완성되었다. 애초에 계획했던 계획대로 실험이 진행되지 못했고 결과도 예상 밖이지만 어느정도 유의미한 결과가 도출되었기 때문에 의미있었던 실험 내용을 바탕으로 구현 과정을 소개해보고자 한다.
먼저 여러가지의 multi-modal 데이터셋(이미지, 텍스트)과 여러가지의 모델들을 조합해서 실험한 결과, 연구에 최종적으로 사용하게된 것은 PerceiverIO 모델과, CUB-200-2011 데이터셋이다.
PerceiverIO 모델
처음 연구를 설계하며 우리가 고려했던 모델은 구글 딥마인드에서 제안한 Perceiver 모델이었다. 이유는 해당 모델이 모든 모달리티(이미지, 텍스트, 비디오 등) 입력을 동일한 구조로 처리할 수 있고, 기본적으로 classification 태스크에 최적화되어 있기 때문에 가장 적합하다고 판단했기 때문이다. 그러나 실험을 진행하면서 Perceiver 모델이 입력을 여러번 받기 때문에 우리의 최종 task인 지식 전이를 하기 위해 구조상 문제가 있다는 것을 발견하게 되었다. 따라서 마찬가지로 구글 딥마인드에서 후속 연구로 제안한 모델인 PerceiverIO 모델을 채택하게 되었다.
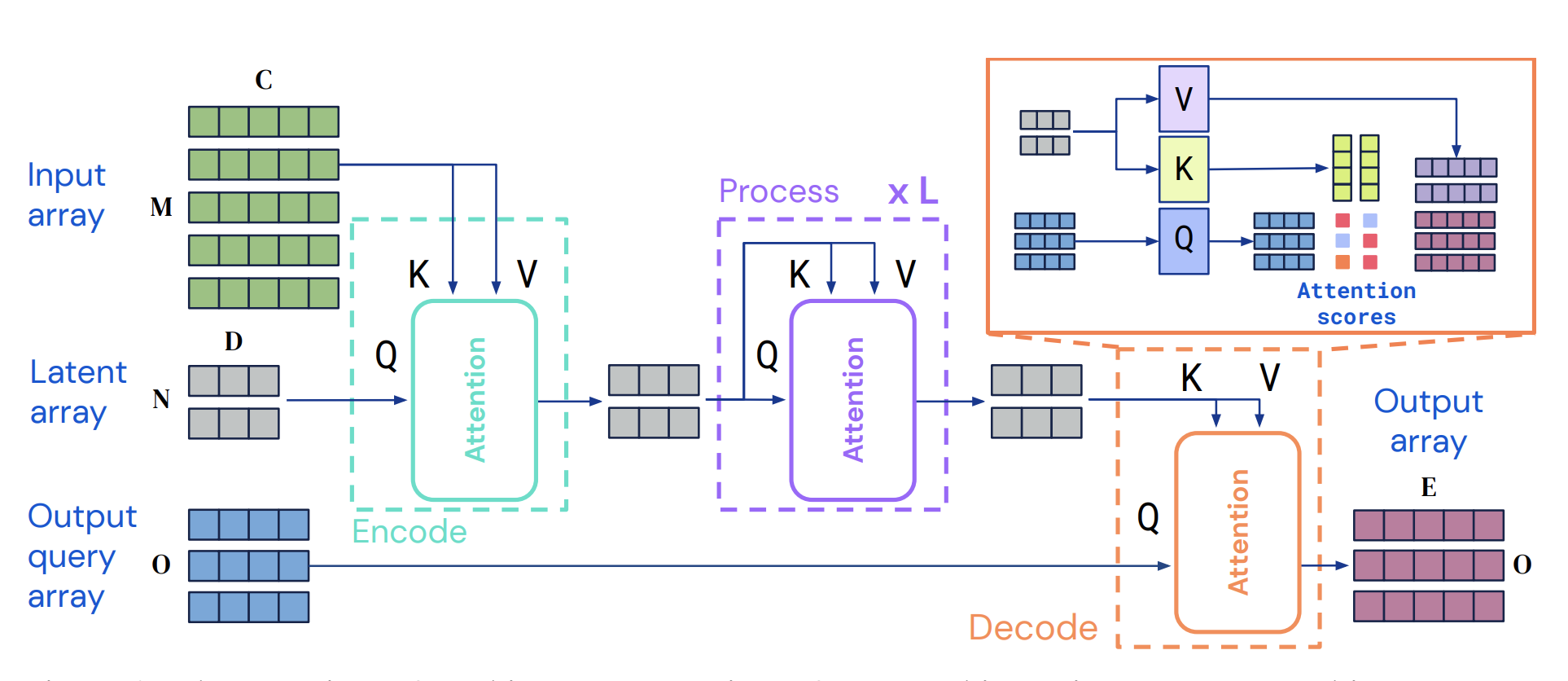
PerceiverIO 모델은 인코더에서 cross-attention을 한 번만 거치고 이후에 여러번 self-attention을 거치기 때문에 지식 전이하기 위해 구조상 조정해야할 부분이 명확해 오히려 우리 연구에 적합하였다. 이후 설명하겠지만, 이 모델 구조로 인해 우리 연구에서 구현해야 할 modeldiff 방식이 명확하게 결정되어 또한 도움이 되었다.
CUB-200-2011 데이터셋

우리가 채택한 데이터셋 중 하나인 CUB-200-2011 데이터셋 또한 이미지 분류를 위한 대표적인 벤치마크 데이터셋이다. 주로 딥러닝 기반의 object recognition, fine-grained classification, localization 등의 태스크에 사용된다.
