데이터: https://github.com/Spico197/Humback/releases/tag/data
소스코드: https://github.com/Spico197/Humback
요약
- 사람이 작성한 text instruction을 LM으로 labeling한 후 LM이 self로 해당 instruction을 평가하여 고품질 instruction을 선택하는 Instruction Backtranslation 방법 제시
- Instruction Backtranslation: seed 모델(소량의 seed data와 web corpus에 대해 finetuned한 LM)은 web document에 대한 instruction prompt를 생성(self-augmentation)한 다음 후보 중에서 high quality examples 선택(self-curation)하여 training examples를 구성하는데 사용
- distillation data에 의존하지 않고도 Alpaca leaderboard의 다른 모든 LLaMa 기반 모델보다 성능이 뛰어난 모델
알고리즘
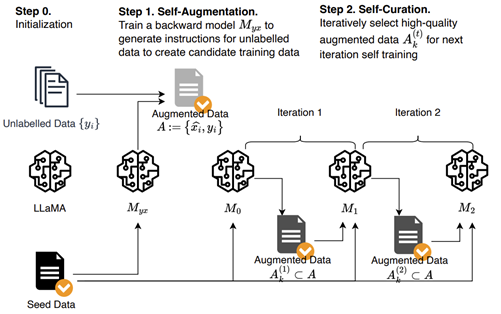
- 소량의 seed(즉, (instruction, output) 쌍)와 unlabelled document 미리 준비
- Self-augmentation
: Myx(instruction prediction model, seed example의 (instruction, output)을 사용하여 파인튜닝한 언어 모델)은 unlabelled dataset에서 output에 대한 후보 instruction 생성 - Self-curation
: seed example로만 학습된 M0(intermediate instruction-following model)에서 시작하여 이전 단계의 후보 중에서 high-quality (instruction, output) A (1) k를 선택하고, 이를 다음 intermediate model, M1의 파인 튜닝 데이터로 사용하여 M2를 얻기 위한 train dataset로 선택
Initialization
- Seed data: LM을 파인 튜닝할 때 사용되는 사람이 주석을 단 (instruction, output)의 seed set로 시작하여 양방향으로 instruction이 주어지면 output을 예측하고 output이 주어지면 instruction을 예측
- Unlabelled data: Unlabelled data (ex: web corpus). 각 document에 대해 전처리를 수행하여 품질이 낮은 세그먼트를 제거
Self-Augmentation (generating instructions)
- Seed data에서 (instruction, output), {(yi , xi)}을 사용하여 base LM을 파인 튜닝하여 backward model, Myx := p(x|y) 생성.
- unlabelled example, yi 에 대해 unlabelled example에서 inference하여 xˆi를 생성후 A := {( ˆxi , yi)}를 도출.
Self-Curation (selecting high-quality examples)
- Self-Augmentation 통해서 생성된 후보 pair의 품질을 5점 척도로 평가하도록 지시하는 프롬프트를 사용하여 수행
- 각 점수별 subset 생성
Iterative self-curation
- 높은 품질의 예측을 생성하기 위해 반복적인 훈련 방법을 제안
- curation된 증강 데이터 A(t-1)k를 seed data와 함께 train data로 개선된 모델 Mt를 파인 튜닝
- 증강된 data의 점수를 다시 매겨 증강 세트 A(t) k를 생성 (본 논문에서는 2번 반복)
- 파인 튜닝을 위해 seed data와 증강 data를 결합할 때는 다른 tagging을 사용하여 이 두 데이터 소스를 구분 (기계 번역의 back translation에서 합성 데이터에 사용되는 방식)
Seed data: 3200 examples from the Open Assistant dataset
Unlabelled data: English portion of the Clueweb corpus, 502k segments
Base model & finetuning: LLaMA (7B, 33B and 65B)
본 논문에서 개발한 모델은 Humpback라고 한다.
Baselines: text-davinci-003, LIMA, Guanaco
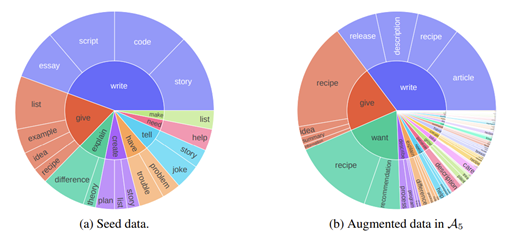
- 자체 큐레이션된 고품질 훈련 데이터(A (2) 4 및 A (2) 5)는 모든 증강 데이터 중에서 명령어와 출력 모두 원래 시드 명령어 데이터의 길이에 가깝게 짧습니다.
