
2. DataFrame
1. DataFrame 생성
(1) dictionary를 사용한 DataFrame 생성
data = {"2010":[9631482,3393191,2632035,2431774],
"2015":[9904312,3448737,2890451,2466052]}
df = pd.DataFrame(data)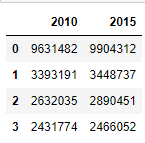
- index를 따로 설정해도 되지만
df = pd.DataFrame(data, index=["서울","부산","인천","대구"])위와같이 한방에 생성해도 무관
(2) dataframe 인덱스 지정하여 생성
- index : 데이터 프레임의 인덱스 설정(행의 이름들)
- columns : 데이터프레임의 컬럼명 설정
listq=[[9631482,3393191,2632035,2431774],
[9904312,3448737,2890451,2466052]]
ind =["2010","2015"]
col =["서울","부산","인천","대구"]
df2 = pd.DataFrame(listq, index=ind, columns = col)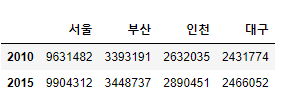
2. DataFrame 수정
(1) dataframe index 수정
df.index=["서울","부산","인천","대구"]
(2) 전치
- 전치 : 행과 열을 변환
- T
- transpose()
df3 = df2.copy()
df3.T
# df3.transpose()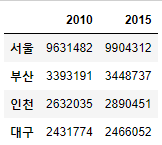
(3) 인덱싱 및 컬럼 순서 바꾸기
- 지정한 순서대로 바뀌어서 나옴 또한 값을 다시 담아주면 영구적으로 바뀜 그렇지 않으면 보여주기만 함.
# [] : 행 데이터, [[]] : 열데이터(컬럼 데이터)
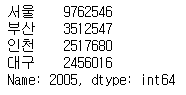
df["2005"] = [9762546,3512547,2517680,2456016]
df = df[["2005","2010","2015"]]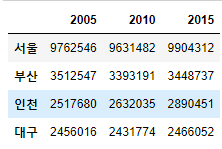
3. DataFrame 값 확인
(1) values
- 값들을 가져온다.
df2.values
# result
array([[9631482, 3393191, 2632035, 2431774],
[9904312, 3448737, 2890451, 2466052]], dtype=int64)(2) index
- 인덱스를 가져온다.
df2.index
# result
Index(['2010', '2015'], dtype='object')(3) columns
- 컬럼들을 가져온다.
df2.columns
# result
Index(['서울', '부산', '인천', '대구'], dtype='object')(4) Series로 출력
print(df4["홍길동"])
df4["홍길동"].shape
# result
키 175.3
몸무게 66.2
나이 27.0
Name: 홍길동, dtype: float64
(3,)(5) DataFrame으로 출력
print(df4[["홍길동"]])
df4[["홍길동"]].shape
# result
홍길동
키 175.3
몸무게 66.2
나이 27.0
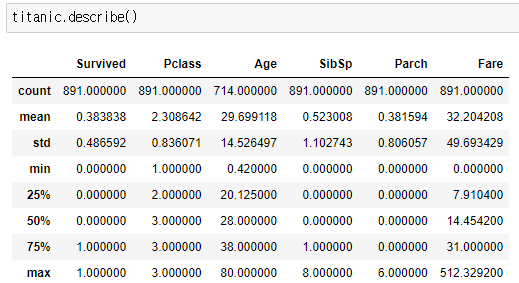
(3, 1)(6) describe()
- describe() : 간단한 기술 통계를 계산하는 함수(data의 개수, 평균, 표준편차, 범위별 데이터 값(최소값, 25,50,75%, 최대값))
- 결측치, 분산(데이터가 얼마나 퍼져있는지 정도), 편향(data가 한쪽으로 치우친 정도),
- 이상치 (outlier - 일반적인 값에서 벗어난 값(예) 1000세)
- 평균 < 표준편차(std) : 분산이 크다는 의미 (data가 흩어져있거나 이상치가 있거나)
- 평균과 50% 위치값이 크게 다르면 : 편향이 되어있을 가능성이 높음
- 최대값이나 최소값이 각각 75%와 25%와의 차이가 크다면 이상치가 있을 수 있다.(단, 실제 데이터를 고려해서 판단)
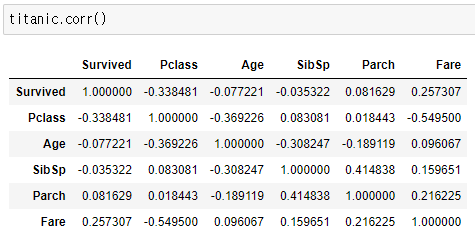
(7) corr()
- corr():상관관계를 계산하는 함수(피어슨 상관계수)
- 얼마나 유사하냐, 얼마나 관련성이 있냐를 판단
- 음의 상관관계 : 반비례
- 양의 상관관계 : 정비례
- 0의 상관관계 : 관계가 없는거 -> 사용안해도 됨
4. DataFrame indexing
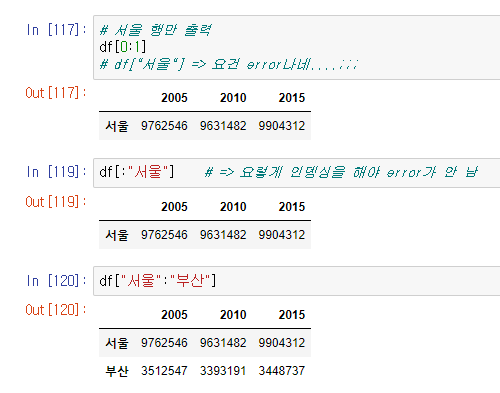
- 근데 위와같이 인덱싱하지 않음
- indexer : DataFrame에서 data를 인덱싱하고 슬라이싱 기능을 제공
- loc[행, 열] : 이름으로 접근
- iloc[행, 열] : index로 접근
(1) loc
- 행만, 열만 따로따로 접근 가능
df.loc["서울"]
df.loc[:,"2005"]
df.loc["서울":"인천", "2010":"2015"]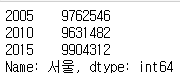