특히, 이 데이터셋은 처음 제안되었을 때는 오로지 이미지와 라벨밖에 없었는데 이후에 다른 연구에서 각각의 이미지를 설명하는 텍스트 description이 제공되어 그렇게 멀티 모달 데이터셋을 준비할 수 있었다.
위와 같이 모델과 데이터셋이 마련되었고, 전처리 방식은 아래 순서를 따랐다:
1. 데이터셋의 클래스 수와 클래스에 속한 데이터 수를 확인한다.
2. 클래스에 속한 데이터 수가 60인 클래스들만 선별한다.
3. 해당 클래스들을 5개씩 묶어 하나의 그룹으로 만든다.
이렇게 28개의 이미지 데이터 그룹, 28개의 텍스트 데이터 그룹이 준비되었다.
Multi-modal 데이터 기반 모델 간의 백본 공유 가능성 분석
이 부분에서는 PerceiverIO 기반의 총 56개의 데이터 그룹으로 학습시킨 멀티모달 모델들 간 서로 다른 내적 표현의 유사성을 비교하기 위한 DDV(Distance Distribution Vector) 실험을 구현한 과정을 소개하겠다.
해당 실험은 모델의 cross-attention 레이어에서 생성된 key-value 쌍을 이용해서 latent representation 유사도를 측정하고, 이를 통해 target이 되는 모델과 가장 유사한 backbone이 되는 모델을 선택하는 것을 목표로 하였다.
실험 목표
- 서로 다른 데이터셋 그룹에서 학습된 PerceiverIO 모델 두 개의 유사도를 측정
- 유사도 측정은 attention layer의 key-value vector에 작은 𝓔 perturbation을 주어서 모델의 출력을 관찰하는 방식으로 진행된다.
- 모델 안에서 측정되는 DDV를 기반으로 cosine/euclidean 유사도를 계산하고, backbone 선택 기준으로 사용한다.
먼저 각각의 데이터 그룹으로 PerceiverIO 모델을 학습시킨 56개의 Baseline 모델들을 구축한 이후에 이 과정을 진행할 수 있다는 것을 유의해야 한다.
우리가 사용한 modeldiff 방식을 구현하기 위해 DDV metric을 사용했다.
DDV(Decision Distance Vector)는 두 모델이 서로 다른 데이터를 얼마나 비슷하게 인코딩하는지 정량화하기 위해 사용하는 출력 간 거리의 일관성을 비교하는 방식이다.
