
1. Crawling
1) 빅데이터란

2) Data Analysis Process
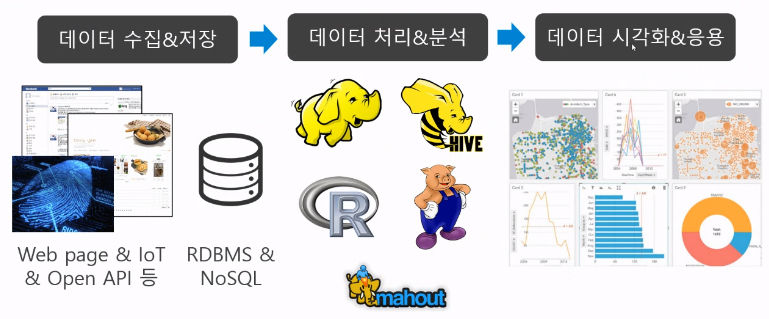
3) Collection Technology Data Type
- 우리는 주로 반정형과 비정형 data를 수집할 것이다.
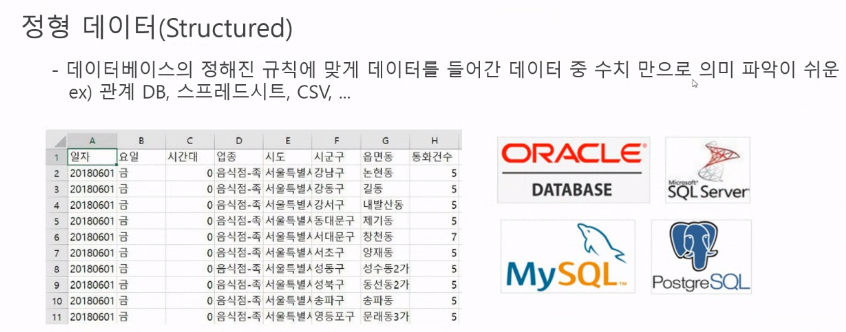
(1) 정형
(2) 반정형

XML은 가운데 사진이고 데이터를 정의할 때 사용한다 즉, 확장형 마크업 언어이다.
CSV는 그때 말한 콤마 기준으로 나눈다.
JSON 구조 파이썬에서는 딕셔너리 스크립트에서는 객체로 언어별로 다향한 형태로 쓰인다.
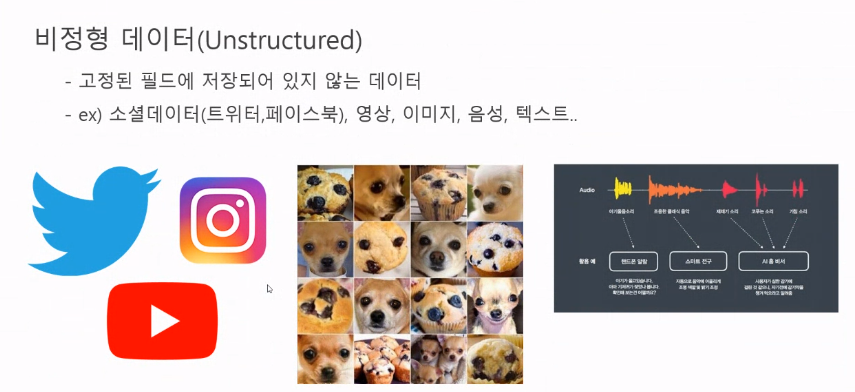
(3) 비정형
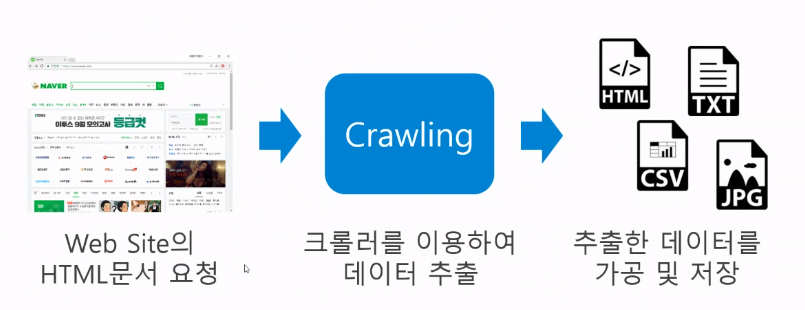
4) Web Crawling
- 웹 사이트의 내용에 접근하여 원하는 정보를 추출해 내는 행위이다.
(1) 고려사항
- Web Page가 어떤 구조(HTML)로 되어있는가
- 어떻게(CSS Selector) 원하는 데이터를 추출할 것인가
(2) 순서
(3) 라이브러리
- requests : 접근할 웹 페이지의 데이터를 요청/응답받기 위한 라이브러리
- beautiful soup : HTML 문서에서 원하는 데이터를 추출하기 쉽게 해주는 라이브러리
- selenium : 추후 포스팅 예정
2. requests library
- 웹 페이지에 보여지는 HTML문서를 요청/응답받기위한 library
- https에서 저장한 상태코드
200 : 정상적으로 요청 / 응답 이루어짐
400번대 : 클라이언트 요청이 잘못되었을 때
500번대 : 서버에 문제가 생겼을 때
1) get()
- url로부터 html 문서를 가져오는 함수
import requests as req
url = "https://www.google.co.kr"
res = req.get(url)
#result
<Response [200]>crtl + u=> 실질적으로 우리가 받아오는 HTML 문서를 확인할 수 있다.- 통상 response를 줄인
res변수에 담아준다.
2) text
- 응답받은 HTML 문서를 출력
res.text

