
📌 주제: titanic 사고로 인한 생존 여부 예측
📖 참고 솔루션: Titanic Data Science Solutions(by MANAV SEHGAL)
📖 순서
1. 문제 정의
2. 훈련, 시험 데이터 준비
3. 데이터 전처리
4. 데이터 분석
5. 모델링 및 예측
❗️ 위 순서는 조금씩 바뀌거나 서로 결합될 수 있음 ❗️
✔️ 문제 정의
-1912년 4월 15일, 타이타닉 호가 빙산과 충돌하여 침몰함
-당시 전체 2,224명의 승객 중 1,502명이 사망함 (생존율: 32%)
-특정 집단(여성, 어린이 등)이 다른 집단에 비해 비교적 생존율이 높았음
- 목표: 타이타닉 호 승객 정보를 이용해, 타이타닉 사고로 인한 생존 여부를 예측함
✔️ 훈련, 시험 데이터 준비
⚡ 필요한 라이브러리 불러오기
# 데이터 분석 라이브러리 불러오기
import pandas as pd
import numpy as np
import random as rnd
# 시각화 라이브러리 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# 머신러닝 라이브러리 불러오기
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier# warnings 라이브러리로 경고메세지 무시하기
import warnings
warnings.filterwarnings(action='ignore')⚡ 데이터셋 가져오기
- 훈련 데이터: 타이타닉 승객의 정보와 생존 여부(0, 1)
- 시험 데이터: 승객 정보만 포함됨
# 데이터셋 가져오기
train_data = 'C:\\Users\\USER\\Desktop\\Data Analysis\\data\\train.csv'
test_data = 'C:\\Users\\USER\\Desktop\\Data Analysis\\data\\test.csv'
train_df = pd.read_csv(train_data)
test_df = pd.read_csv(test_data)
combine = [train_df, test_df] # train, test data를 전부 포함하는 combine 데이터셋 생성⚡ 변수, 데이터셋 살펴보기
✏️ 변수 살펴보기
# train set의 컬럼(변수) 확인하기
print(train_df.columns.values)['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked']-
Categorical
→ categorical: Survived, Sex, Embarked
→ ordinal: Pclass -
Numerical
→ continous: Age, Fare
→ Discrete: SibSp, Parch
✏️ 데이터셋 살펴보기
# 데이터 확인하기
train_df.head()
print('\n')
train_df.tail()[훈련 데이터]
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs.John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
✔️ 데이터 분석
⚡ 데이터 분석하기
✏️ 데이터 요약정보 확인하기
# train, test set의 요약정보 확인하기
train_df.info()
print('\n')
test_df.info()[훈련 데이터 정보]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB- Age, Cabin, Embarked 컬럼에 missing value가 존재함
[시험 데이터 정보]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB-
Age, Fare, Cabin 컬럼에 missing value가 존재함
✏️ 훈련 데이터에서 numerical 변수의 통계 요약정보 확인하기
train_df.describe()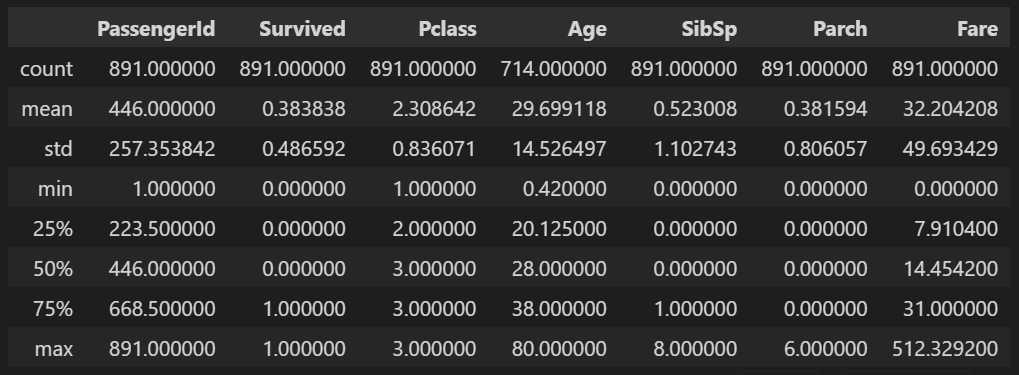
-
훈련 데이터 샘플 수: 891개
-
Survived(생존여부): 0 또는 1 값을 갖는 categorical feature
-
평균 생존율: 약 38%
✏️ 데이터 타입이 Object인 열의 요약정보 확인하기
train_df.describe(include=['O'])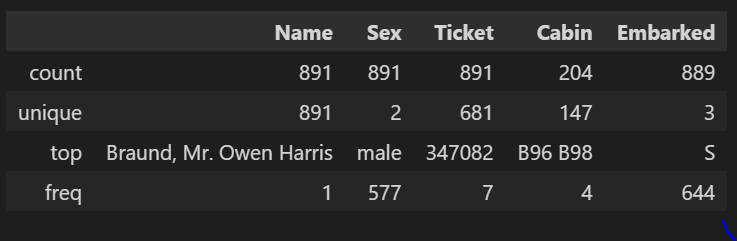
- Name(이름): 중복 없음 (count=unique=891) → 생존여부와 큰 관련 X
- Sex(성별): 891명 중 남성 577명
- Ticket(티켓넘버): 중복값 많음 → 제거 대상 변수
- Cabin(객실번호): 중복값 존재, null 값 많음 → 제거 대상 변수
- Embarked(승선지): 가장 많은 승선지는 S (644명)
⚡ feature, target 변수 분석하기
✏️ Pclass(티켓등급) 별 평균 생존율 비교하기
