1. Instroduction
모델 정확성의 향상은 cost의 증가로 이어진다.
이 논문에서는 mobile 환경, 자원이 제한된 환경을 위한 architecture을 소개한다.
accuracy는 유지하는 반면 연산의 횟수, 필요한 메모리를 줄인다.
novel layer model : inverted residual bottleneck
이 모듈은 최근 프레임워크들의 standard operatoins을 사용하고 우리의 모델이
게다가 이 convolutional 모듈은 mobile환경에 적합하다. 그 이유는 메모리의 사용을 줄이기 때문이다.
2. Related Work
최근에는 accuracy 와 performance 사이에 균형을 위한 활발한 연구가 이루어지고 있다.
그동안 manual architecture search와 트레이닝 알고리즘의 발전은 AlexNet, VGGNet, GoogLeNet, ResNet 으로 이어져왔다.
최근에는 network pruning, connectivity learning 뿐만 아니라 parameter 최적화같은 많은 진전이 있다.
SuffeNet과 같이 내부 convolutional blocks을 바꾸는 경우들도 있었다.
최근에는 genetic 알고리즘이나 강화학습 같은 최적화 방법의 새로운 방향성도 제시되었지만 단점은 network 가 매우 복잡해진다는 것이다.
이 논문에서는 어떻게 신경망이 연산하는지에 관한 직관의 발전을 추구하고 그것을 가능한한 단순한 디자인을 위해 사용한다.
우리의 network는 MobileNetV1을 기초로 한다.
simplicity는 유지하고 정확성은 향상시킨 반면 특별한 연산을 필요로 하지 않는다. 그리고 이미지 분류와 mobile application을 위한 detection을 달성한다.
accuracy와 performance 사이에 균형을 위한 연구는 그동안 진행되어왔다.
이 논문에서는 simplicity는 유지하고, accuracy는 향상시키는 방법을 제시한다.
3. Preliminaries, discussion and intuition
3.1 Depthwise Separale Convolutions
Depthwise Separable Convolutions은 많은 효과적인 신경망 architecture을 위한 핵심 블록이고 우리는 그것을 사용한다.
기초 idea는 전체의 합성곱 layer을 factorized version( 두개의 분리된 레이어로 나누는 ) 으로 대체하는 것이다.
첫번째 레이어는 depthwise convolution이다. 이것은 input채널마다 하나의 convolution 필터를 적용함으로써 필터링 경량화를 수행한다.
두번째 레이어는 1x1 convolution으로 pointwise convolution이라고 불린다.input 채널의 linear combination을 computing 함으로써 새로운 features을 쌓는다.
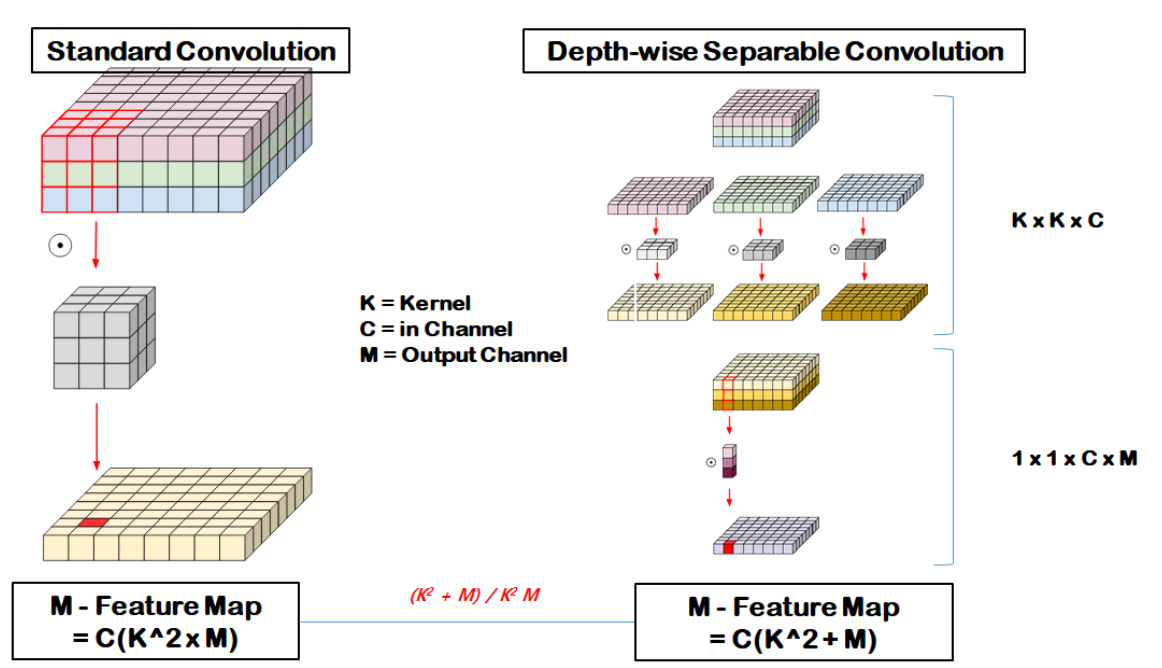
표준 convolution은 다음과 같다.
