
2. DataFrame
6. DataFrame 범용함수
- 파라미터
- axis : 행 기준인지, 열 기준인지 설정(axis = 1 >> 행 기준 즉, 결과값이 오른쪽 끝에 나옴.)
path="C:/Users/AI_school/anaconda3/envs/data/score.csv"
df4=pd.read_csv(path,encoding='cp949',index_col="과목")
df4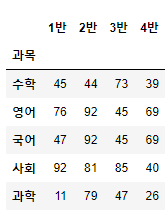
(7) sum()
- 합계를 계산 (기본적으로 열을 기준)
df4["합계"]=df4.sum(axis=1)(8) mean()
- 평균을 계산 boolean indexing과 함게 사용
df4["평균"]=df4.loc[:,:"4반"].mean(axis=1)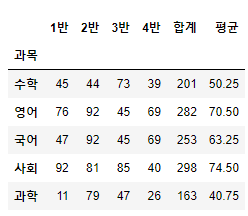
- 새로운 column을 만드려면 loc없이 바로 사용, 반대로 새로운 행을 만들고 싶다면 loc를 이용
df4.loc["반평균"] = df4.mean()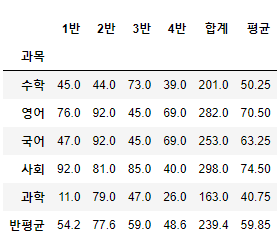
(9) min,max()
- 최소, 최대값을 검색
maxarr = df4.loc[:"과학",:"4반"].max(axis=1)
#result
과목
수학 73.0
영어 92.0
국어 92.0
사회 92.0
과학 79.0
dtype: float64
minarr = df4.loc[:"과학",:"4반"].min(axis=1)
#result
과목
수학 39.0
영어 45.0
국어 45.0
사회 40.0
과학 11.0
dtype: float64(10) cut()
- cut() : 데이터를 여러 구간의 분리하는 함수
- 1차원 data에 사용
- pd.cut(데이터셋, 구간수, 라벨)
- 데이터셋은 1차원 데이터여야한다.
- 구간수와 라벨의 수는 동일해야한다.
- 구간의 범위 : 시작 범위의 수는 포함하고 끝 범위수는 미포함
-[0, 5, 10, 15, 20]- 0-4, 5-9, 10-14, 15-19
- 1-5, 6-10, 11-15, 16-20 (right 파라미터를 False로 설정한 경우)
10-1 예제
- titanic의 Fare data를 10불 이하는 저가, 10-50불은 일반, 50불 이상은 고가, 100불 이상은 초고가로 구간 및 라벨 설정하고 cut()를 이용하여 값을 할당하라.
- 구간을 완전히 똑같이 할당하고 싶다면 qcut()? 을 이용하자
titanic["Fare"].describe()
bins=[0,11,51,101,titanic["Fare"].max()+1]
lb=["저가","일반","고가","초고가"]
titanic["Fare2"] = pd.cut(titanic["Fare"],bins,labels=lb)
titanic["Fare2"].value_counts()


(11) concat()
- concat() : 2개 이상의 데이터프레임을 병합하는 함수
- 행이나 열방향(axis=1)으로 병합
- pd.concat([df1, df2...], axis=)
- axis = 0 2개의 df가 새로로 합쳐짐
- axis = 1 2개의 df가 가로로 합쳐짐
- 비슷한 함수로 merge도 있다더라...
(12) date_range()
- 날짜데이터를 생성해주는 함수
- 시, 분, 초까지 나옴.