3. BeautifulSoup
- HTML 문서를 분석해서 원하는 정보를 추출할 수 있도록 해주는 library
from bs4 import BeautifulSoup as bs1) bs()
- bs(분석할 html 문서데이터, 분석할 방식)
- 분석방식(속도기준) : lxml > html.parser > html5lib
html = bs(res.text, "lxml")
그럼 res.text와 bs(res.text, "lxml")의 차이점은 무엇인가?
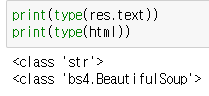
- 분석 가능한 Beautiful Soup냐 아니면 그냥 일반 String 값이냐의 차이이다.
2) Css 선택자
- 30가지가 넘는 Css 선택자중 최소 아래 4개는 꼭 알아두고 가자
- 태그 선택자 (태그 이름)
- 아이디 선택자 (#)
- 클래스 선택자 (.)
- 계층 선택장(자식(>), 자손(공백), 근접후행(+), 후행(~))

- 위와 같이 class tag에 띄어씌여있는 부분과
_로 이어져 있는 부분이 있는데 띄어씌여있는 부분은 다른 class tag로 class 선택자인.으로 구별을 해주어야하고_로 되어있는 부분은 하나의 class tag로 처리해주어야한다.
(1) CSS 선택자를 활용한 data 추출법
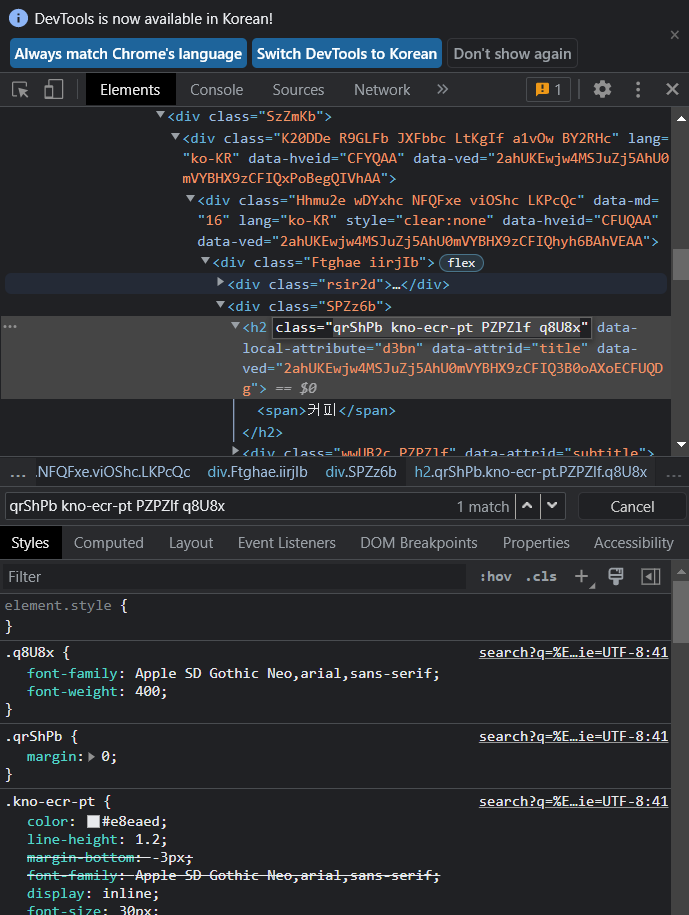
- 위와 같은 상태에서 ctrl+f를 누르면 추가적으로 더 있는 검색을 할 수 있다.
클래스 특징 자체가 앞서 언급한 것 처럼 공통된 속성이 있을 수 있기 때문에 앞에tagname까지 붙여줘서 조금더 결과값을 걸러줄 수 있다.
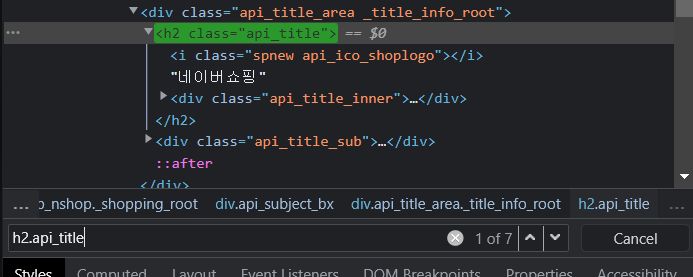
