1. Instroduction
깊어진 convolution layer network은 image classification 분야에서
뛰어난 성능을 보여주어 Network depth가 중요한 포인트이다.
depth가 깊어지면 vanishing/exploding gradient 문제가 발생한다. 이 문제는 normalized initialization과 intermediate normalization layer을 통해 해결되어 왔다.
두번째로 degradation 문제가 발생한다. 이로인해 정확도가 정체된다.
이 논문에서는 deep residual learning을 이용해 네트워크 depth가 증가할수록 accuracy가 떨어지는 degradation 문제를 다룬다.
x를 입력값
F(x)를 입력값이 통과해 다음으로 전달되기 위한 함수
H(x)를 출력
이라고 할때
기존의 네트워크는 함수 H(x)를 얻는 것이 목적이다.
residual learning의 경우 H(x)-x ( 출력과 입력의 차 ) 를 얻는 것이 목표이다.
F(x)=H(x)-x 를 최소화 시켜야 하므로 F(x)=0일때 , H(x)=x가 목표가 된다.
ImageNet을 통한 실험을 통해 두가지를 보일 것이다.
1) deep residual nets이 최적화하기 쉽고 에러가 적다.
2) deep residual nets은 depth가 깊어짐에 따라 더 큰 정확도를 얻는다.
CIFAR-10 데이터셋에도 같은 증명을 보인다.
100layer 과 1000layer을 가지고 모델의 실험을 진행한다.
ImageNet에 대해서 현재 가장 깊은 152 layer residual net을 통해 좋은 결과가 나왔다. 게다가 VGGnet 보다 complexity는 작다.
2. Related Work
벡터의 양자화를 위하여 residual vector의 인코딩이 original보다 더 효과적이다.
이 논문에서의 shortcut connection은 계속하여 residual function을 학습하고, 닫히지 않으며 모든 정보가 통과 가능하다.
이전에 사용되던 Residual과 shortcut connection들과 Resnet에서의 장점을 비교
3. Deep Residual Learning
3.1 Residual Learning
F(x)=H(x)-x 를
H(x)=F(x)+x 라고 생각하면 더 학습이 쉬워진다.
3.2 Identity Mapping by Shortcuts
Equation1.
F+x 가 shortcut connection을 의미한다.
Equation2.
F와 x의 차원이 다를경우 맞추기 위해 W_s를 곱한다.
3.3 Network Architectures
두가지 모델 plain/residual 을 통해 설명한다.
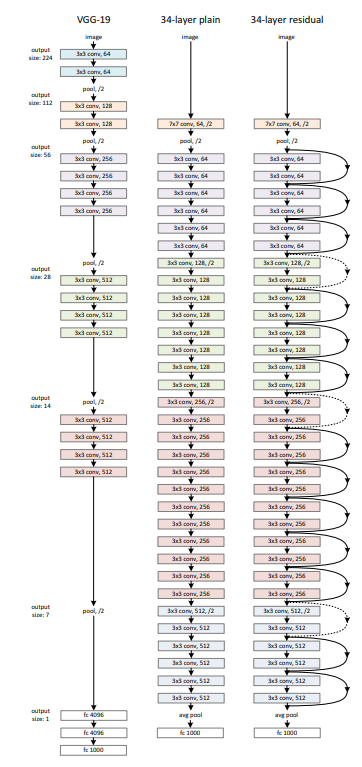
Plain Network
VGGnet을 기본으로 하며 convolution layer은 3x3의 필터를 가지고 두가지의 design rule을 따른다.
(1) 동일한 크기의 feature map 사이즈를 위해 각 layer은 같은 수의 filter을 가진다.
(2) feature map 의 사이즈가 반으로 줄면 필터의 수는 두배가 된다. 이것은 complexity를 유지하기 위함이다.
우리의 모델은 VGGnet에 비해 더 적은 필터와 더 적은 complexity를 가진다.
Residual Network
plain network을 기본으로 하여 shortut connection을 추가하였다.
-input/output dimension이 같으면 => identity shortcut
-dimention이 증가하면 => (A) zero padding을 이용한 identity shortcut
(B) 차원을 맞추기 위해 Eqn2를 이용한다.
VGGnet, Plainnet, Residualnet 을 비교하고 있다
PlainNet은 VGG를 기본으로 했지만 더 적은 필터수, complexity
ResidualNet 은 Plain에 shortcut을 추가
3.4 Implementation
이미지는 짧은쪽의 길이로 resized 시킨다.
이미지에서 랜덤하게 크롭을 진행한다.
각 convolution과 activation전에 batch normalization 진행
learning rate는 0.1에서 시작하여 에러가 유지될 때마다 10으로 나눠진다.
training iteration 60x10^4
weight decay는 0.0001
momentum은 0.9
dropout 사용하지 않는다
4. Experiments
4.1 ImageNet Classification
Plain network
18 layer 과 34 layer을 비교 실험 하였다.
34layer가 18layer보다 더 많은 training 에러를 보였다. 그 이유는 degradation 문제가 발생하였기 때문이었다.
실제로는 34layer가 어느정도 accuracy를 달성할수 있었는데, 이것은 deep plain net이 기하급수적으로 작은 convergence rate를 가져서 training error을 줄이는데 영향을 미친 것으로 보인다.
Plain network에서 34layer보다 18layer의 성능이 더 좋았다. degradation문제 발생했기 때문
Residual Network
18 layer와 34 layer의 residual nets를 비교 하였다.
