
📌 주제: House Price exploration
📖 참고 솔루션
Comprehensive data exploration with Python(by Pedro Marcelino)
✔️ Understand the problem
⚡ 변수, 데이터셋 살펴보기
✏️ 필요한 라이브러리 불러오기
# 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import StandardScaler
from scipy import stats# warnings 라이브러리로 경고메세지 무시하기
import warnings
warnings.filterwarnings(action='ignore')✏️ 데이터셋 가져오기
# 데이터셋 가져오기
train_data = 'C:\\Users\\USER\\Desktop\\Data Analysis\\data\\train2.csv'
test_data = 'C:\\Users\\USER\\Desktop\\Data Analysis\\data\\test2.csv'
df_train = pd.read_csv(train_data)
df_test = pd.read_csv(test_data)✏️ train set의 컬럼(변수) 확인하기
print(df_train.columns.values)✏️ 데이터 확인하기
df_train.head()✏️ train, test set의 요약정보 확인하기
df_train.info()
print('\n')
df_test.info()🔹 Question
- 이 변수가 집을 구매할 때 필요한가?
- 그렇다면, 이 변수가 얼마나 중요한가?
- 이 변수가 다른 변수에 의해 이미 설명되어 있는가?
- 위와 같은 질문을 통해, 이 문제에서 'OverallQual', 'YearBuilt', 'TotalBsmtSF', 'GrLivArea' 변수가 중요한 역할을 할 수 있다는 결론이 도출됨.
→ 'building'과 관련된 두 개의 변수: OverallQual, YearBuilt
→ 'space'와 관련된 두 개의 변수: TotalBsmtSF, GrLivArea
✔️ analysing 'SalePrice'
✏️ 통계 요약정보 확인하기
df_train['SalePrice'].describe()✏️ 히스토그램 그려보기
sns.distplot(df_train['SalePrice'])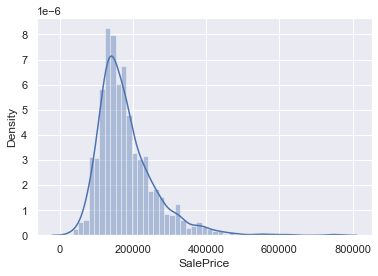
-
Deviate from the normal distribution: 정규분포를 벗어남.
-
Have appreciable positive skewness: 양의 왜도를 가짐.
-
Show peakedness: 뾰족한 모양을 가짐.
⚡ numerical 변수들과의 관계 살펴보기
✏️ scatter plot (GrLibArea, SalePrice)
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1) # axis=1: 열 방향으로 결합
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)) 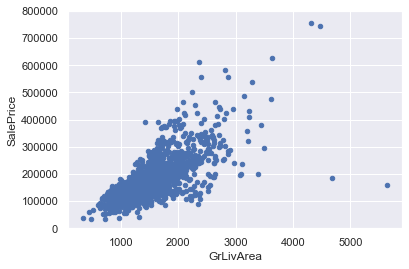
- SalePrice와 GrLivArea 간 양의 선형관계가 존재하는 것으로 보임
✏️ scatter plot (TotalBsmtSF, SalePrice)
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000)) 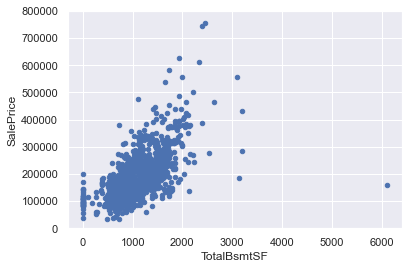
- SalePrice와 TotalBsmtSF 간 양의 선형관계가 존재하는 것으로 보임
- TotalBsmtSF 값이 0인 데이터가 다수 존재함
※ pd.concat: 데이터프레임 결합
pd.concat(df,
axis=0, # axis: 축 방향
keys=None, # 원본데이터 이름 지정
levels=None,
names=None)⚡ categorical 변수들과의 관계 살펴보기
✏️ box plot (OverallQual, SalePrice)
var = 'OverallQual'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ax = plt.subplots(figsize=(8,6))
fig = sns.boxplot(x=var, y='SalePrice', data=data)
fig.axis(ymin=0, ymax=800000)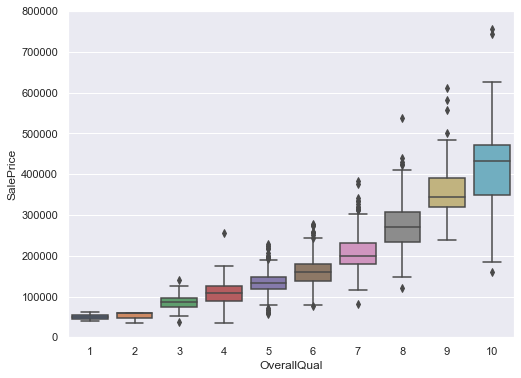
