
네이버 영화별 평점 수집
- 하나의 페이지에서 영화명, 평점 수집 -> DataFrame (영화명, 평점)
- 날짜별로 페이지의 영화명, 평점 수집 -> DataFrame (영화명, 평점, 날짜)
1) 필요 library import
import requests as req
import pandas as pd
from tqdm.notebook import tqdm
from bs4 import BeautifulSoup as bs2) 원하는 페이지의 HTML 로드하기
mv_rate_url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20220727"
header = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}
res = req.get(mv_rate_url, headers = header)
html = bs(res.text, 'lxml')3) CSS선택자로 수집 후 list에 저장하기
# 영화명, 평점 수집한 후 movieNmlist, ratelist에 저장해보기
movies = html.select("div.tit5 > a")
rates = html.select("td.point")
movieNmlist = []
ratelist = []
for i in range(len(movies)):
movieNmlist.append(movies[i].text)
ratelist.append(rates[i].text)4) 저장된 list를 dictionary로 만들어 dictionary를 활용한 DF만들기
movie_dic={
"영화":movieNmlist,
"평점":ratelist
}
ranklist = list(range(1,len(movieNmlist)+1))
movie_df = pd.DataFrame(movie_dic, index=ranklist)
movie_df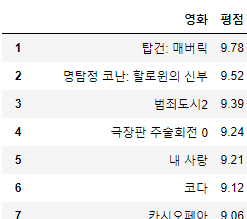
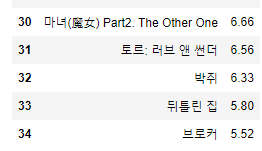
URL을 바꾸면 정보를 쉽게 얻어올 수 있다. 즉, URL을 잘 봐야한다

智(지)! 德(덕)! 體(체)!