- 시드 데이터와 유사하게 글쓰기, 정보 탐색 및 조언과 관련된 몇 가지 헤드 작업이 있지만, 라벨이 없는 데이터의 콘텐츠 유형(기사, 레시피, 설명, 릴리스 등)은 시드 데이터의 콘텐츠 유형(에세이, 대본, 코드, 스토리 등)을 보완
결과
[7B LLaMa를 미세 조정할 때 텍스트-davinci-003에 대한 승률]
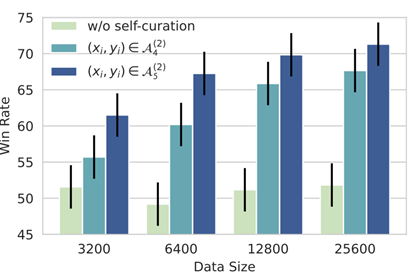
- 훈련 데이터의 품질을 개선하면 데이터 세트의 크기가 작아도 모델의 품질이 크게 향상
- 큐레이션이 없는 증강 데이터에 대한 학습은 데이터 양을 확장하더라도 학습 후 성능이 향상되지 않는다
- 증강 데이터의 고품질 부분에 대한 훈련은 증강 데이터의 양을 계속 확장함에 따라 꾸준한 개선과 함께 학습 추종 성능이 향상
- 고품질 데이터의 양을 늘리면 더 많은 이득을 얻을 수 있는 반면, 저품질 데이터의 양을 늘리면 그렇지 않다
다양한 명령어 추종 모델이 사용하는 미세 조정 데이터에 따른 명령어의 양을 변경하면서 다양한 명령어 추종 모델의 성능을 비교합니다. 주어진 미세 조정 데이터 세트로 7B LLaMa를 미세 조정할 때 텍스트-davinci-003에 대한 각 모델의 승률을 측정합니다. 또한 데이터 스케일링 계수 α를 사용하여 이 효율성의 추정치를 보고하는데, 이 계수는 경험적 데이터를 w = α log N + C로 피팅하여 계산합니다. 여기서 w는 N개의 예제에 대해 미세 조정된 모델의 생성 품질을 측정하는 승률입니다. 명령어 역번역 방법(k = 5, 2회 반복의 자가 증강 및 자가 큐레이션)을 다양한 소스에서 생성된 명령어 데이터 세트를 사용하는 방법과 비교합니다.
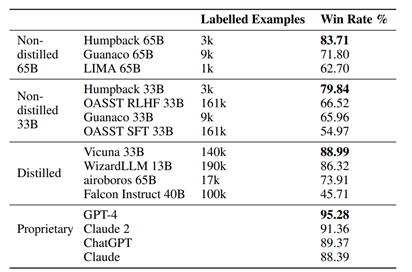
- Non-distilled: 어떤 형태의 감독을 위해 외부 모델(예: ChatGPT, GPT-4 등)에 의존하지 않고 학습된 LLaMa 모델입니다.
- Distilled: 외부 모델에서 추출한 데이터를 사용하는 등 더 강력한 외부 모델을 루프에 사용하여 학습된 모델.
- Proprietary: 독점 데이터 및 기법으로 학습된 모델.
- 본 논문의 제안법을 사용하면 base model 보다 성능이 좋아지지만, gpt4를 능가하지는 못한다. 뿐만 아니라 proprietary 모델 대부분을 이기지 못한다.
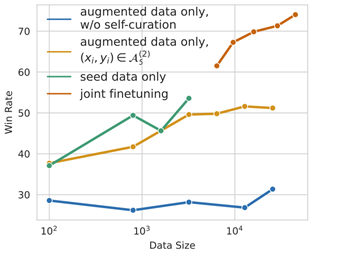
- self-curated data 와 seed data를 결합하면 seed data만 사용하는 것보다 훨씬 뛰어난 성능. self-curation 없이 증강을 사용하면 성능이 저하되어 curation이 중요.

NLP 공부하는 사람