문제 정의 및 목표
- 문제: LLM(대형 언어 모델)이 학생의 수학 문제 풀이에서 오류를 단계별로 식별하고 수정 가능한 피드백을 제공하는 데 한계가 있음.
- 목표:
- 풀이 과정의 각 단계를 검증해 오류를 명확히 식별.
- 맞춤형 피드백 생성을 통해 학생의 학습 효과 증진.
제안된 방법론
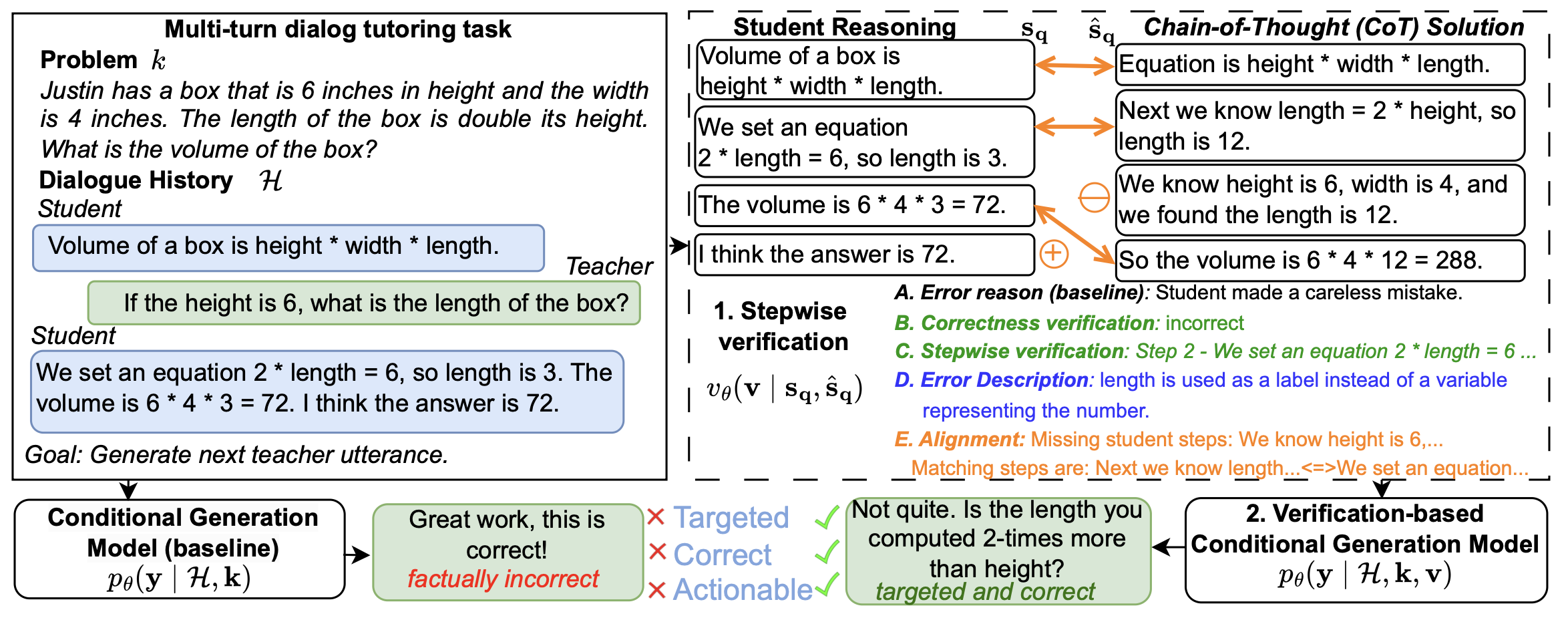
- 검증 시스템 설계
- 분류 기반 검증:
- 전체 풀이와 각 단계별 오류를 이진/다중 클래스 분류기로 분석.
- Overall Verification: 학생의 풀이 sq 전체가 맞는지 틀린지를 이진 분류기로 판단.
- Stepwise Verification: 풀이 각 단계 sn을 분석해 처음으로 오류가 발생한 단계를 다중 클래스 분류로 식별.
