
selenium
- 동적인 페이지는 requests로 수집이 불가능하다.
- selenium이라는 library를 사용하면 해결이 된다.
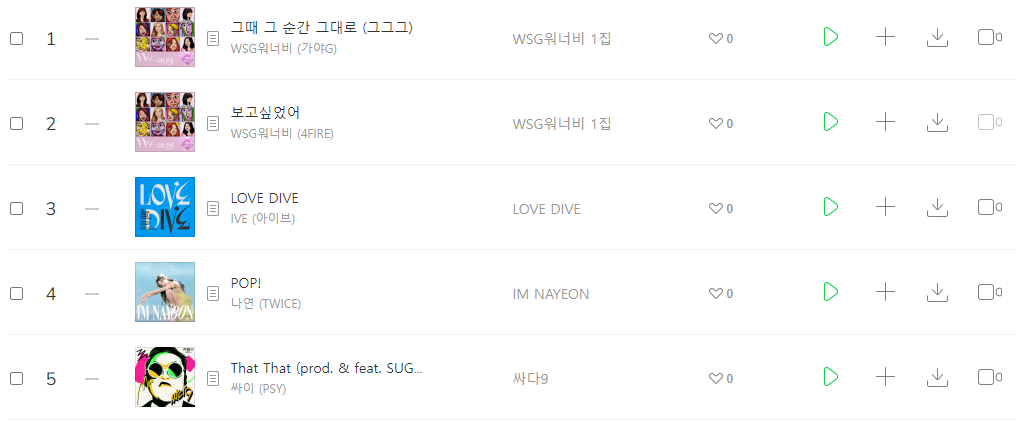
위 사진과 같이 초반에는 좋아요 수가 0이었다가 JS등 스크립트로 인하여 나중에 data 정보가 불러와지는 것은 requests로 수집을 할 수 없다.
selenium이란?
- 원래 기업에서 무언가를 테스트할 때 자동으로 테스트하기 위해 만들어진 것
- dynamic web page의 data를 crawling 할 때 사용하는 library
- web page control(click, keyboard input, scroll, tab(위에 띄워져있는 창) 전환, etc...)가능
1. 환경구축
1) selenium library install 및 import
!pip install selenium- 드라이버 파일을 실행할 때 필요, default 값으로 무조껀 쳐놓고 시작해야함.
from selenium import webdriver as wb- 다양한 방법으로 HTML을 선택할 때 사용하는 라이브러리 By
- find_element()는 id기준으로만 HTML 선택이 가능하기 때문에 By 라이브러리가 필요!
from selenium.webdriver.common.by import By
import pandas as pd2) webdriver.exe download
- google setting에 들어가서 정보에 들어가서 크롬 버전을 확인한다
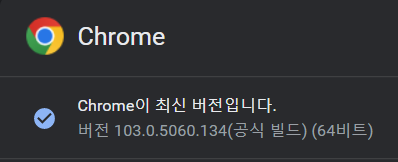 그 후 크롬 드라이버 다운로드에 들어가 해당 버젼에 맞는 것을 다운로드 해주면 된다.
그 후 크롬 드라이버 다운로드에 들어가 해당 버젼에 맞는 것을 다운로드 해주면 된다.
2. Url 가져오기
- driver 객체 생성
- 원래 객체 생성 시
driver = wb.Chrome(경로)이다.
하지만 실행 파일과 드라이버파일이 같을 path에 위치할 경우에는 생략 가능하다.
url="https://www.naver.com/"
driver = wb.Chrome()
# 브라우저 실행
driver.get(url)3. id 속성으로 검색
- find_element() => id 밖에 찾을 수 없음 즉, id가 없다면 찾아올 수 없음.
- 검색방법
1.click으로 찾기
2.enter로 찾기
driver.find_element(by="id", value="query").send_keys("너굴맨")
# 검색버튼 클릭 이때 value에는 CSS 선택자가 아니기 때문에 #은 필요가 없음.
driver.find_element(by="id", value="search_btn").click()
driver.find_element(by="id", value="query").send_keys("너굴맨\n")4. CSS 선택자로 검색
- driver.find_element() -> 하나의 HTML을 반환하는 함수
- BeautifuoSoup의 select_one()과 같은 역할
- driver.find_elements() => 조건에 맞는 모든 HTML을 리스트로 반환하는 함수다.
- BeautifuoSoup의 select()과 같은 역할
driver = wb.Chrome()
driver.get("https://www.google.co.kr/")
driver.find_element(By.CSS_SELECTOR, value="input.gLFyf.gsfi").send_keys("너굴맨\n")- 만약 잘못된 선택자라면 다음과 같은 error가 뜬다.
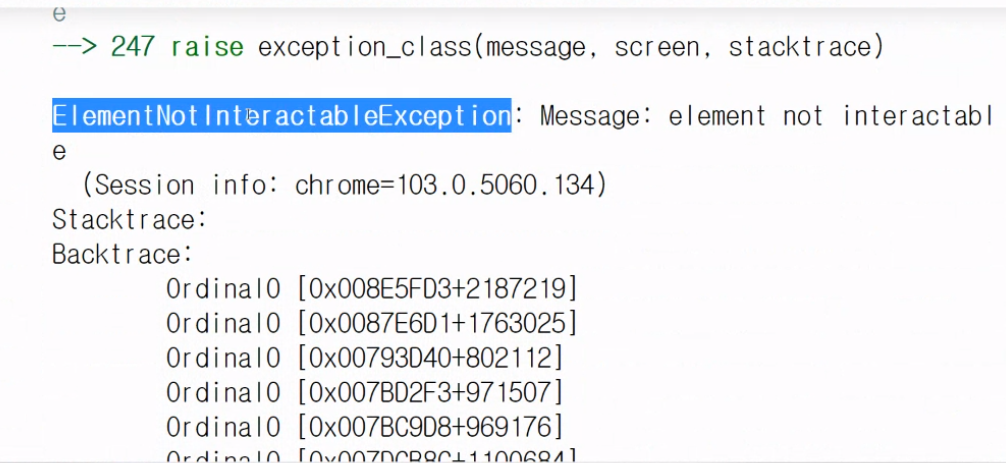
5. 드라이버 종료
-
브라우저 종료(현재 창만 닫힘)
driver.close() -
브라우저 전체 종료
driver.quit()

智(지)! 德(덕)! 體(체)!