세가지 발견
1. 34 ResNet이 18 ResNet보다 더 error가 적다. 게다가 training error 가 더 적었다. 이를 통해 degradation 문제가 해결된 것을 알 수 있다.
2. palin network과 비교하여 34layer ResNet은 top-1 error 가 3.5% 감소했다. 이를 통해 deep system에서의 residual learning의 효율성이 증명되었다.
3. 18-layer 의 palin/residual은 거의 동등하게 accurate하다. 그러나 ResNEt 의 convergence가 빠르다. 이 경우처럼 network가 충분히 깊지 않으면 SGD solver가 palin network 에게 좋은 솔루션을 준다.
Residual network을 통해 degradation문제가 해결되었고 plain network과 비교하여 더 높은 효율성을 가진다는 것을 알수있다.
Identity vs Projection Shortcuts
Identity shortcut은 training에 도움이 된다.
이번엔 prijection shortcut에 대해 알아본다. 다음 세가지 옵션으로 비교한다.
(A) zero-padding이 차원을 높이기 위해 사용된다. 그리고 모든 shortcut은 parameter free하다.
(B) projection shortcut은 차원을 높이기 위해 사용된다. 그리고 다른 shortcut은 identity 이다.
(C) 모든 shortcut이 projection이다
이 세가지 옵션 모두 plain model보다 더 좋은 정확성을 보인다.
C>B>A순으로 정확성을 보이는 것을 알수있다. 하지만 이들간의 차이가 매우 작아서 projection shortcut이 degradation 문제에서는 중요하지 않다는 것을 알 수 있다. 따라서 논문에서는 C옵션은 메모리를 위해 사용하지 않는다.
Identity shortcut은 bottleneck 구조에서 complecxity를 높이지 않기 때문에 중요하다.
Deeper Bottleneck Architecture
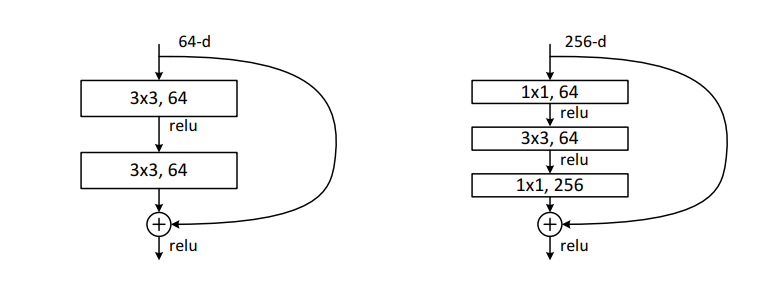
training time 을 위해서 building block을 bottleneck design으로 수정하였다.
1x1 layer이 차원을 줄이고, 높이는 역할을 한다. 이로인해 3x3 layer가 더 작은 차원의 input/output을 가지도록 한다.
parameter-free의 identity shortcut은 bottleneck architecture에서 특히 중요하다. 만약 여기서 identity가 아닌 projection을 쓴다면 time complexity와 모델 사이즈가 두배로 커진다.
오른쪽 그림처럼 training time을 위한 bottleneck구조를 사용한다.
중간 레이어가 더 작은 차원의 input/ouput을 갖도록 한다.
50-layer ResNet
34-layer의 2-layer 블록을 3-layer bottleneck블록으로 대체한다. 이렇게하면 50-layer ResNet 이 된다.
101-layer and 152-layer ResNet
3-layer 블록을 더 사용해서 101-layer와 152-layer ResNet을 만들 수 있다.
depth가 상당히 커졌지만 152-layer의 ResNet은 VGG-16/19보다 complexity가 작다.
50/101/152 layer 의 ResNet은 34-layer ResNet보다 더욱 정확하다. degradation 문제가 발생하지 않았고 따라서 depth가 더욱 깊어질수록 더 큰 정확도를 얻을 수 있었다.
34layer Resnet에 bottleneck 을 추가하여 50/101/152 layer Resnet을 만들었다.
ResNet을 통해 degradation문제를 해결하고, depth가 깊어짐에 따라 더 큰 정확도를 얻는다.
Comparisons with State-of-the-art Methods
'SOTA'는 'State-of-the-art'의 약자로, '현재 최고 수준의 결과'를 가진 모델로, 현재 수준에서 가장 정확도가 높은 모델을 의미한다.
지금까지 single model의 결과들을 살펴보았다. 그 중 34-layer ResNet, 152-layer ResNet 이 높은 정확도를 보였다.
6개의 다른 depth를 가진 모델을 앙상블했다. 이 결과 3.57%의 top-5 error을 보였고 ILSVRC2015 에서 우승했다고 한다.
4.2 CIFAR-10 and Analysis
ImageNet에서와 마찬가지로 ResNet은 optimization 문제를 극복했고, depth가 깊어질수록 accuracy를 획득하였다.
Exploring Over 1000 layers
1000 layer 모델에 대한 실험을 진행하였다.
하지만 이렇게 깊은 모델은 110-layer network 보다 더 좋지 못했다. 이것은 overfitting 이 원인이라고 볼수 있다. 1202 layer 은 이 작은 데이터셋에는 불필요하게 크다.
CIFAR10에 대해서도 depth가 깊어질수록 높은 accuracy를 획득했다.
1000layer 이상의 모델에 대해서는 overfitting 현상이 일어나 성능이 낮아졌다.
4.3 Object Detection on PASCAL and MS COCO
deep residual net을 통해 ILSVRC & COCO 2015 대회에서 우승을 차지하였다.