Depwise convolution은 전통적인 layer와 비교하면 곱셈을 줄인다.
MoibileNetV2는 k=3을 사용하고 computational cost는 8~9이다.
채널별로 분리하여 각 채널을 각각의 커널로 convolution 한다. 하나로 병합되지 않고, (R, G, B)가 각각 Feature Map이 된다.
그 후 pointwise 를 통해 하나로 합친다.
이러한 DSC를 통해 파라미터 수를 줄일 수 있다.
3.2 Linear Bottlenecks
manifold
고차원의 데이터가 저차원으로 압축되면서 특정 정보들이 저차원의 어떤 영역으로 매핑이 되게 되는데, 이것을 manifold라고 한다.
n layer로 이루어진 신경망은 각각 manifold of interest을 형성한다.
manifold of interest은 저차원의 subspace에 embedded될수 있다. 우리가 각 d 채널 픽셀을 볼때, 정보는 manifold에 있다.
layer의 차원을 줄임으로써 연산의 차원을 줄일 수 있다.
이것은 MobileNetV1이 width 파라미터를 통한 계산과 accuracy사이의 균형을 맞추며 개발되었다. 그리고 다른 네트워크 모델에 이용되었다.
width multiplier 접근은 activation space의 차원을 줄이도록 하고 manifold of interest은 이 전체 영역을 확장한다.
그러나 이것은 우리가 Relu같은 비선형을 가진 신경망의 경우엔 실패한다.
즉, deep network는 non-zero volume 에만 선형분류가 가능하다.
반면에 Relu가 채널을 붕괴하면 그 채널의 정보를 잃는다. 하지만 채널의 수가 많다면 정보가 다른 채널에서 여전히 보존될 수 있는 activation manifold 구조가 있다. 만약 input manifold가 activation space의 저차원 subspace에 embedded 되면 Relu 가 정보를 보존한다.
요약하면, manifold of interest는 고차원 activation space의 저차원 subspace에 놓여야 한다.
1. 만약 manifold 가 Relu를 거친 뒤에 non-zero volume 을 남기면 (입력값이 음수가 아니라서 0이 아니라면 ) 이것은 linear transformation과 일치한다고 본다.
2.Relu는 input manifold가 input space의 저차원 subspace에 놓인다면 input manifold에 대해 완전한 정보를 보존하는 것이 가능하다.
이것은 Relu가 양수의 값을 전파하는 linear transformation이기 때문이다.
이 두가지 관점이 우리에게 neural architecture을 최적화하기 위한 실증적인 힌트를 준다 : manifold of interest가 우리가 linear bottleneck을 convolutional block에 집어넣어 capture할수있다.
실험적으로는 linear layer가 non linear이 많은 양의 정보를 파괴하는 것을 막기 때문에 중요하다고 제시한다.
Section6에서 우리는 비선형 layer을 bottleneck에 사용하는 것이 실제로는 성능을 악화시킨다는 것을 알수 있다. 비선형을 제거함으로써 CIFAR 데이터 셋의 성능을 향상시킨 연구도 있다.
고차원에서 저차원으로 매핑하는 bottleneck architecture에서
linear transformation 역할을 하는 linear bottleneck layer을 통해 차원은 줄이되 manifold 상의 중요한 정보들은 그대로 유지한다.
실제 실험 결과 bottleneck layer를 사용하였을 때, 비선형 ReLU를 사용하면 오히려 성능이 떨어진다.
3.3 Inverted residuals
bottleneck block은 residual block과 비슷하다.
하지만 bottleneck이 필요한 모든 정보를 포함한다는 직관에 영감을 받아 우리는 bottleneck사이의 shortcut을 사용한다.
shortcut을 삽입하는 것은 기존의 residual 과 비슷하고 gradient propagate의 능력을 향상시킨다.
하지만 inverted residual이 훨씬 메모리측면에서 효율적이다.
기존의 residual 은 wide-> narrow -> wide 구조
inverted residual 은 narrow -> wide -> narrow
( 중요한 정보는 narrow에 있을 것이라는 생각 )
즉 narrow layer 을 skip connection으로 사용함으로써 메모리 사용을 줄인다.
3.4 Information flow interpretation
이 architecture은 building blocks의 input/output 영역과
layer transformation(input 에서 output으로 변환시키는 비선형 함수 ) 사이의 분리를 제공한다.
전자는 capacity, 후자는 expressiveness으로 볼수 있다.
기존의 convolution block과는 달리 expressiveness와 capacity가 함께 얽히고 출력층 깊이의 함수이다.
특히 inner layer가 0이면 underlying convolution은 identity function이다.
expansion ratio가 1보다 작으면 이것은 classical residual가 된다.
