앞으로 몇 번의 포스팅을 통해 인과추론 개념을 추천시스템에 적용한 논문들을 정리한 survey 논문을 정리하려 한다. 논문명은 "Causal Inference in Recommender Systems: A Survey and Future Directions" 이다. 해당 논문은 survey 논문인 만큼 매우 분량이 많기 때문에 여러 포스팅에 걸쳐서 하려고 한다. 이번 포스팅은 추천시스템의 문제점 및 인과추론의 필요성에 대해 주로 얘기하려한다. 이를 이해하기 위해서는 추천시스템과 인과추론에 대한 기초지식을 가지고 있어야 한다.
1. 서론
현재 머신러닝 기반의 추천시스템은 상관관계(correlation)을 모델링한다. 하지만, 현실 세계는 상관관계가 아닌 인과관계로 구성되어 있고, 상관관계는 인과관계를 암시하지 않는다.
예시: 어떤 유저는 휴대폰을 구매한 다음 배터리 충전기를 구매하는 경우, 전자는 후자의 원인이 되지만 그 반대 방향은 성립되지 않는다. 유저가 충전기를 먼저 구매한 다음에 휴대폰을 구매할 확률은 매우 적다고 볼 수 있다. 만약 우리가 상관관계만 모델링한다면 이러한 인과관계성을 포착할 수 없고 모델 성능이 떨어질 수밖에 없다. 구체적으로, 상관관계 기반의 추천시스템의 문제점은 아래와 같다.
상관관계 기반의 추천시스템의 문제점
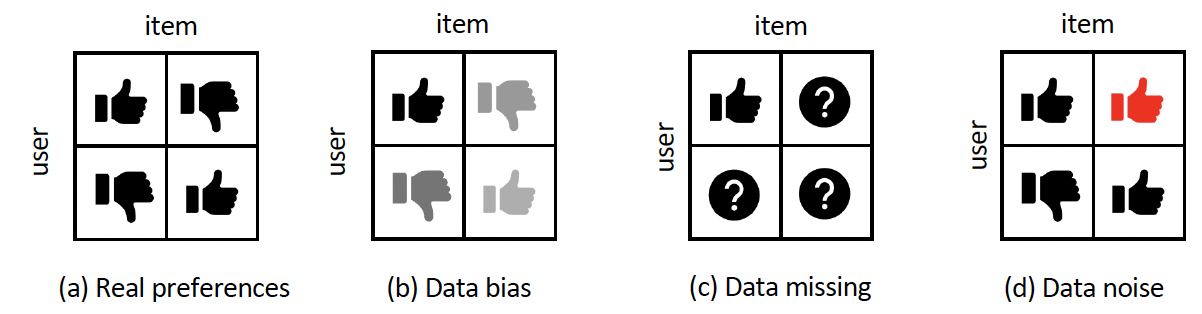
1. 데이터 편향(Data Bias): 우리가 실제로 관측 및 수집하는 데이터는 유저-아이템 상관관계를 포착하는 데이터로, 순응 편향(conformity bias), 인기 편향(popularity bias), 노출 편향(exposure bias) 등 여러 종류의 bias를 포함한다. 예시로 든 bias에 대해서는 밑에서 더욱 자세하게 설명하겠다. 이러한 데이터로 추천 모델을 학습하게 되면 낮은 추천 성능을 보이게 된다.
2. 데이터 누락 혹은 노이즈(Data Missing or Noise): 수집 파이프라인으로 인해 우리는 노이지하거나 완전치 못한 데이터를 얻게 된다. 예를 들어, 보통 유저들은 매우 작은 양의 아이템과 상호작용(클릭, 구매)하고 그 외에 수만 개의 아이템과의 상호작용은 관측되지 않는다. 그러면 수집한 데이터는 깨끗하냐? 실제로 그렇지 않고 노이즈가 많이 껴있다. 잘못 클릭했거나, 클릭했다고 해도 긍정적인 의미로 한 것이 아니라 부정적인 감정으로 했거나..
이를 해결하기 위해 많은 연구들이 진행되고 있는데 최근에는 인과추론 개념을 적용하여 눈으로 관측되는 상관관계를 학습하는 것이 아닌 인과관계를 모델링한 후 이를 학습한다.
인과관계 기반의 방법 분류
1. Data Debiasing: 인기 편향과 노출 편향은 Backdoor adjustment를 통해 완화한다.
2. Data Augmentation and data denoising: 데이터 누락을 해결하기 위해 반사실적 추론(counterfactual reasoning)을 활용하여 데이터 증대(data augmentation)을 하고, inverse propensity weighting (IPW) 기법을 활용하여 인과적 영향를 추론한다.
2. 인과추론이 왜 추천시스템에 필요할까?
