케라스 API의 패션 MNIST 데이터셋을 불러오자.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()그 다음 이미지의 픽셀값을 0~255범위에서 0~1로 변환 후, 28*28 크기의 이미지를 1차원 배열로 평탄화한다. 후에 sklearn의 train_test_split() 메서드를 사용해 train과 validate 세트로 나누자.
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)이제 인공 신경망 모델에 층을 2개 추가하겠다. 이 전의 신경망 모델과 다른 점은 입력층과 출력층 사이에 밀집층이 추가된 것이다. 이렇게 입력층과 출력층 사이에 있는 모든 층을 은닉층(Hidden Layer)이라고 부른다.
은닉층에는 활성화 함수가 항상 적용된다. 출력층에 적용하는 활성화 함수는 이진 분류일 경우에는 시그모이드, 다중 분류일 경우에는 소프트맥스 함수로 제한된다. 하지만 은닉층의 활성화 함수는 출력층에 비해 비교적 자유롭다. 대표적으로 시그모이드 함수와 렐루 함수 등을 사용한다.
다음은 밀집층을 구현하는 코드이다.
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')dense1이 은닉층이며, 100개의 뉴런을 가진 밀집층이다. 활성화함수는 시그모이드이며, 입력의 크기는 (784,)로 지정하였다. 은닉층의 뉴런 개수를 정하는 데는 특별한 기준은 없다. 하지만 적어도 출력층의 뉴런보다는 많아야 한다.
dense2는 출력층이다. 10개의 클래스를 분류하므로 10개의 뉴런을 두었고, 활성화 함수는 소프트맥스로 지정하였다.
이제 앞에서 만든 dense1과 dense2 객체를 Sequential 클래스에 추가하여 심층 신경망(DNN)을 만들어 본다.
model = ([dense1, dense2])여기에서 주의해야 할 것은 출력층(dense2)을 마지막에 두어야 한다.
층을 추가하는 다른 방법이다.
model = keras.Sequential([keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'), keras.layers.Dense(10, activation='softmax', name='output')]
, name='패션 MNIST 모델')dense1, dense2같은 밀집 층은 따로 사용할 일이 없기 때문에 이렇게 직접 Sequential 클래스 안에 전달한다.
또 다른 방법은 다음과 같다.
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'))
model.add(keras.layers.Dense(10, activation='softmax', input_shape=(784,), name='output'))이렇게 Sequential 클래스 객체를 생성 후, add 메서드를 이용하여 층을 추가하는 방법이 있다.
이 방법은 추가되는 방법을 한 눈으로 볼 수 있으며, 프로그램 실행 시 동적으로 층을 선택하여 추가할 수 있기 때문에 유용하다.
이제 모델을 학습시켜보자.
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
#출력
Epoch 1/5
1500/1500 [==============================] - 2s 985us/step - loss: 0.5661 - accuracy: 0.8088
Epoch 2/5
1500/1500 [==============================] - 1s 957us/step - loss: 0.4087 - accuracy: 0.8527
Epoch 3/5
1500/1500 [==============================] - 1s 905us/step - loss: 0.3746 - accuracy: 0.8648
Epoch 4/5
1500/1500 [==============================] - 1s 916us/step - loss: 0.3519 - accuracy: 0.8721
Epoch 5/5
1500/1500 [==============================] - 1s 916us/step - loss: 0.3346 - accuracy: 0.8790
<keras.callbacks.History at 0x7fe0b2e856d0>이 전의 성능에 비해 이렇게 추가된 층이 성능을 향상시켰다는 것을 알 수 있다.
렐루 함수
인공 신경망의 은닉층에 많이 사용된 활성화 함수는 시그모이드 함수였다. 하지만 이 함수에도 단점이 있다.
시그모이드 함수는 입력이 매우 크거나, 매우 작을 때 기울기가 매우 작아질 수 있다. 이 문제는 가중치를 업데이트 하는데 상당한 문제를 일으킬 수 있다.
특히 층이 많은 심층 신경망일수록 그 효과가 누적되어 학습을 더 어렵게 만들 수 있다. 이를 개선하기 위해 나온 함수가 ReLU 함수이다. 렐루 함수는 입력이 양수일 경우 그냥 입력을 통과시키고, 음수일 경우에는 0을 만든다.