1. Cross-attention KV 추출 함수 구현
이 부분이 우리가 PerceiverIO의 연구 적합성을 감증한 부분이었다. 앞서 설명했듯이, Perceiver와 다르게 PerceiverIO 모델은 입력이 한 번만 들어가기 때문에 cross-attention이 한 번만 진행된다. 그래서 우리가 추출하고자 하는 key-value 쌍이 명확했고 명쾌했다.
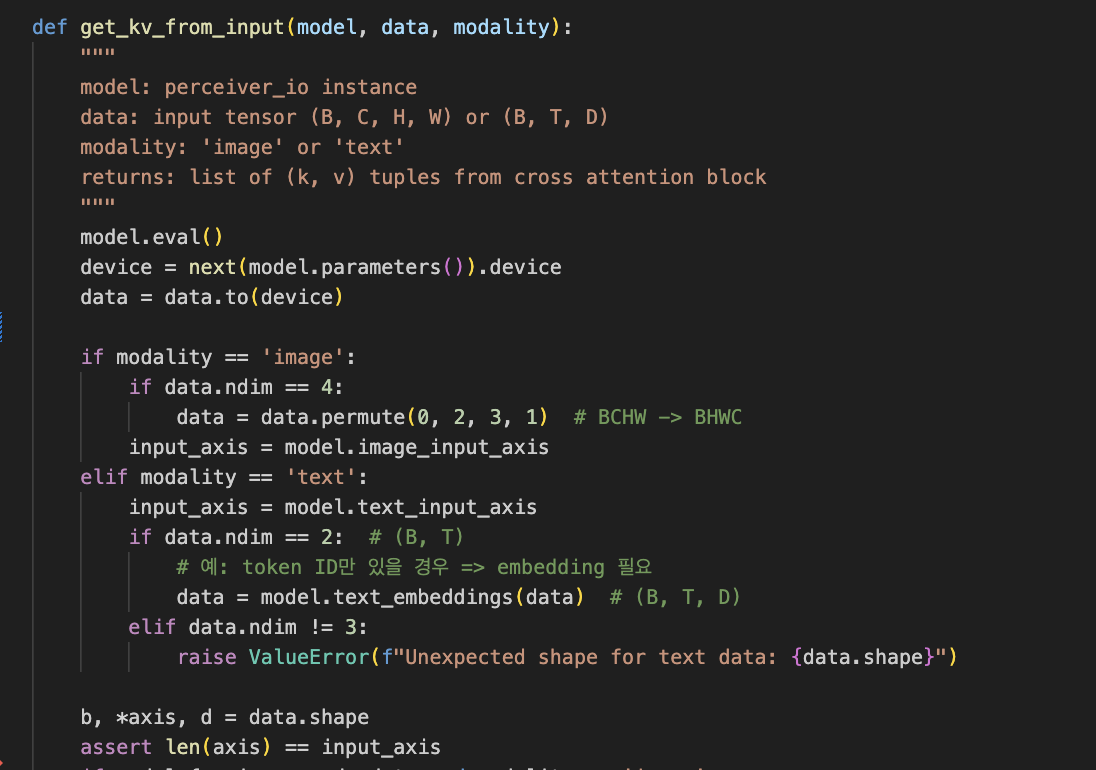
cross-attention에서 (key, value)를 추출하는 로직을 정확히 구현하는 것이 처음에는 조금 헷갈렸다. 특히 텍스트와 이미지에 따라 처리하는 방식이 달라져서 조건 분기를 잘 관리해야 했다.