- OverallQual 값이 커질수록 SalePrice의 값도 증가하는 경향을 보임
✏️ box plot (YearBuilt, SalePrice)
var = 'YearBuilt'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ax = plt.subplots(figsize=(16,8))
fig = sns.boxplot(x=var, y='SalePrice', data=data)
fig.axis(ymin=0, ymax=800000)
plt.xticks(rotation=90) # x축 눈금 라벨 회전하기(90도)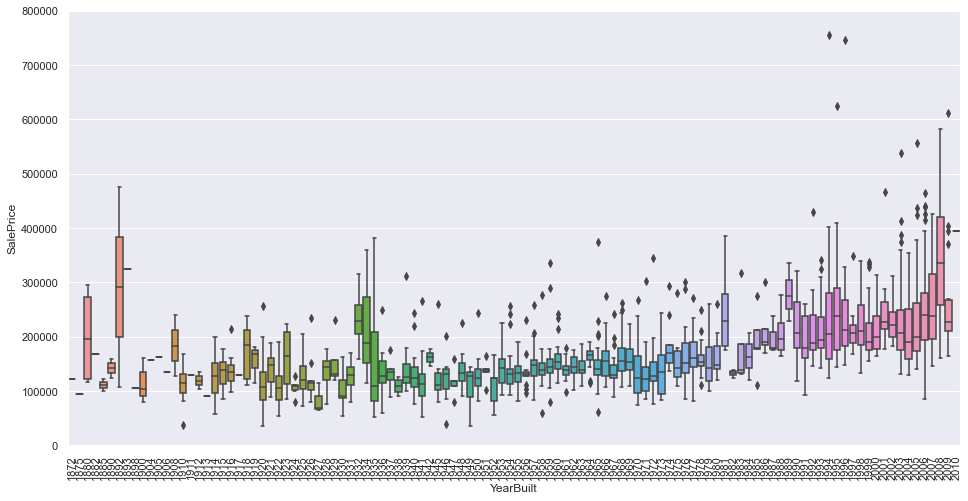
- YearBuilt 값이 커질수록(시간이 지날수록) SalePrice가 증가하는 경향을 보임
✔️ Correlation, Scatter plot
⚡ correlation
✏️ correlation matrix
corrmat = df_train.corr()
f, ax = plt.subplots(figsize=(12,9))
sns.heatmap(corrmat, vmax=.8, square=True)✏️ SalePrice correlation matrix
k = 10 # heatmap의 변수의 개수
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values,xticklabels=cols.values)
# cbar: colorbar의 유무, annot: 각 셀에 값 표기 유무
# fmt: 값의 데이터타입 설정 -> fmt='.2f': 소수점 둘째자리까지
# yticklabels=cols.values: y축에 컬럼명 출력
plt.show()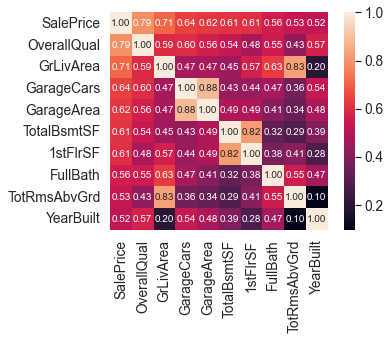
- OverallQual, GrLivArea, TotalBsmtSF → SalePrice와 correlation 높음
- GarageCars, GarageArea → SalePrice와의 correlation이 각각 0.64, 0.62임
- TotalBsmtSF, 1stFloor → SalePrice와의 correlation이 0.61로 같음
- YearBuilt → SalePrice와 correlation이 존재함
※ heatmap 기본문법 (참고자료)
heatmap(df, # 데이터
vmin=100, # 최소값
vmax=700, # 최대값
cbar=True, # colorbar의 유무
center=400, # 중앙값
linewidths=0.5, # cell 사이에 선을 집어 넣음
annot=True, # 각 cell의 값 표기 유무
fmt="d", # cell에 표시된 값의 데이터 타입
cmap='Blues') # heatmap의 색깔⚡ scatter plot
✏️ correlation matrix
sns.set()
cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
sns.pairplot(df_train[cols], size=2.5) # 변수 간 관계 파악
plt.show()✔️ Data cleaning
⚡ missing data
✏️ missing data의 개수 확인하기
total = df_train.isnull().sum().sort_values(ascending=False)
# isnull의 결과 -> True(1): 누락데이터, False(0): 유효한 데이터
percent = (df_train.isnull().sum()/df_train.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head(20)| Total | Percent | |
|---|---|---|
| PoolQC | 1453 | 0.995205 |
| MiscFeature | 1406 | 0.963014 |
| Alley | 1369 | 0.937671 |
| Fence | 1179 | 0.807534 |
| FireplaceQu | 690 | 0.472603 |
| LotFrontage | 259 | 0.177397 |
| GarageYrBlt | 81 | 0.055479 |
| GarageCond | 81 | 0.055479 |
| GarageType | 81 | 0.055479 |
| … | … | … |
-
