[논문] DOLA: DECODING BY CONTRASTING LAYERS IMPROVES FACTUALITY IN LARGE LANGUAGE MODELS
논문 리뷰
요약
retrieved external knowledge에 대한 조절이나 fine-tuning이 필요 없는 pre-trained LLM의 환각을 줄이기 위해 간단한 decoding 전략을 제안
발견
- LLM의 factual information이 일반적으로 특정 transformer layer에 국한된 것으로 나타남.
- 이를 활용해 vocabulary space에 later layers과 earlier layers을 projecting하여 얻은 logit의 차이를 비교하여 next-token distribution를 얻음.
- Decoding by Contrasting Layers(DoLa)은 factual knowledge을 더 잘 드러내고 incorrect facts의 생성을 줄일 수 있다는 사실 발견
포인트
1. transformer-based LM이 layer를 따라 점진적으로 더 많은 factual information을 통합하는 방식
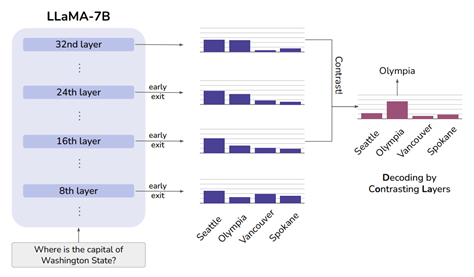
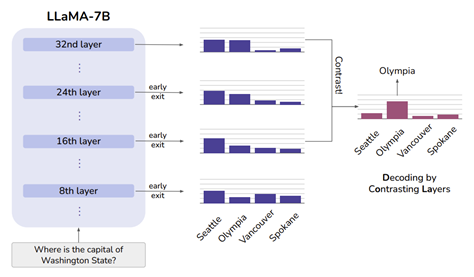
next-word “Seattle”의 확률은 여러 layer에서 비슷하게 유지되는 반면, 정답인 “Olympia”의 확률은 하위 layer에서 상위 layer으로 갈수록 점차 증가. DoLa는 이 사실을 이용하여 두 layer 간의 차이를 대조하여 decoding함으로써 LLM의 factually correct output 대한 확률을 높일 수 있음.
2. dynamic premature later selection 방식 제안
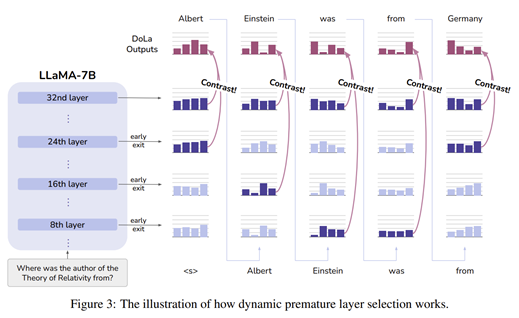
Dora는 그럴듯하지만 사실적이지 않은 정보를 포함하는 early layer을 정확하게 선택해야 하며, 항상 동일한 early layer에 머물러 있지 않을 수도 있다. 즉, later layer과 대조할 early layer를 잘 선정해야 한다는 뜻.
결론
-
dynamic layer selection strategy: 모델은 각 token의 복잡성과 난이도에 따라 가장 적합한 early layer를 선택할 수 있으며, 트랜스포머 모델의 여러 layer에서 학습한 지식을 더 잘 활용 가능.
-
DoLa-static: 유효성 검사 세트를 사용하여 가능한 모든 early layer에 대해 무차별 대입 실험을 실행하여 유효성 검사 성능이 가장 좋은 layer를 선택하여 early layer를 선택
-
단점:
- 1) layer의 검색 공간이 넓어야 하고
- 2) 최적의 layer는 데이터 분포에 민감하므로 분포 내 검증 세트가 필요
-
dynamic layer selection strategy는 layer search space을 축소하고 배포 내 검증 세트에 크게 의존하지 않으면서도 방법을 더욱 강력하게 만들어 static layer-selection의 단점을 완화시킴