모델의 forward를 monkey patch하여 외부에서 kv injection 가능하게 구현
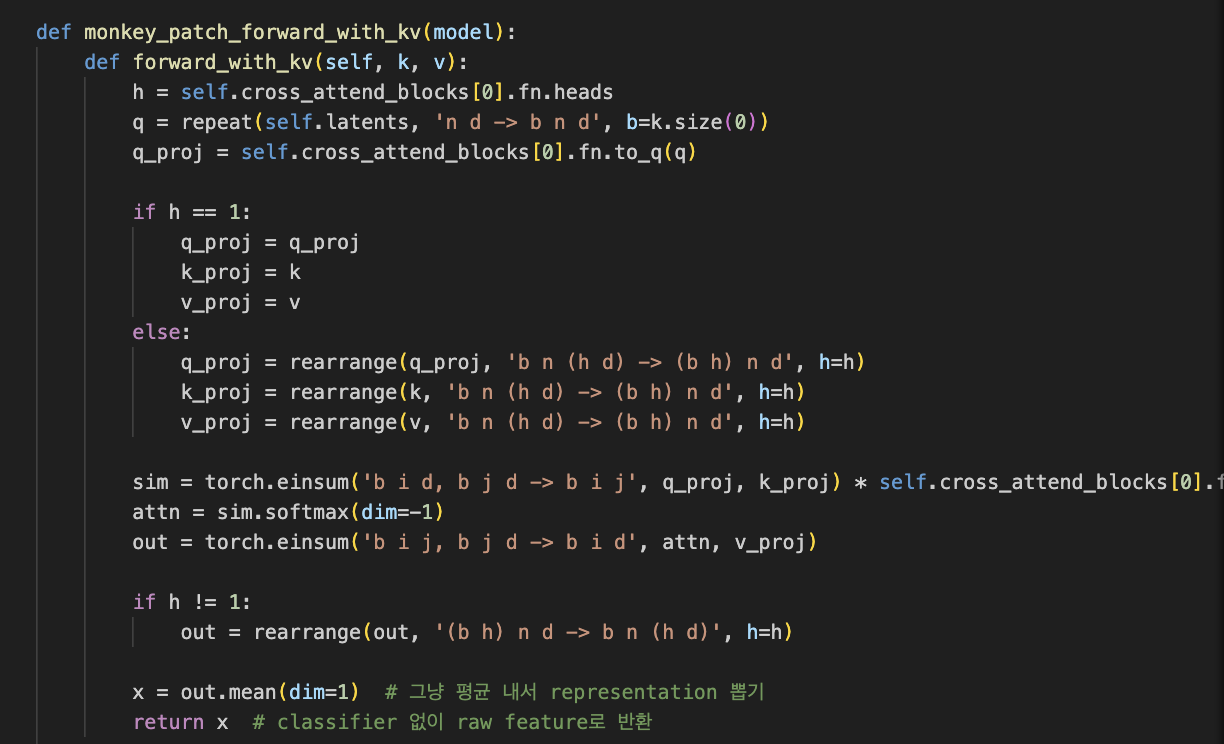
monkey patch 방식으로 구현한 이유는 기존 모델의 forward를 바꾸지 않고 외부에서 kv를 직접 넣기 위해서였다. MethodType 사용 방식도 조금 생소했지만, 나중에는 다양한 실험에 유용하게 활용할 수 있었다.
Key-value Mutation 함수 구현
cross-attention layer에서 추출한 key-value는 이후, 두 모델의 key끼리, 두 모델의 value끼리 concat된다. 그렇게 concat된 k_all과 v_all에는 𝓔 perturbation을 적용하여 모델 출력 차이를 증폭시킨다.