train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)| Pclass | Survived | |
|---|---|---|
| 0 | 1 | 0.629630 |
| 1 | 2 | 0.472826 |
| 2 | 3 | 0.242363 |
-
객실등급이 좋을수록(Pclass 값이 작을수록) 평균 생존율 높음
✏️ sex(성별) 별 평균 생존율 비교하기
train_df[['Sex', 'Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)| Sex | Survived | |
|---|---|---|
| 0 | female | 0.742038 |
| 1 | male | 0.188908 |
-
남성에 비해 여성일수록 평균 생존율 높음
✏️ SibSp(함께 승선한 형제자매, 배우자 수) 별 평균 생존율 비교하기
train_df[['SibSp', 'Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)| SibSp | Survived | |
|---|---|---|
| 1 | 1 | 0.535885 |
| 2 | 2 | 0.464286 |
| 0 | 0 | 0.345395 |
| 3 | 3 | 0.250000 |
| 4 | 4 | 0.166667 |
| 5 | 5 | 0.000000 |
| 6 | 8 | 0.000000 |
-
경향이 잘 보이지 않음
✏️ Parch(함께 승선한 부모, 자식 수) 별 평균 생존율 비교하기
train_df[['Parch', 'Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)| Parch | Survived | |
|---|---|---|
| 3 | 3 | 0.600000 |
| 1 | 1 | 0.550847 |
| 2 | 2 | 0.500000 |
| 0 | 0 | 0.343658 |
| 5 | 5 | 0.200000 |
| 4 | 4 | 0.000000 |
| 6 | 6 | 0.000000 |
- 경향이 잘 보이지 않음
⚡ 시각화하여 분석하기
✏️ Survived(생존여부) 별 Age(연령)의 분포
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
-
4세 이하 유아의 생존율 높음
-
대다수의 15~25세 승객이 생존하지 못함
-
대부분의 승객이 15~35세임
✏️ Survived, Pclass 별 Age의 분포
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', hue='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()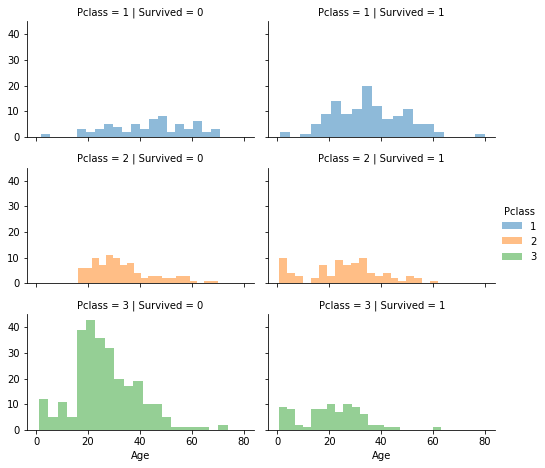
-
Pclass=3인 승객이 가장 많고, 생존율 낮음
-
Pclass=2, Pclass=3인 유아는 대부분 생존함
-
Pclass=1인 승객의 생존율이 비교적 높음
✏️ Embarked, Sex 별 Pclass & Survived의 분포
grid = sns.FacetGrid(train_df, row='Embarked', size=2.2, aspect=1.6)
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
-
남성에 비해 여성의 생존율이 대부분 높음
-
Embarked=C인 경우 남성의 생존율이 더 높은데, 이는 Pclass와 Embarked 간 상관관계가 영향을 준 것일 수 있음
✏️ Embarked, Survived 별 Sex & Fare의 분포
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=0.5, ci=None)
grid.add_legend()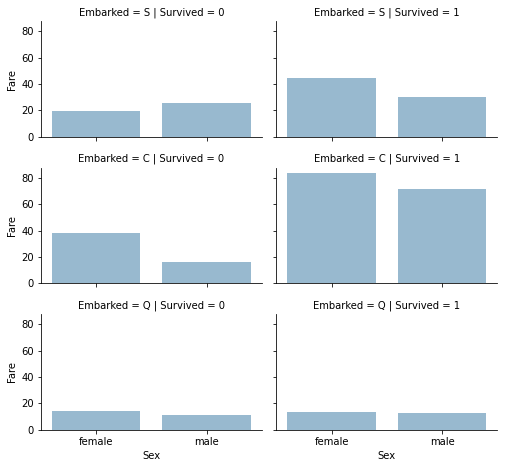
- Embarked=S, C일 때 높은 요금을 지불한 승객의 생존율이 높음
→ Embarked는 생존율과 상관성이 있는 것으로 판단됨
✔️ 데이터 전처리
🔹 변수 제거, 데이터타입 변환하기
✏️ 분석에 필요없는 변수(Ticket, Cabin) 제거하기
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
# 제거 후
print("After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)Before (891, 12) (418, 11) (891, 12) (418, 11)
After (891, 10) (418, 9) (891, 10) (418, 9)✏️ Name 열에서 칭호(Title)만 추출하기
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand = False)
# 교차표 만들기
pd.crosstab(train_df['Title'], train_df['Sex'])-
female일 때 Miss와 Mrs, male일 때 Master와 Mr가 많이 나타남