- 0: 오류 없음, n: 단계 sn에서 오류 발생.
- Stepwise Verification (Iterative): 각 단계 sn이 맞는지 틀린지를 이진 분류기로 개별 확인.
- 처음으로 "오류"로 분류된 단계를 첫 오류로 간주.
- 오류 설명:
- LLM으로 각 단계의 오류를 자연어로 기술.
- 고정된 오류 유형 없이 자유 형식(free-form)으로 설명.
- 오류 위치뿐 아니라 구체적인 오류 내용까지 설명.
- 대형 언어 모델(LLM)을 사용해 오류 단계와 문제를 텍스트 형식으로 기술.
- 프리폼 형식으로 작성되며, 오류 유형에 고정되지 않음.
- 단계 정렬(Step Alignment):
- 학생 풀이와 참조 풀이 간의 단계별 비교를 위해 Needleman-Wunsch(NW) 알고리즘 사용.
- 문장 임베딩 기반 유사도 계산.
- 결과를 "정확히 일치", "유사", "불일치"로 분류.
- 누락된 단계, 추가된 단계도 검출.
- 학생 풀이 sq와 참조 풀이 bsq를 단계별로 정렬해 비교.
- 오류를 찾기 위해 두 풀이의 각 단계를 맞추는 순서 정렬 문제로 변환.
- 예: 학생 풀이에서 누락된 단계(-)나 추가된 단계(+)를 식별.
- Needleman-Wunsch(NW) 알고리즘 사용:
- *의미 기반 시퀀스 정렬(semantic sequence alignment)**을 위해 문장 임베딩(예: cosine similarity) 활용.
- 유사도 점수에 따라 단계가 "정확히 일치", "유사", 또는 "불일치(누락/추가)"로 구분.
- 결과적으로 매칭된 단계, 누락된 단계, 추가된 단계를 그룹화하여 검증 결과를 생성.
- 학생 풀이와 참조 풀이 간의 단계별 비교를 위해 Needleman-Wunsch(NW) 알고리즘 사용.
- 분류 기반 검증:
- 튜터 응답 생성
- 2단계 접근법:
- 검증 단계:
- 학생 풀이 sq와 참조 풀이 bsq를 비교하여 검증 v를 생성.
- 검증 결과 v는 학생 풀이의 정확성과 오류를 명시적으로 표현.
- 응답 생성 단계:
- 생성 모델이 검증 결과 v, 대화 기록 H, 그리고 배경 지식 k를 기반으로 응답 y를 생성.
- 배경 지식 k에는 학생 풀이 sq, 문제 q, 그리고 참조 풀이 bsq (선택적으로 포함)가 포함됨.
- 검증 단계:
- 복잡성 최소화:
- 응답 생성 과정을 분리하여 환각(hallucination) 문제를 줄임.
- 2단계 접근법:
데이터셋
- 데이터셋 - MathDial:
-
1,000개의 수학 문제 풀이 데이터, 교사가 직접 주석 추가.
-
세분화된 수학적 사고 과정과 다양한 오류 유형 포함.
-
평가 방법
- 평가 지표
- sBLEU: 텍스트 중복 측정.
- BERTScore: 의미적 유사도 평가.
- Knowledge F1 (KF1): 정답 풀이 충실도 평가.
- 모델 평가:
- LLAMA3-70B를 이용한 자동 평가.
- 명확성, 정확성, 실행 가능성 기준으로 인간 평가 보완.
주요 결과
- 검증 성능 개선: 제안된 단계별 검증 시스템으로 LLM 단독 사용 대비 피드백 정확도 상승.
- 맞춤형 피드백 제공: 세분화된 오류 유형 분석과 개인화된 응답 생성.
- 확장 가능성: 제안된 모듈형 접근법은 다른 교과목이나 문제 유형에 응용 가능.
한계 및 향후 과제
- 데이터 제한: 1,000개의 데이터셋으로 일반화 가능성이 낮음.
- LLM 의존성: LLM의 기본 성능에 따라 결과가 좌우됨.
- 실사용 검증 부족: 실제 학습 환경에서의 장기적 효과 분석 필요.

NLP 공부하는 사람