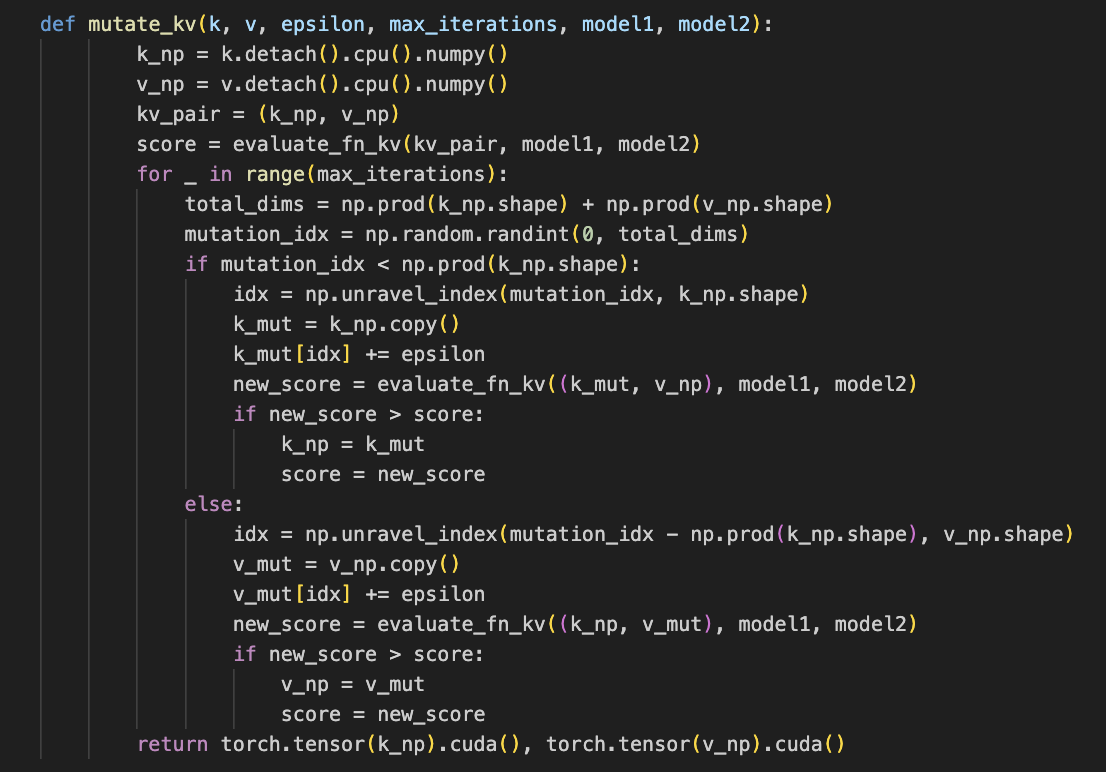
mutation할 좌표를 랜덤으로 골라 epsilon만큼 조정하는 과정을 거쳤다. epsilon 값은 일반적으로 가장 적정한 값인 0.5로 적용하였다.
DDV 유사도 계산 함수 정의
마지막으로 두 모델의 DDV를 비교하기 위해 cosine/euclidean 거리 기반 지표를 작성하였다.
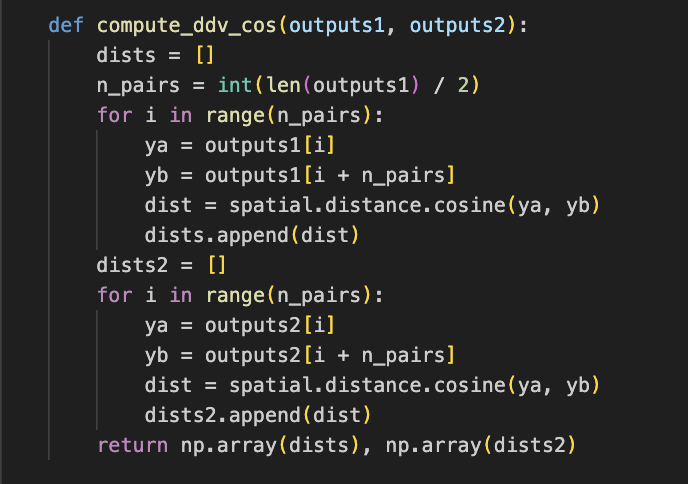
해당 코드에 앞서 k_all, v_all에 mutation 적용시킨 k_mut, v_mut 입력에 대해 두 모델이 각각 feature vector인 outputs1, outputs2를 출력했다는 것을 인지하고 있어야 한다. DDV 벡터 유사도는 먼저, 각 출력된 벡터를 절반으로 나눠 짝을 지어 내부 유사도를 계산한다. 그리고 이 쌍들 사이의 거리를 cosine/euclidean으로 계산하여 리스트 ddv1, ddv2에 저장하는 방식으로 계산된다. ddv1, ddv2는 각각 모델1, 모델2에서 계산한 pairwise 거리 벡터이고 이것이 ddv 거리이다.