✏️ 많이 나타나는 Title(4개)를 제외한 나머지는 Rare로 분류하기
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss') # Mlle을 Miss로 변경
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss') # Ms를 Miss로 변경
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs') # Mme를 Mrs로 변경
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()| Title | Survived | |
|---|---|---|
| 0 | Master | 0.575000 |
| 1 | Miss | 0.702703 |
| 2 | Mr | 0.156673 |
| 3 | Mrs | 0.793651 |
| 4 | Rare | 0.347826 |
✏️ categorical title을 ordinal로 변환하기
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()✏️ 분석에 필요없는 변수(Name, PassengerID) 제거하기
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape✏️ Sex 변수를 numeric하게 변환하기
sex_mapping = {"female": 1, "male": 0}
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map(sex_mapping).astype(int) # int로 변환
train_df.head()🔹 Age(연령) 변수 결측값 대체하기
✏️ Age(연령)과 관계가 있는 티켓등급, 성별의 조합별 중앙값으로 대체하기
# Pclass, Sex 별 Age의 분포
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=0.5, bins=20) # histogram
grid.add_legend()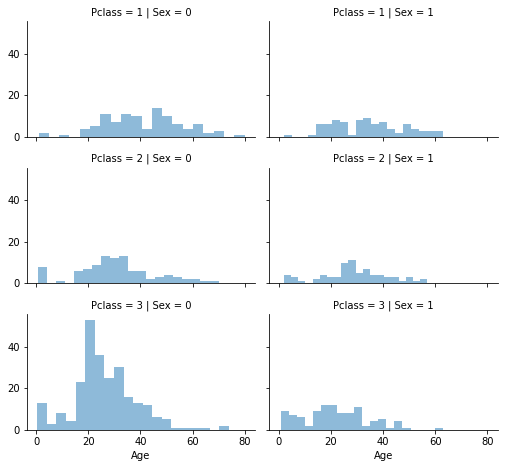
# Pclass, Gender의 조합으로 Age를 추측하기 위한 empty array 생성하기
guess_ages = np.zeros((2,3))
guess_ages# Sex, Pclass의 6가지 조합에 대해 반복하여 Age의 추측값 계산하기 -> 조합별 중앙값 이용
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
# Sex이 i, Pclass가 j+1인 Age를 추출하고, 결측값은 제외
age_guess = guess_df.median() # 중앙값
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int) # int로 변환
train_df.head()✏️ Age를 5개의 구간으로 나누어, 'AgeBand' 컬럼 생성하기
train_df['AgeBand'] = pd.cut(train_df['Age'], 5) # 동일한 길이만큼 5개의 구간으로 나눔
# 연령대별 평균 생존율 구하기
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)| AgeBand | Survived | |
|---|---|---|
| 0 | (-0.08, 16.0] | 0.550000 |
| 1 | (16.0, 32.0] | 0.337374 |
| 2 | (32.0, 48.0] | 0.412037 |
| 3 | (48.0, 64.0] | 0.434783 |
| 4 | (64.0, 80.0] | 0.090909 |
-
16세 이하 승객의 평균 생존율이 가장 높음
✏️ 연령대별로 Age를 ordinal(0,1,2,3,4)하게 변경하기
for dataset in combine:
dataset.loc[dataset['Age'] <= 16, 'Age'] = 0 # Age가 16 이하이면, Age=0으로 변경
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[dataset['Age'] > 64, 'Age'] = 4
train_df.head()✏️ 필요없는 변수(AgeBand) 제거하기
train_df = train_df.drop(['AgeBand'], axis=1)
train_df.head()🔹 새로운 변수(IsAlone) 생성하기
✏️ 기존의 변수(Parch, SibSp)로부터 새로운 변수(FamilySize) 생성하기
train_df["FamilySize"] = train_df["SibSp"] + train_df["Parch"] + 1 # +1은 자기자신을 나타냄
test_df["FamilySize"] = train_df["SibSp"] + train_df["Parch"] + 1
# FamilySize 별 평균 생존율 구하기
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)| FamilySize | Survived | |