하지만 우리의 목적을 위해 expansion ratio가 1보다 큰 것이 더 효율적이다.
이러한 해석은 capacity와 별개로 expressive을 연구 가능하게 한다.
이 architecture은 convolution block이 capacity와 expressiviness을 분리 가능토록 한다.
4. Model Architecture
기본 building block은 bottleneck depth-separable convolution with residuals 이다.
MobileNetV2의 구조는 초기 fully convolution layer with 32 filters, 19개의 residual bottleneck layers 을 포함한다.
Relu6을 사용한다.
3x3크기의 커널을 사용
dropout, batch-normalization 사용한다.
첫번째 layer을 제외하고는 constant expansion rate을 사용한다.
5~10 사이의 expansion rate 가 최고의 성능을 내며, 더 작은 network에서는 더 작게, 더 큰 network에서는 더 큰 값을 가진다.
input tensor 사이즈에 적용되는 6개의 expansion factor을 가진다.
5. Implementation Notes
5.1 Memory efficient inference
inverted residual bottleneck layer이 특히 좋은 메모리 사용에 도움이 되었다.
6. Experiments
6.1 ImageNet Classification
RMSPropOptimizer ( decay, momentum 0.9 )
각 layer 마다 batch normalization
standard weight decay 0.00004
learning rate 0.045
epoch 0.98
batchsize 96
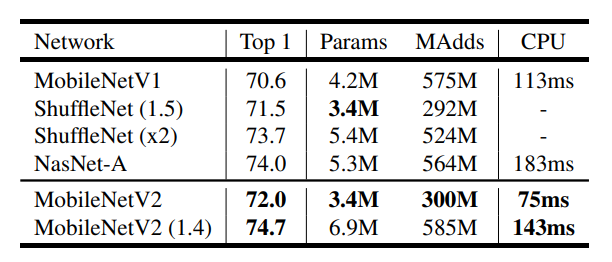
MobileNetV1, SuffleNet, NASNET-1 를 비교한 결과이다.
6.2 Object Detectoin
COCO 데이터셋을 사용해서 MobileNetV2와 MobileNetV1의 성능을 비교하였다.
YOLOv2와 SSD의 비교도 이루어졌다.
SSDLite은 mobile환경을 위한 SSD이다. SSD의 모든convolution layer을 separable convolution으로 대체한다.
SSDLite은 파라미터 수와 계산 cost를 상당히 감소하게 하였다.
MobileNetV2에 대해서 SSDLite의 첫번째 layer은 expansion layer 15에 attach,
두번째와 나머지 layer은 마지막 layer의 top 에 attach
이러한 설정은 모든 layer이 feature map 에 attach되므로 MobileNetV1과 동일하다.
MobileNetV2 SSDLite가 효율적일 뿐만 아니라 정확한 모델이다.
YOLOv2보다 20배 효율적이고 10배 작다.
6.3 Semantic Segmentation
MobilelNEtV1와 MobileNetv2 DeepLabv3을 이용하여 비교한다.
세가지의 디자인 다양성을 두었다.
(1) different feature extractors
(2) 빠른 연산을 위한 DeepLabv3 head의 단순화
(3) 성능 향상을 위한 다른 추론 전략
결과
(a) multi scale input과 adding left-right flipped image는 MAdds를 증가하게 하여 적합하지 않다.
(b) output_stride는 16이 8보다 더 효율적이다
(c) MobileNetV1은 powerful feature extractor이며 ResNet보다 MAdds가 4.9~5.7배 적다.
(d) DeepLabv3의 head를 MobileNetV2의 second last feature map에 build하는 것이 효율적이다.
(e) DeepLabv3의 heads는 계산 비용이 크고 ASPP모듈을 제거하면 약간의 성능 감소로도 MAdds를 줄일 수 있다.
ResNet base 모델에 비해 크게 작고 계산량이 적다.
6.4 Ablation study
shortcut connecting bottleneck이 shortcuts connecting the expanded layer보다 더 낫다.
선형 bottlenexck은 비선형 bottleneck보다 less powerful하다.
하지만 선형 bottleneck이 저차원의 space에서 정보를 파괴하는 것을 방지하기 때문에 더 나은 성능을 보인다.
7. Conclusions and future work
MobileNetV2는 mobile model을 위한 간단한 network architecture이다. basic building unit을 통해 mobile application에 적합하도록 하였다.
ImageNEt 데이터셋에 대해 성능 측면에서 넓은 범위를 가능토록 하였다.
Object detection 에 대해서는, COCO 데이터셋에 대해 accuracy와 model complexity측면에서 좋은 성과를 냈다.
특히 SSDLite detection module과 결합되면 YOLOv2보다 20배 낮은 계산량과 10배 적은 parameter를 가진다.
이론적으로는 convolution block이 capacity와 expressiviness을 분리 가능토록 하였고, 이것이 앞으로의 연구에 중요한 방향이 될 것이다.

좋은 요약 잘 보고 갑니다~