1) 데이터 편향(Data Bias)
(1) 데이터 편향의 문제점
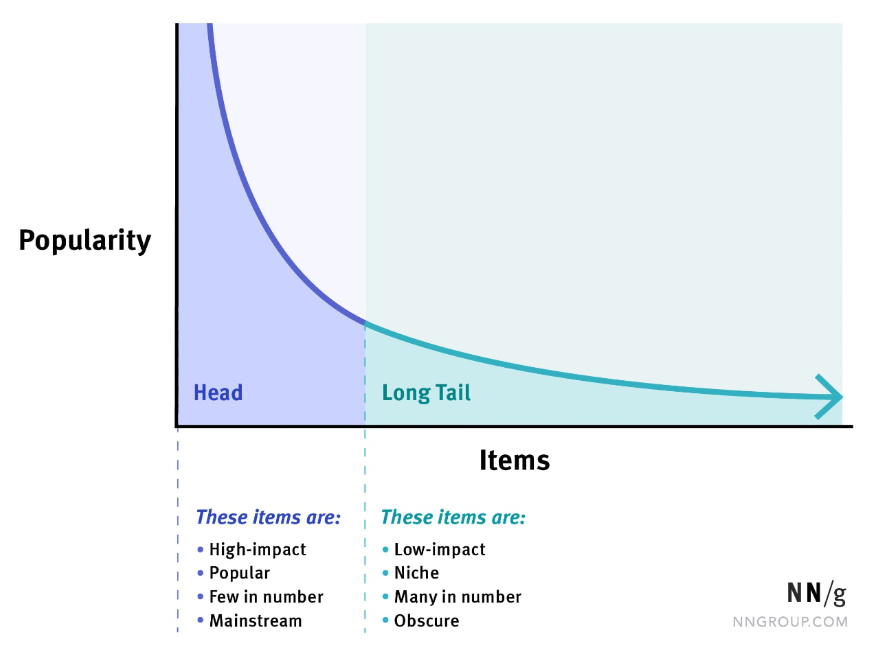
- 인기 편향(popularity bias): 추천 시스템은 대개 사용자의 행동 기록을 기반으로 학습된다. 만약 특정 항목이 이미 많은 사용자에게 선호되어 선택되었다면, 해당 항목은 더 많은 클릭, 구매, 또는 평가를 받을 것이며, 이는 해당 항목을 더 많이 추천받게 된다. 보통 과거 행동 기록을 보면 long-tail 분포를 따르고 모델이 이를 학습하게되면 자주 상호작용하는 아이템에는 높은 추천 점수를 내뱉는 반면 다른 아이템에는 낮은 점수를 내뱉는다. 사용자가 추천된 인기 있는 항목을 선택하게 되면, 해당 항목은 더 많은 피드백을 받아 선호도가 높아지게 된다. 이로 인해 추천 시스템은 해당 항목을 더 자주 추천하게 되어 역순으로 피드백 루프가 형성될 수 있다. 이는 다양성과 개인화 측면에서 문제가 될 수 있다.
- 순응 편향(conformity bias): 사용자들이 다수의 의견이나 행동에 순응하려는 경향을 나타낸다. 다시 말해, 다수의 선택이나 선호에 따르려는 성향을 의미한다. 이러한 편향은 주로 소셜 커머스 플랫폼이나 리뷰 기반의 추천 시스템에서 나타날 수 있다. 이 편향이 지속적으로 나타날 경우, 다양성과 개인화 측면에서 문제가 될 수 있다. 일부 사용자의 선호나 의견이 지배적으로 나타나면, 다른 사용자들은 그러한 다수의 흐름에 따라 선택하게 되어 자신만의 다양한 경험을 갖기 어려워진다.
- 노출 편향(exposure bias): 노출 알고리즘이 유저 피드백 수집에 영향을 끼친다.
(2) 인과추론을 활용한 데이터 편향 제거(debiasing)
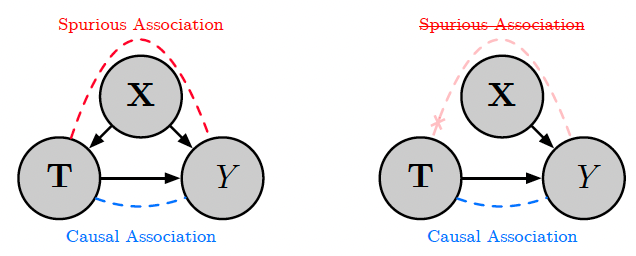
데이터 편향이 발생되는 원인은 backdoor path 때문이다.