결과
이런 식으로 각 target_id에 대해 최적의 백본으로 찾은 task_id가 출력되어 csv 파일에 따로 저장된다. 모든 target_id가 같은 모달리티의 task_id 만 선택했다는 사실을 발견하였다. 그렇다면 크로스 모달리티를 강제로 선택하게 하는 방법을 사용하면 어떨까? 여기서 우리는 유의미한 결과를 얻을 수 있었다. 이후에 팀원이 구현하였지만, 위와 같이 설명했듯이 출력된 모델과 백본 모델 쌍 간의 지식 전이를 진행했을 때 모델이 가장 자기와 유사하다고 판단한 크로스-모달 백본 모델과 지식 전이를 한 경우, 성능이 어느정도 개선되었다는 점을 찾을 수 있었다.
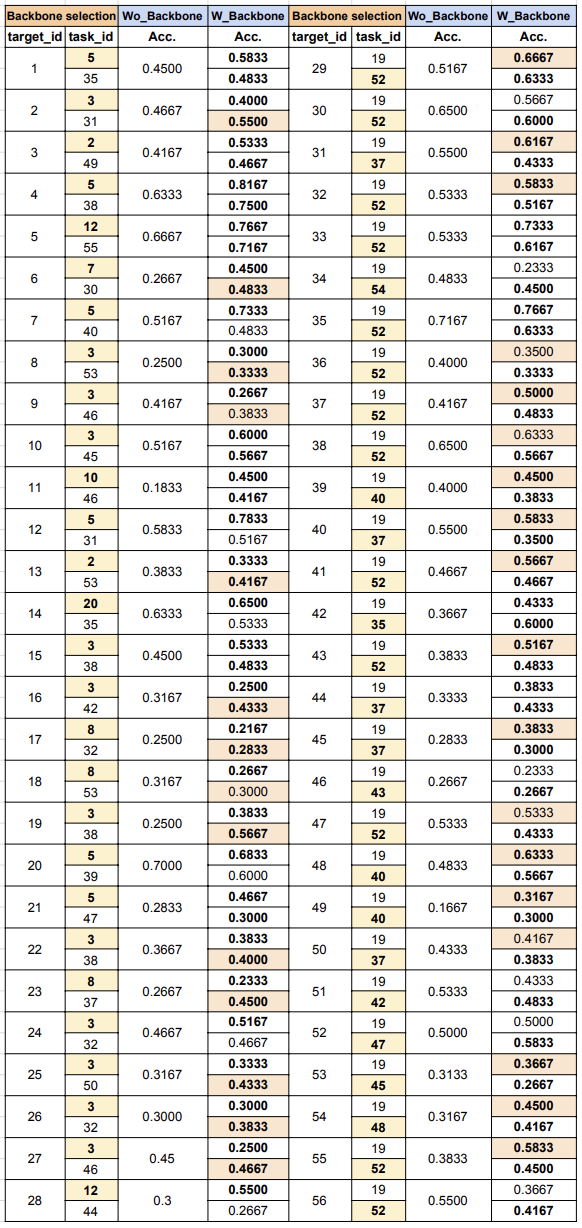
위의 표는 우리 실험의 결과를 기록한 시트이다.
시트를 통해 image 모델이 text 백본으로 성능이 개선되는 경우가 20/28, text 모델이 image 백본으로 성능이 올라가는 경우도 18/28로 과반이 넘는 케이스가 해당되었다. 심지어, image 모델이 image 백본보다 text 백본으로 성능이 더욱 개선된 케이스는 14/28, text 모델이 text 백본보다 image 백본으로 성능이 더욱 개선된 케이스는 18/28로 꽤나 실험적인 의의가 있는 결론이 도출되었다.
