
Session Review
Model Selection
model selection process
1) Estimated the parameters for the machine learning methods (= training the algorithm)
2) Evaluate how well the machine learning methods work -> figure out whether this curve will give a good prediction on new data (= testing the algorithm)
-> 똑같은 데이터로 학습과 테스트를 모두 진행하는 경우, 모델의 진짜 성능을 파악할 수 없게 됨
학습되지 않은 데이터가 들어왔을 때, 어떻게 처리할지는 아무도 모르기 때문...
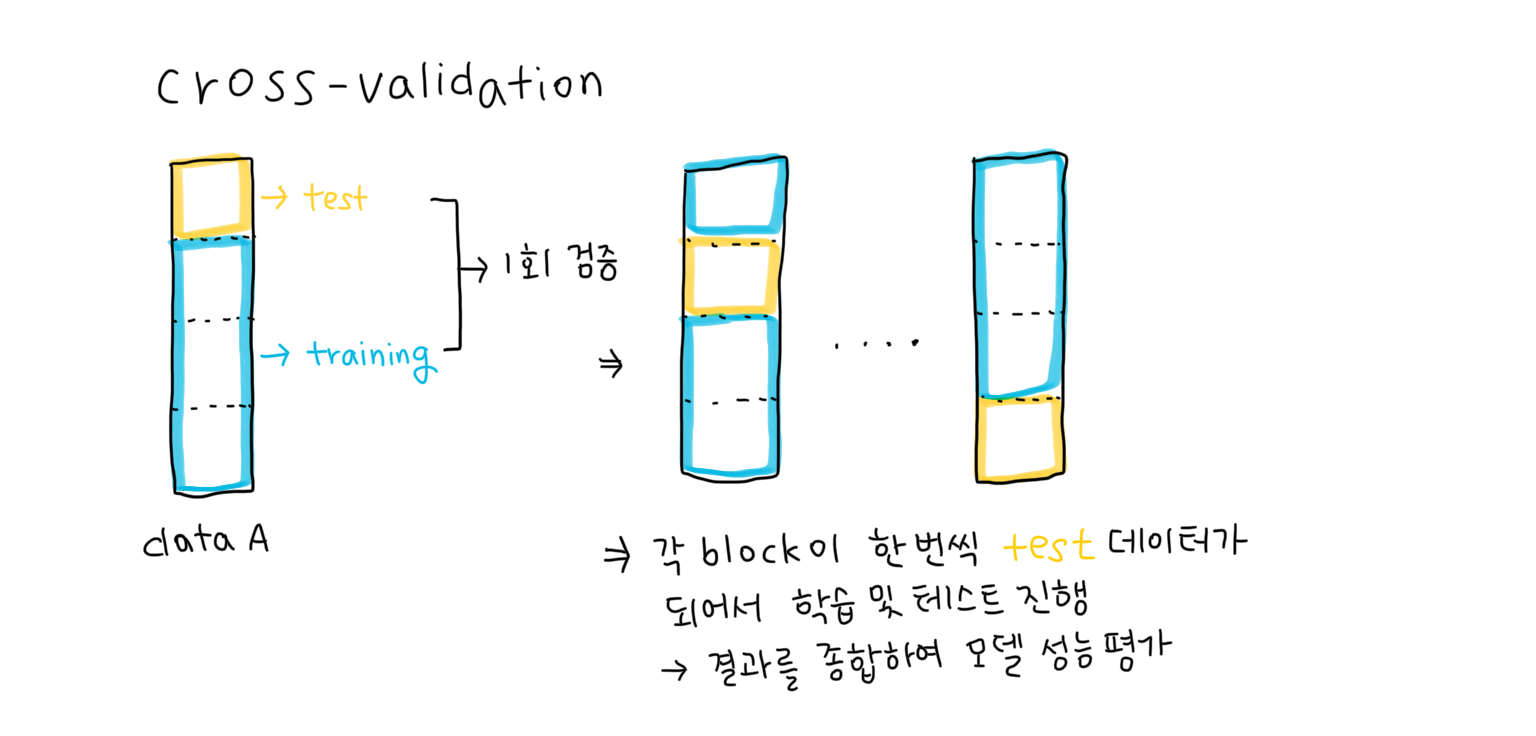
Cross-Validation
이런 문제를 방지하기 위한 것이 바로 Cross-Validation
데이터를 여러 개의 block으로 나눠, 하나의 블록을 test data로 두고, 나머지 블록들은 train data로 가정한 후, 각 결과를 종합(보통 평균)하여 모델의 성능을 분석하는 방법
-> 특히 data의 수가 한정되어있을 때, 유용하게 사용됨
❗️block의 개수는 임의로 선정 가능 (k개의 block으로 나누면 'k-Fold Cross-Validation')
-> 각각의 row cell을 block으로 가정하는 "Leave One Out Cross-Validation"도 존재함
❗️hyperparameter tuning을 위한 Cross-Validation -> 주로 10-Fold Cross-Validation 사용
👀 production 과정에서는 대부분 k = 10 ~ 15 정도로 선택 (15보다 k 값을 높이는 것은 computation expense를 증가시킴)
❗️ 시계열 데이터는 CV 불가능!
시계열 데이터는 시간의 순서가 중요 -> 과거의 것이 그 이후의 것에 영향을 미치기 때문 (conditional probability: 조건부확률)
=> 현재, 미래의 것을 학습하고, 과거의 것을 예측하는 것 자체가 말이 안되는 일!