PoolQC, MiscFeature, Alley,Fence, FireplaceQu, LotFrontage: 결측치 매우 많고, 집을 구매할 때 중요한 요소는 아닌 것으로 판단됨 → 해당 변수 제거 고려
-
GarageYrBlt, GarageCond, GarageType, GarageFinish, GarageQual: 결측치 개수가 같음. garage와 중요한 변수 중 SalePrice와 가장 correlation이 높은 것은 'GarageCars'이므로, 해당 변수들은 제거함
-
BsmtFinType2, BsmtExposure, BsmtQual, BsmtCond, BsmtFinType1: 위와 같은 논리를 적용하여, 해당 변수들은 제거함
-
MasVnrArea, MasVnrType: 이미 고려대상인 YearBuild, OverallQual과 강한 correlation을 갖고 있으므로, 해당 변수는 제거함
-
Electrical: 결측치 1개 존재하므로, 결측치만 제거함
✏️ dealing with missing data
df_train = df_train.drop((missing_data[missing_data['Total'] > 1]).index,1) # missing data가 1개보다 많으면 drop
df_train = df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index) # Electrical에 존재하는 missing data(1개)를 drop
df_train.isnull().sum().max()⚡ outlier
✏️ 데이터 표준화
# standardizing data
saleprice_scaled = StandardScaler().fit_transform(df_train['SalePrice'][:,np.newaxis])
low_range = saleprice_scaled[saleprice_scaled[:,0].argsort()][:10]
high_range= saleprice_scaled[saleprice_scaled[:,0].argsort()][-10:]
print('outer range (low) of the distribution:')
print(low_range)
print('\nouter range (high) of the distribution:')
print(high_range)-
outlier를 판단하기 위해 데이터를 표준화함
✏️ scatter plot (GrLibArea, SalePrice)

-
그래프의 오른쪽 아래에 위치한 2개의 점을 outlier로 판단하고 제거함
-
그래프의 오른쪽 위에 위치한 2개의 점은 trend를 따르고 있으므로, 제거하지 않음
✏️ Deleting points
df_train.sort_values(by='GrLivArea', ascending=False)[:2]
# GrLivArea를 내림차순으로 정렬하고, 그중 가장 큰 GrLivArea 값을 갖는 2개의 행만 출력
# Id가 1299, 524인 행(outlier) 삭제
df_train = df_train.drop(df_train[df_train['Id'] == 1299].index)
df_train = df_train.drop(df_train[df_train['Id'] == 524].index)-
outlier로 판단되는 점 2개를 제거함
✏️ scatter plot (saleprice, TotalBsmtSF)
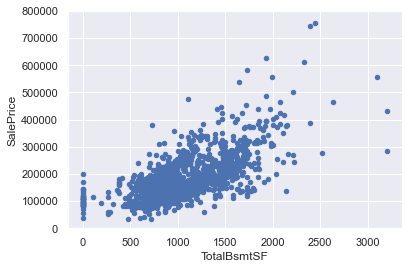
- outlier로 판단할 만한 관측치가 발견되지 않음
⚡ checking assumption
1) Normality
✏️ normality (SalePrice)
# histogram and normal probability plot(Q-Q Plot)
sns.distplot(df_train['SalePrice'], fit=norm)
fig = plt.figure()
res = stats.probplot(df_train['SalePrice'], plot=plt)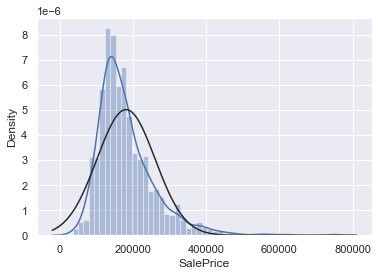
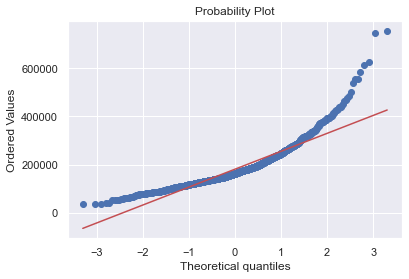
- SalePrice는 normal distribution을 따르지 않는 것으로 판단됨
로그변환
df_train['SalePrice'] = np.log(df_train['SalePrice'])# transformed histogram and normal probability plot