- periods 속성은 시작 날짜로부터 n일을 계산하여 더해줌
date.strftime(%년%월%일)이때 대문자와 소문자의 차이가 있다!!
pd.date_range(start='2022-07-01', end='2022-07-25')
createDate = pd.date_range(start="2022-07-01", periods=100)
datelist = []
for date in createDate:
datelist.append(date.strftime('%Y%m%d'))7. DataFrame 정렬
- ascending : 오름차순으로 할꺼냐 내림차순으로 할꺼를 선택
- by : 정렬 기준을 설정
data=[["경상권",2466052, 2431774, 2456016, 2473990],
["수도권",2890451,2632035,np.nan,2466338],
["수도권",9904312,9631482,9762546,9853972],
["경상권",3448737,np.nan,np.nan,3655437]]
ind=["대구","인천","서울","부산"]
col=["지역",2015,2010,2005,2000]
df2 = pd.DataFrame(data, index=ind, columns=col)
df2.index.name="도시"
df2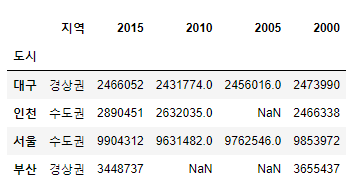
(1) sort_index()
- 인덱스 값을 기준으로 정렬
df2.sort_index(ascending=False)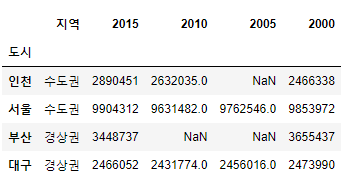
(2) sort_values()
- 데이터 값을 기준으로 정렬
df2.sort_values(by=["지역","2015"])
8. DataFrame 함수적용
(1) apply()
- apply() : 함수를 호출하여 행이나 열 단위로 작업을 하고자할 때 사용하는 함수
- apply(함수명)
- 데이터를 분해해서 함수로 전달 -> 함수에서 처리를 수행 -> 수행결과를 반환해서 재조립(reconstruction : 재구조화 함수)
- axis =1
- 한 행씩 함수로 데이터를 전송
- apply(함수명)
def max_min(x):
return x.max()-x.min()
df4.loc[:"과학",:"4반"].apply(max_min, axis=1)
#result
과목
수학 34.0
영어 47.0
국어 47.0
사회 52.0
과학 68.0
dtype: float649. DataFrame 삭제
- axis = 1 => column이 삭제
- axis = 0 => 행이 삭제
- drop은 적용이 아니기때문에 다시 변수에 담아줘야한다
(1) 행 삭제
- axis = 1
df4 = df4.drop(["평균"], axis=1)(2) 열 삭제
- axis=0
# df4 = df4.drop(["반평균"])10. DataFrame null
(1) fillna()
- 결측치를 채우는 함수
df3 = df3.fillna(0)(2) dropna()
- 결측치를 제거하는 함수 (행 전체가 사라짐)
(3) 범주형 data의 결측치
- 범주형 data에서 결측치를 채우는 방법
- 결측치가 적은 경우 : 데이터수가 가장 많은 클래스로 할당
- 확률적으로 데이터 수가 많은 클래스일 확률이 높기 때문
- 데이터수가 많은 클래스로 변경해야 기존 데이터가 영향을 덜 받기 때문
- 결측치가 많은 경우 :
- 클래스의 데이터 개수 비율별로 쪼개서 할당(랜덤)
- 결측치가 적은 경우 : 데이터수가 가장 많은 클래스로 할당
titanic["Embarked"].value_counts()
#result
S 644
C 168
Q 77
titanic["Embarked"] = titanic["Embarked"].fillna("S")
titanic.info()
11. DataFrame pivot talbe
- pivot table : 원하는 형태로 데이터프레임을 재구조화하는 함수
- pd.pivot_table(dataset, index): index를 기준으로 재구조화
df = pd.DataFrame({'년도':['2015년도', '2017년도', '2015년도', '2017년도'],
'지역':['광주','전남','광주','전남'],
'사과':[500, 450, 300, 600],
'배':[780, 650, 530, 550],
'딸기':[200, 250, 225, 250]})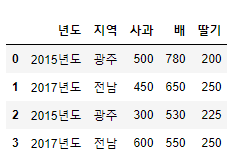
(1) 1개 기준
df1 = pd.pivot_table(df, index=["년도"])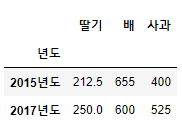
(2) 2개 기준
df2 = pd.DataFrame({"개수":df.groupby(["년도"])["지역"].value_counts()})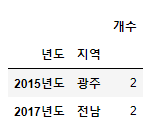

智(지)! 德(덕)! 體(체)!