Cross-Validation - Model Selection
CV의 본질적인 목적: 과적합 방지 및 객관적인 모델 비교 가능하게 하는 것
한 모델 안에서 CV를 통해 다양한 시나리오를 학습 + hyperparameter tuning을 진행하여 과적합을 방지, 최적화하는 방향으로 나아간 후 그 성능을 확인 -> 성능값을 다른 모델들과 비교(모두 CV 진행한 모델들)
model complexity에 영향을 미치는 것: 피쳐수(방의 개수), 하이퍼파라미터, 차원수(방의개수^n: 피쳐의 차수를 늘리는 것!)
predictive error; y - y hat
최적화
어떠한 데이터에도 편향되지 않으면서, 모델이 최고의 성능을 낼 수 있도록 하는 과정 = global minima에 도착한 것!
BUT, 최적화 도달하기 어려움 (local minima에 빠짐)
-> learning rate(학습하는 속도; 너무 낮으면 local minima에 빠지고, 너무 높으면 튕겨져나감), seed(모델의 시작점) 조절을 통해 global minima를 찾으려고 노력
Food for Thought
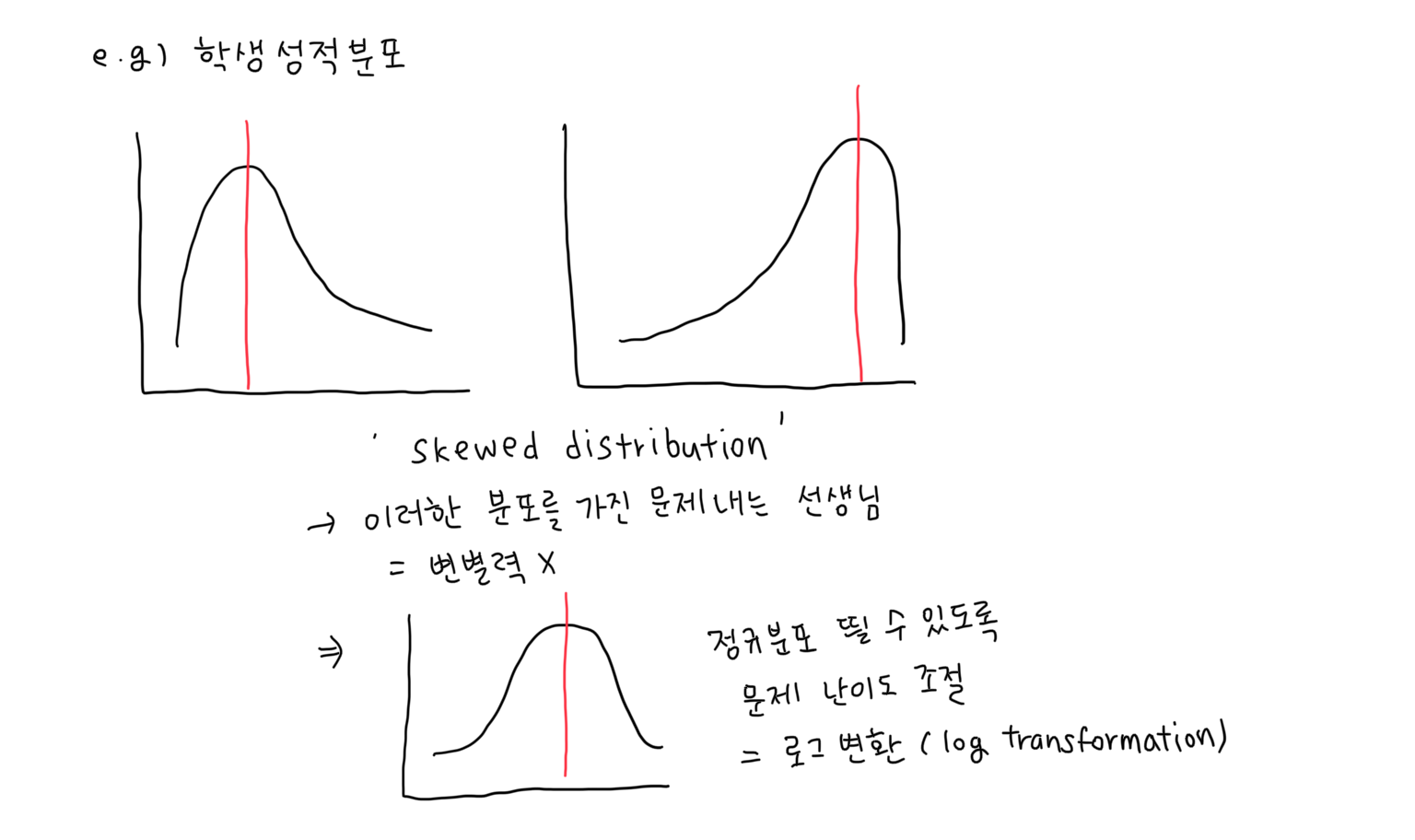
정규분포가 중요한 이유
모델은 데이터의 분포를 파악하는 능력이 없음 -> 분석가가 데이터의 분포를 파악한 후, 모델이 이 분포를 잘 이해할 수 있도록 정규분포로 만들어줘야 함
e.g. 학생 성적 분포 비교 (log transformation)
seed - random state 차이
np.random.seed(): parameter로 seed value를 입력하면, 이에 따른 시드 값을 반환한다 = 난수들이 들어있는 주머니를 결정하는 것이라고 보면 이해하기 쉽다
seed 값이 다를 경우 다른 난수를 생성하나, 같은 seed 값을 입력하면 매번 동일한 난수를 반환하여, 분석을 용이하게 한다만약 매번 cell을 실행할 때마다 모두 다른 난수 값이 나온다면 제대로 된 분석이 불가능할 것
random_state: sklearn의 function중 하나로, seed를 지정해주는 것
-> 특히, train, test set을 나눌 때, 자주 사용됨