|---|---|---|
| 3 | 4 | 0.724138 |
| 2 | 3 | 0.578431 |
| 1 | 2 | 0.552795 |
| 6 | 7 | 0.333333 |
| 0 | 1 | 0.303538 |
| 4 | 5 | 0.200000 |
| 5 | 6 | 0.136364 |
| 7 | 8 | 0.000000 |
| 8 | 11 | 0.000000 |
-
FamilySize는 자기자신을 포함해서 동반한 가족수를 의미함
-
FamilySize=1이면 가족과 동반하지 않았음을 의미함
✏️ 혼자 탑승했는지 아닌지 여부를 나타내는 변수(IsAlone) 생성하기
train_df["IsAlone"] = 0
train_df.loc[train_df['FamilySize'] == 1, 'IsAlone'] = 1
test_df["IsAlone"] = 0
test_df.loc[test_df['FamilySize'] == 1, 'IsAlone'] = 1
# IsAlone 별 평균 생존율 구하기
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()| IsAlone | Survived | |
|---|---|---|
| 0 | 0 | 0.505650 |
| 1 | 1 | 0.303538 |
-
가족과 동반했을 때에 비해 혼자 탑승했을 때 평균 생존율이 높음
✏️ 필요없는 변수(Parch, SibSp, FamilySize) 제거하기
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]🔹 artificial feature 생성하기
✏️ Age * Class 변수 생성하기
train_df['Age*Class'] = train_df.Age * train_df.Pclass
test_df['Age*Class'] = test_df.Age * test_df.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10) # train_df에서 Age*Class, Age, Pclass 열 가져오기🔹 Embarked(승선지) 변수 결측값 대체하기
✏️ 최빈값 구하기
freq_port = train_df.Embarked.dropna().mode()[0] # 방법1
freq_port2 = train_df['Embarked'].value_counts(dropna=True).idxmax() # 방법2
# dropna=True: 유효한 데이터 개수 세기 (dropna=False이면 NaN도 포함하여 개수 세기)
# idxmax(): 'Embarked' 열에서 최빈값 찾기
print(freq_port)
print('\n')
print(freq_port2)✏️ Embarked 열의 missing value을 최빈값으로 대체하기
train_df['Embarked'] = train_df['Embarked'].fillna(freq_port)
test_df['Embarked'] = test_df['Embarked'].fillna(freq_port)
# Embarked 별 평균 생존율 구하기
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)| Embarked | Survived | |
|---|---|---|
| 0 | C | 0.553571 |
| 1 | Q | 0.389610 |
| 2 | S | 0.339009 |
-
Embarked=C일 때 평균 생존율이 가장 높음
✏️ Embarked 변수를 numeric하게 변환하기
Embarked_mapping = {"S": 0, "C": 1, "Q": 2}
train_df['Embarked'] = train_df['Embarked'].map(Embarked_mapping).astype(int)
test_df['Embarked'] = test_df['Embarked'].map(Embarked_mapping).astype(int)🔹 시험 데이터에서 Fare(요금) 변수 결측값 대체하기
✏️ Fare 변수의 missing value를 중앙값으로 대체하기
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True) # inplace = True: 원본 객체를 변경
test_df.head()
test_df.info()✏️ Fare을 4개의 구간으로 나누어, 'FareBand' 컬럼 생성하기
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4) # 동일한 개수만큼 4개의 구간으로 나눔
# train set에서 요금대별 평균 생존율 구하기
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)| FareBand | Survived | |
|---|---|---|
| 0 | (-0.001, 7.91] | 0.197309 |