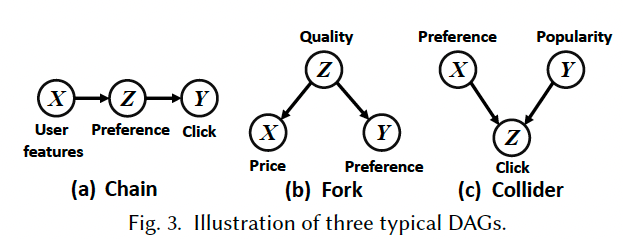
위 그림에서 (b)를 보면 confounder (Z)가 input (X)와 output (Y)에 동시에 영향을 주고 있다. 이러한 backdoor path로 인해 가짜 상호작용 (spurious correlation)이 발생하게 되고, 이로 인해 X와 Y 사이의 진짜 인과적 상호작용 (causal correlation)보다 더 overestimate된 X와 Y 사이의 관계를 우리는 관측하게 된다. 우리는 이러한 Z를 confounding bias라고 부른다.
예를 들어, 아이템 인기도는 노출 확률에 영향을 주게 되는데 우리가 아이템 인기도를 고려하지 않으면 협업 필터링은 인기 있는 아이템에 지속적으로 높은 추천 점수를 부여하기 되고 양성 피드백으로 인해 over-recommendation 현상이 발생하게 된다. 이것이 인기 편향이며 여기서 아이템 인기도를 confounding bias라고 볼 수 있다.
인과추론 관점에서 보면 X를 treatment, Y를 outcome 변수라고 볼 수 있고, 우리가 실제로 원하는 것은 X가 Y에 다이렉트하게, 직접적으로 끼치는 영향만 보고 싶은 것이다. Confouding bias (Z)로 인해 추가적으로 생성되는 영향을 제거해야 우리가 원하는 바를 관측할 수 있다. 그리고 이러한 편향을 없앤 채로 데이터를 수집하고 추천 모델을 해당 데이터로 학습시키면 추천 모델도 편향을 안 갖게 된다. Z의 영향을 없애는 인과추론 방법은 여러가지가 존재하면 자세한 내용은 다음 포스팅에서 다룰 예정이다.
2) 데이터 누락 혹은 노이즈(Data Missing or Noise)
(1) 데이터 누락
추천시스템이 활용하는 데이터는 대개 한정적이면 모든 유저-아이템의 상호작용을 확인할 수 없다. 예를 들어, 유저는 대개 적은 개수의 영화에만 평점을 매기거나, 카메라 구입했을 때 카메라 렌즈와 필름을 구매한 기록은 남지 않는다. 그렇기 때문에, 관측되는 데이터가 실제로 유저의 모든 성향을 반영했다고 보기 힘들다. 이러한 데이터로 학습하게 되면 sub-optimal한 결과를 얻게 된다. 노출 편향에서 얘기했던 것처럼, 추천시스템의 아이템 노출 알고리즘으로 인해 유저는 특정 몇 개의 아이템에만 보게 된다. 또한, 대다수의 유저는 피드백 주는 걸 거부하는데, 이는 Douban이라는 영화 평점 웹사이트에서 확인할 수 있다. 이러한 요소들로 인해 유저의 선호도를 모델링하는 것이 쉽지 않게 된다.
우리는 인과추론을 통해 데이터 생성 매커니즘을 모델링할 수 있으며, 전문적으로 이를 Data Generating Process (DGP)라고 부른다. 이는 data-driven 모델에 사전지식으로 넣어줄 수 있고 이를 통해 데이터 누락 문제를 완화시킬 수 있다.
(2) 데이터 노이즈
추천시스템을 떠나서 다양한 도메인에서 얻게 되는 데이터는 전부 노이즈가 껴있다. 예를 들어, 암시적 상호작용(implicit interaction)의 경우 유저가 특정 아이템을 클릭했다고 반드시 이를 긍정 레이블로 볼 수 없다. 실수로 잘못 클릭했거나, 실제로 그 아이템을 클릭 및 구매 후에 부정적인 코멘트를 남길 수도 있다. 반대로, 유저가 노출된 아이템을 클릭하지 않았다고 이를 부정 레이블로 보는 것도 위험하다. 우리가 스크롤하다보면 알겠지만 모든 아이템을 다 보지 않고 스크롤을 내리는 경우가 많은데 그 중에서 유저가 실제로 선호할 아이템이 있을 수도 있다. 혹은, 악의적으로 노이즈를 만들어 내기도 하는데 TikTok에서는 본인의 컨텐츠를 과다 노출시키고 싶어서 많은 가계정을 생성한 후 클릭을 한다거나, Amazon의 경우 가짜 구매 기록 혹은 긍정 평가를 남긴다고 한다.
이러한 외부적인 요소들을 무시한 채로 그냥 관측된 데이터로 학습을 하게 되면 실제 유저의 선호도를 알아내기 힘들 것이다. 그렇기 때문에 인과관계성을 알아내기 위해 인과추론 기법을 적용하는 것이다.