(2) iloc
- iloc[행]
- iloc[행, 열]
- iloc[시작행:끝행+1, 시작열:끝열+1]
df.iloc[0:3,-2:]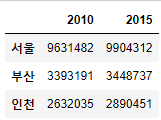
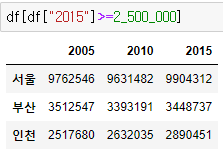
(3) boolean indexing
5. DataFrame read
(1) read_csv(path, index_col, encoding)
- 판다스는 다양한 형태의 데이터파일을 읽고 쓰는 기능을 지원함 csv, xml, pdf, html, json, txt, xls 등
- csv = 데이터를 콤마로 구분한 파일 데이터
path="C:/Users/AI_school/anaconda3/envs/data/titanic.csv"
titanic = pd.read_csv(path, index_col="PassengerId")- index_col = 원래 있는 컬럼 중 원하는 컬럼을 인덱스로 지정하는 함수
- 만약 column이나 data중에 한국어가 있다면
- encoding = "euc-kr"을 추가할 것.
6. DataFrame 함수
(1) head()
- 데이터를 default 5까지 출력하는 것

(2) tail()
- 끝에 data를 출력 default = 5개

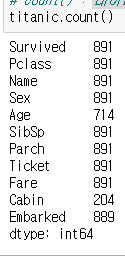
(3) count()
- 데이터 개수를 세는 함수 단, 결측치는 제외함. => 결측치가 있는지 확인이 가능 하지만 info가 더 좋은 함수임.
(4) info()
- info() : data의 정보를 출력하는 함수
- data의 개수, 컬럼명, 데이터 타입등을 출력
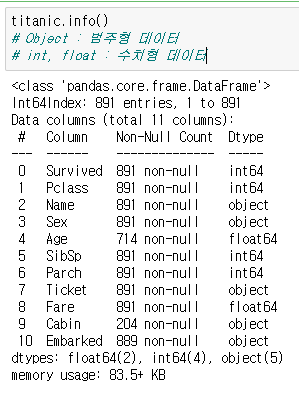
- data의 개수, 컬럼명, 데이터 타입등을 출력
(5) unique()
- unique() : 범주형 데이터의 클래스명을 출력, 중복을 제거하는 기능을 함.
- 클래스 : 범주형 데이터에 포함된 값의 종류
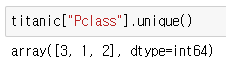
- 클래스 : 범주형 데이터에 포함된 값의 종류
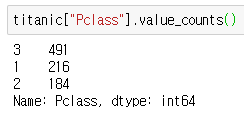
(6) value_counts()
- 범주형 데이터의 클래스의 수를 출력
- value_counts() : 값이 숫자, 문자열, 카테고리 값인 경우에 각각의 값이 나온 횟수를 셀 수 있다.
- 데이터 분석에서 클래스 수는 유사한 것이 제일 좋다.
- 클래스가 한쪽으로 치우친 데이터는 좋지 못하다 => 편향
boolean indexing과 응용
- 성별이 남성 클래스(male)인 승객의 생존자수를 출력
titanic[titanic["Sex"]=="male"]["Survived"].value_counts()
#result
0 468
1 109
Name: Survived, dtype: int64- 탑승항구가 S인 승객의 생존/ 사망자 수를 출력
titanic[titanic["Embarked"]=="S"]["Survived"].value_counts()
#result
0 427
1 217
Name: Survived, dtype: int64- 탐승항구가 S인 승객의 성별수를 출력
titanic[titanic["Embarked"]=="S"]["Sex"].value_counts()
#result
male 441
female 203
Name: Sex, dtype: int64- Embarked 가 Q이고 성별이 여성이 승객의 생존/ 사망자 수
titanic[(titanic["Embarked"]=="Q") & (titanic["Sex"]=="female")]["Survived"].value_counts()
#result
1 27
0 9
Name: Survived, dtype: int64
智(지)! 德(덕)! 體(체)!