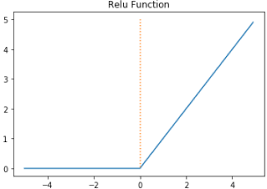
이 함수는 max(0, z)와 같이 쓸 수 있다. z가 0보다 크면 z를 출력하고, z가 0보다 작으면 0을 출력한다.
렐루 함순믄 특히 이미지 처리에서 좋은 성능을 낸다고 알려져 있다.
위에서 우리는 28*28을 reshape() 메서드를 사용하여 1차원 데이터로 평탄화하는 작업을 진행하였다. 하지만 케라스에서 더욱 유용한 기능을 제공한다.
Flatten 클래스는 입력 차원을 모두 일렬로 펼치는 역할을 한다. Flatten 클래스는 입력층과 은닉층 사이에 추가하기 때문에 이를 층이라고 부른다. Flatten 층은 다음 코드처럼 입력층 바로 뒤에 추가한다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))이런 식으로 Flatten 층을 추가하면 된다. 하지만 우리는 위에서 이미 평탄화 작업을 진행하였기 때문에 데이터를 다시 불러온 후 모델 학습을 진행시킨다.
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
#출력
Epoch 1/5
1500/1500 [==============================] - 2s 914us/step - loss: 0.5370 - accuracy: 0.8106
Epoch 2/5
1500/1500 [==============================] - 1s 909us/step - loss: 0.3953 - accuracy: 0.8566
Epoch 3/5
1500/1500 [==============================] - 1s 913us/step - loss: 0.3571 - accuracy: 0.8707
Epoch 4/5
1500/1500 [==============================] - 1s 904us/step - loss: 0.3359 - accuracy: 0.8801
Epoch 5/5
1500/1500 [==============================] - 1s 936us/step - loss: 0.3197 - accuracy: 0.8849
<keras.callbacks.History at 0x7fe0b2f6cf10>model.evaluate(val_scaled, val_target)
#출력
375/375 [==============================] - 0s 688us/step - loss: 0.3731 - accuracy: 0.8787
[0.37310147285461426, 0.8786666393280029]옵티마이저
딥러닝의 학습에서는 최대한 틀리지 않는 방향으로 학습해 나가야 한다.
여기서 얼마나 틀리는지(loss)를 알게 하는 함수가 loss function=손실함수이다. loss function의 최소값을 찾는 것을 학습의 목표로 한다.
여기서 최소값을 찾아가는 것을 최적화=Optimization 이라고 하고 이를 수행하는 알고리즘이 최적화 알고리즘=Optimizer 이다.
즉 최적의 경사 하강법 알고리즘을 선택하는 것이다.
다음은 옵티마이저의 종류이다.
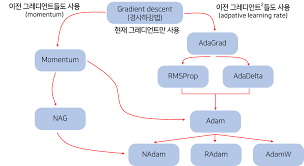
어떤 옵티마이저를 사용해야 할 지 모를 때에는 Adam을 사용하라. 라는 말이 있다. Adam이 가장 일반적이며, 성능이 좋은 옵티마이저다. 다음은 옵티마이저를 adam으로 설정한 후 모델을 학습시키는 코드이다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
#출력값
Epoch 1/5
1500/1500 [==============================] - 1s 871us/step - loss: 0.5328 - accuracy: 0.8143
Epoch 2/5
1500/1500 [==============================] - 1s 932us/step - loss: 0.3991 - accuracy: 0.8581
Epoch 3/5
1500/1500 [==============================] - 1s 957us/step - loss: 0.3553 - accuracy: 0.8712
Epoch 4/5
1500/1500 [==============================] - 1s 901us/step - loss: 0.3258 - accuracy: 0.8807
Epoch 5/5
1500/1500 [==============================] - 1s 953us/step - loss: 0.3075 - accuracy: 0.8859
<keras.callbacks.History at 0x7fe0b2eebf70>model.evaluate(val_scaled, val_target)
#출력값
375/375 [==============================] - 0s 686us/step - loss: 0.3435 - accuracy: 0.8780
[0.34353795647621155, 0.878000020980835]