sns.distplot(df_train['SalePrice'], fit=norm)
fig = plt.figure()
res = stats.probplot(df_train['SalePrice'], plot=plt)✏️ normality (GrLivArea)
# histogram and normal probability plot
sns.distplot(df_train['GrLivArea'], fit=norm)
fig = plt.figure()
res = stats.probplot(df_train['GrLivArea'], plot=plt)로그변환
df_train['GrLivArea'] = np.log(df_train['GrLivArea'])# transformed histogram and normal probability plot
sns.distplot(df_train['GrLivArea'], fit=norm)
fig = plt.figure()
res = stats.probplot(df_train['GrLivArea'], plot=plt)✏️ normality (TotalBsmtSF)
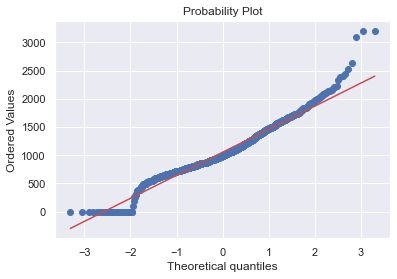
# histogram and normal probability plot
sns.distplot(df_train['TotalBsmtSF'], fit=norm)
fig = plt.figure()
res = stats.probplot(df_train['TotalBsmtSF'], plot=plt)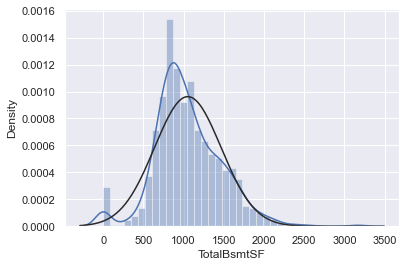
-
다수의 관측치가 0 값을 가짐(basement가 없는 집인 경우) → 로그변환을 할 수 없음
=> basement 존재 여부에 따라 0 또는 1 값을 갖는 변수를 생성하여, 0이 아닌 관측치에 대해서만 로그변환을 실시함
✏️새로운 변수 생성하기
# 새로운 변수 생성 (basement의 존재 여부를 0, 1로 범주화)
df_train['HasBsmt'] = pd.Series(len(df_train['TotalBsmtSF']), index=df_train.index)
df_train['HasBsmt'] = 0
df_train.loc[df_train['TotalBsmtSF'] > 0, 'HasBsmt'] = 1 - TotalBsmtSF의 값이 0보다 크면, HasBsmt에 1값을 줌
# transform data
df_train.loc[df_train['HasBsmt'] == 1, 'TotalBsmtSF'] = np.log(df_train['TotalBsmtSF']) - HasBsmt의 값이 1이면(basement가 존재하면), TotalBsmtSF에 로그변환 실시함
# histogram and normal probability plot
sns.distplot(df_train[df_train['TotalBsmtSF'] > 0]['TotalBsmtSF'], fit=norm)
fig = plt.figure()
res = stats.probplot(df_train[df_train['TotalBsmtSF'] > 0]['TotalBsmtSF'], plot=plt)2) homoscedasticity
✏️ scatter plot (SalePrice, GrLivArea)
plt.scatter(df_train['GrLivArea'], df_train['SalePrice'])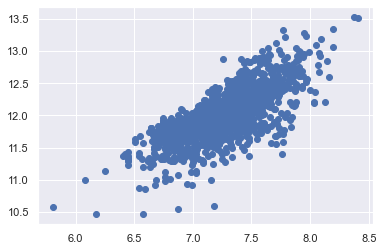
- 등분산성을 만족하는 것으로 보임
✏️ scatter plot (SalePrice, TotalBsmtSF)
plt.scatter(df_train[df_train['TotalBsmtSF'] > 0]['TotalBsmtSF'], df_train[df_train['TotalBsmtSF'] > 0]['SalePrice'])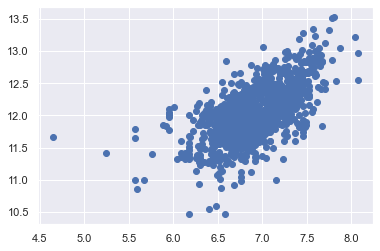
- 등분산성을 만족하는 것으로 보임
⚡ checking assumption
✏️ categorical 변수를 dummy 변수로 변환하기
df_train = pd.get_dummies(df_train)❗️ 참고자료 ❗️
House Prices - Advanced Regression Techniques
Comprehensive data exploration with Python(by Pedro Marcelino)
heatmap 기본 문법
