
1. 네이버 뉴스기사 수집
1) user-agent란?
- 우선 배운대로 크롤링을 시작해보자
news_url="https://n.news.naver.com/mnews/article/449/0000230998?sid=103"
res = req.get(news_url)
html = bs(res.text, 'lxml')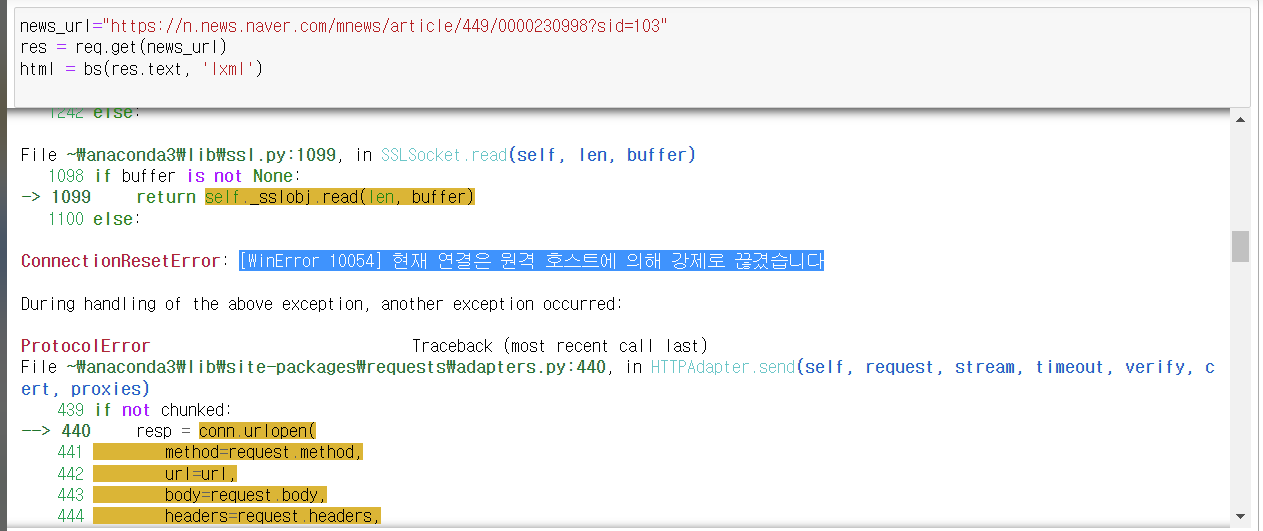
- 위와같이 하면 error가 발생됨 why?
server에서 프로그램으로 요청을하는건지, 사람이 클라이언트로 요청을 하는건지 JSP에서 판독하는데 이때user-agent가 null 값이면 그냥 끊어버린다.

- 따라서 가장 중요한
user-agent부분을 꼭 채워서 server로 보내줘야한다. 요청할 때 이 값을 구성해서 요청하면 강제종료에 대한 문제를 해결할 수 있다.
news_url="https://n.news.naver.com/mnews/article/449/0000230998?sid=103"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
res = req.get(news_url, headers=header)
html = bs(res.text, 'lxml')2) 뉴스제목, 내용 크롤링하기
앞서 언급한대로 진행을 했다면 html변수안에 해당하는 웹 페이지의 HTML문서가 잘 들어갔을 것이다.
이제 우리는 여기서 해당하는 제목과 내용을 꺼내오면 된다.
뉴스 제목
title = html.select_one("h2.media_end_head_headline")
print(title.text)
#result
[날씨]오늘 ‘중복’ 무더위 기승…곳곳 소나기 소식뉴스 내용
content = html.select_one("#dic_area")
content.text
- 위와같이 보기 어지러운 내용이 나온다 그 이유는 web상에서는 아무리 enter을 쳐도 1개로밖에 인식이 되지 않는다 그것을 해소하고자 다음과 같은 특수 문자가 들어있다 하지만 우리가 보기 편하게 하기위해
print()함수와strip()함수를 동시에 써서 인간친화적인 문구로 바꾸어보자
content = html.select_one("#dic_area")
print(content.text.strip())
2. 멜론 음원차트 수집
- 순위, 곡명, 아티스트, 앨범이미지주소를 1위부터 100위까지 수집
- csv파일로 저장
import requests as req
import pandas as pd
from bs4 import BeautifulSoup as bs- 우선 필요한 크롤링 lib들과 csv로 저장하기 위한 pd를 load 해주자
melon_url = "https://www.melon.com/chart/index.htm"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
res = req.get(melon_url, headers = header)
html = bs(res.text, 'lxml')- 크롤링할 url 주소와
user-agent를 준하고 requests lib을 사용하여 res에 String형태로 담아주고 분석을 하기위해 HTML 변수에 beautifulSoup 형태로 변환하여 담아준다.
ranks = html.select("td > div > span.rank")
songNms = html.select("div.ellipsis.rank01 a")
artists = html.select("div.ellipsis.rank02 > span")
albumImgs = html.select("a.image_typeAll>img")-
개발자 툴을 열어 크롤링할 CSS 선택자들을 찾고 원하는 data개수가 맞는지도 확인한다.

-
4개의 빈 리스트에 데이터를 저장해보자
// 빈 배열 선언
rankslist = []
songNmlist = []
artistlist = []
albumImgslist = []
// 어차피 개수는 모두 100개로 동일하니 대표로 ranks를 for문에 부여
for i in range(len(ranks)):
rankslist.append(ranks[i].text)
songNmlist.append(songNms[i].text)
artistlist.append(artists[i].text)
albumImgslist.append(albumImgs[i].get("src"))- Dictionary와 연결형 data를 이용한 DataFrame 작성
melon_dic = {
"순위":rankslist,
"곡명":songNmlist,
"아티스트":artistlist,
"앨범이미지":albumImgslist
}
melon_df = pd.DataFrame(melon_dic)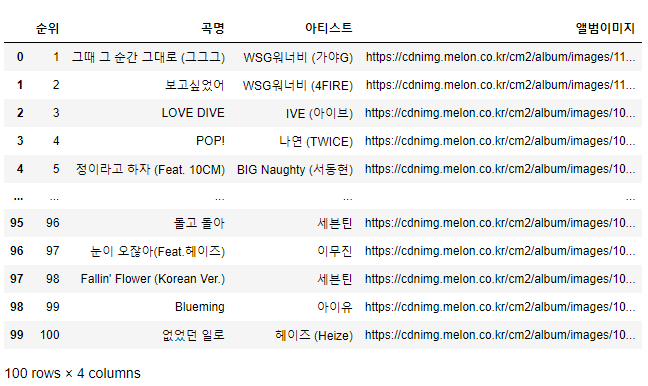
- CSV 파일로 저장 앞서 배웠듯 DataFrame에 한글이 들어있다면 반드시 encoding을 해줘야함
melon_df.to_csv("melon_top100.csv", encoding="euc-kr", index=False)따로 path를 지정해주지 않는다면 작성하는 file의 folder에 자동으로 저장됨.
또한 0~ 나아가는 default index가 싫다면 index=False를 통하여 index 제거 가능.

智(지)! 德(덕)! 體(체)!