- 위의 사진은
h2.api_title과 같은 class가 7개 있는 것을 확인할 수 있다. - 다음 사진은 같은
rankclass를 갖고 있을 때 CSS 선택자를 조금 더 세밀하게 구별하여 원하는 값을 찾을 경우이다.
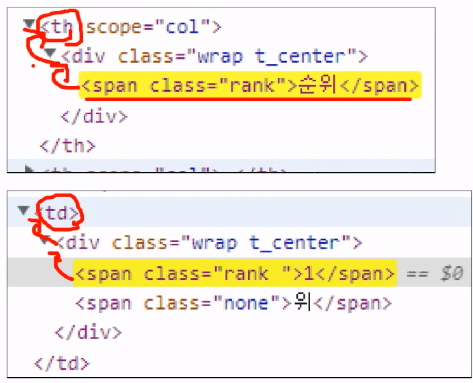
td > div > span이나td span으로 찾을 수 있다.
3) select, select_one()
(1) select_one()
- CSS선택자를 이용하여 HTML문서 내 원하는 정보를 추출
html.select_one("title").text- 하지만 UI에는 보이는데 값이 크롤링이 안 되는 경우가 있다. 이는 첫번째로 코드에 의해서 출력되는 내용이라고 볼 수 있다. 그러면 Beautiful Soup로는 크롤링이 안 되고 나중에 배울 Selenium으로 크롤링을 진행해야한다.
html.select_one("h2.qrShPb.kno-ecr-pt.PZPZlf.q8U8x")
#result
오류X, 결과값X(2) select
- list로 값아 넘어온다
- 선택자조건에 맞는 모든 html객체를 접근할 때 조건문도 가능하지만 변수자체에 limit을 걸어서 결과값을 조정할 수 있다.
- limit : 접근할 html객체의 수를 정의
products = html.select("div._page_group a.title", limit=8)
for product in products:
print(product.text)
4) get()
- HTML 객체의 속성값 접근
html.select_one("a.title.elss").get("href")

智(지)! 德(덕)! 體(체)!