| 1 | (7.91, 14.454] | 0.303571 |
| 2 | (14.454, 31.0] | 0.454955 |
| 3 | (31.0, 512.329] | 0.581081 |
✏️ 요금대별로 Fare를 ordinal(0,1,2,3)하게 변경하기
for dataset in combine:
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
# 필요없는 변수(FareBand) 제거하기
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]✔️ 모델링 및 예측
⚡ 학습 및 예측을 위한 데이터 준비하기
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy() # copy(): 얕은 복사(shallow copy)
X_train.shape, Y_train.shape, X_test.shape- 이 문제는 새로운 데이터가 들어왔을 때 Survived(생존여부) 값을 예측하는 것이 목적이므로, 지도학습에 해당함.
- 또한 Survived(생존여부, target 변수)와 feature 변수들 사이의 관계를 파악하고자 함.
1) Logistic Regression(로지스틱 회귀)
logreg = LogisticRegression()
logreg.fit(X_train, Y_train) # train data를 이용해서 모형 학습
Y_pred = logreg.predict(X_test) # 예측
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
acc_log81.37
✏️ 각 feature 별 회귀계수를 계산하여, 각 요인이 결과에 어떤 영향을 주는지 확인하기
coef_df = pd.DataFrame(train_df.columns.delete(0)) # train set에서 'Survived' 컬럼 삭제
coef_df.columns = ['Feature'] # column의 이름을 'Feature'로 지정
coef_df['Correlation'] = pd.Series(logreg.coef_[0])
coef_df.sort_values(by='Correlation', ascending=False)| Feature | Correlation | |
|---|---|---|
| 1 | Sex | 2.201057 |
| 5 | Title | 0.406027 |
| 4 | Embarked | 0.276628 |
| 6 | IsAlone | 0.185986 |
| 7 | Age*Class | -0.050260 |
| 3 | Fare | -0.071665 |
| 2 | Age | -0.469638 |
| 0 | Pclass | -1.200309 |
-
sex -> 다른 feature들이 고정인 경우, 남성(0)에 비해 여성(1)일 때 y(Survived)=1이 되는 경향성이 증가함.
-
pclass -> 다른 feature들이 고정인 경우, pclass가 높을수록 y(Survived)=1일 확률이 감소함.
2) Support Vector Machines(SVM)
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc =82.83round(svc.score(X_train, Y_train) * 100, 2)
acc_svc82.83
3) KNN
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
acc_knn82.83
4) Gaussian Naive Bayes
NB = GaussianNB()
NB.fit(X_train, Y_train)
Y_pred = NB.predict(X_train)
acc_NB = round(NB.score(X_train, Y_train) * 100, 2)
acc_NB76.88
5) Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
acc_perceptron79.35
6) Linear SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
acc_linear_svc79.46
7) Stochastic Gradient Descent (확률적 경사하강법)
sgd = SGDClassifier()
sgd.fit(X_train, Y_train)
Y_pred = sgd.predict(X_test)
acc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)
acc_sgd79.12
8) Decision Tree (의사결정나무)
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
acc_decision_tree86.64
9) Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest86.64
❗️ 참고자료 ❗️
