PPT 자료
https://drive.google.com/file/d/1fpqUumXEKrFhA6QKacRArHW1h7s3jRPH/view?usp=sharing
세 줄 요약
- Deeplight는 기존의 FM + DNN 기반의 모델의 복잡도가 높아 online serving시 오랜 시간이 걸린다는 단점을 보완한 모델이다. 즉, CTR 예측을 훨씬 빠르고, 잘하는 모델이다.
- 위를 달성하기 위해서, FwFM이라는 모델을 도입하여 추천 성능을 향상시켰고, structural pruning 알고리즘을 적용하여 모델 성능에 불필요한 parameter를 지워 복잡도를 낮췄다.
- 모델 inference 속도는 다른 모델에 비해 Criteo 데이터셋에서 최대 46배, Avazu 데이터셋에서 최대 27배 빠르며, 성능 저하는 없다.
등장 배경
1) 최신 CTR 예측 모델의 문제점
Wide&Deep 모델을 기점으로 최신 CTR 예측 모델은 shallow component (FM) 와 deep component (DNN)로 구성되어 있다. 예를 들어, 전에 소개한 DeepFM, NFM, 그리고 xDeepFM이 그 예시다. 이 모델들은 모두 좋은 CTR 예측 성능을 가진다.
하지만, 좋은 성능을 보이기 위해 DNN의 layer수를 증가하거나, 새로운 모델을 추가하여 모델의 복잡도를 증가시켰다. 따라서, CTR 예측 속도가 느려지고, latency가 증가하고, 메모리 사용량이 증가하여 online serving 시 문제점이 발생한다. Ad serving에서 latency 문제는 매우 큰 이슈다. 좋은 추천 성능을 보인다고 한들, 그 시간이 오래 걸리면 사용자는 그 추천시스템을 사용하지 않을 것이다.
2) Deeplight
Deeplight는 위의 문제점을 보완하는 동시에, 좋은 추천 성능을 보이는 모델이다. 이전 모델과의 차이점은 다음과 같다.
- Shallow component: FwFM 구조를 활용하여 유익한 특징 상호작용 (feature interaction)을 찾는다.
- Deep component에서는 중간 layer나 임베딩 벡터의 weight 중 성능 향상에 불필요한 parameter들을 지운다.
자세한 설명은 아래에서 하겠다.
구조 (Architecture)
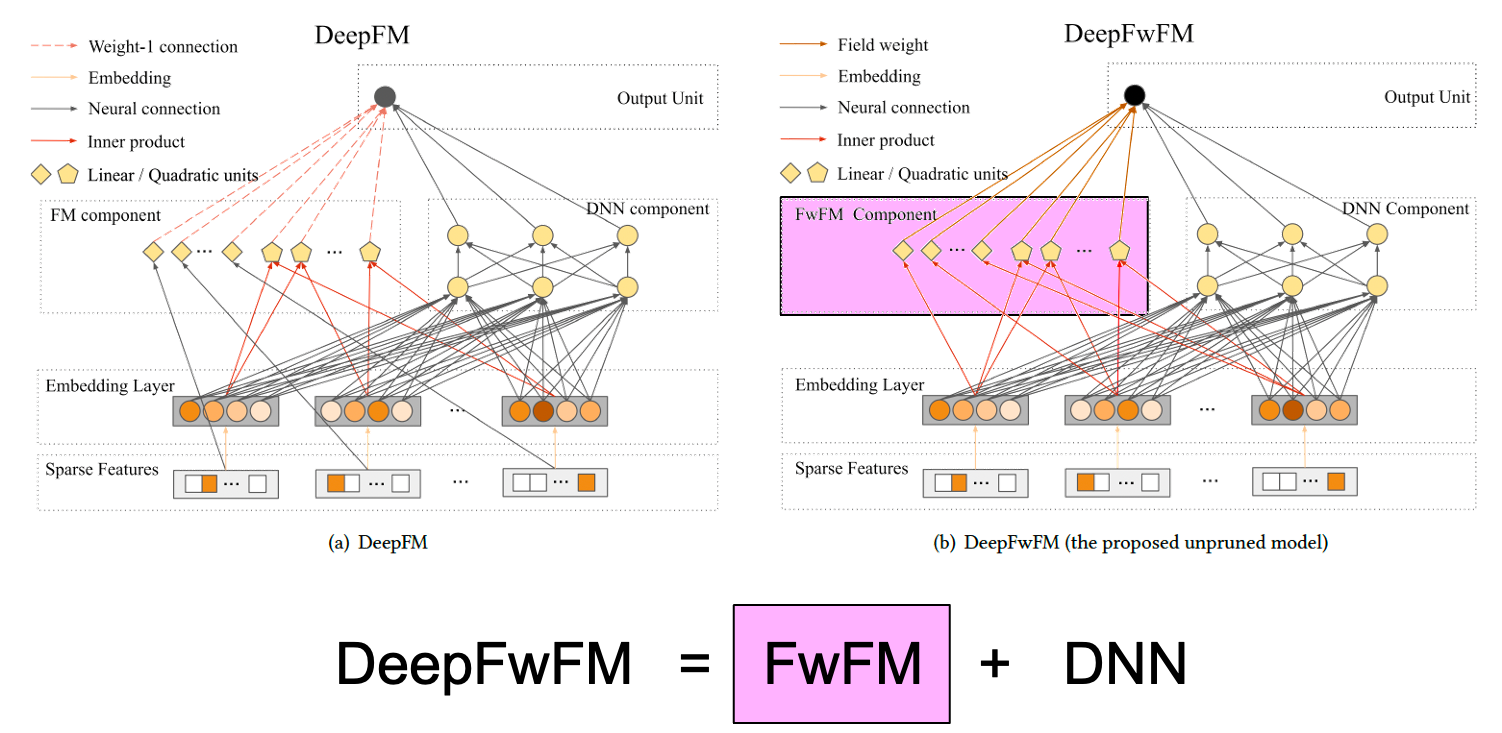
Deeplight 구조를 한 줄로 설명하면 다음과 같다: Deeplight = DeepFwFM + pruning algorithm .
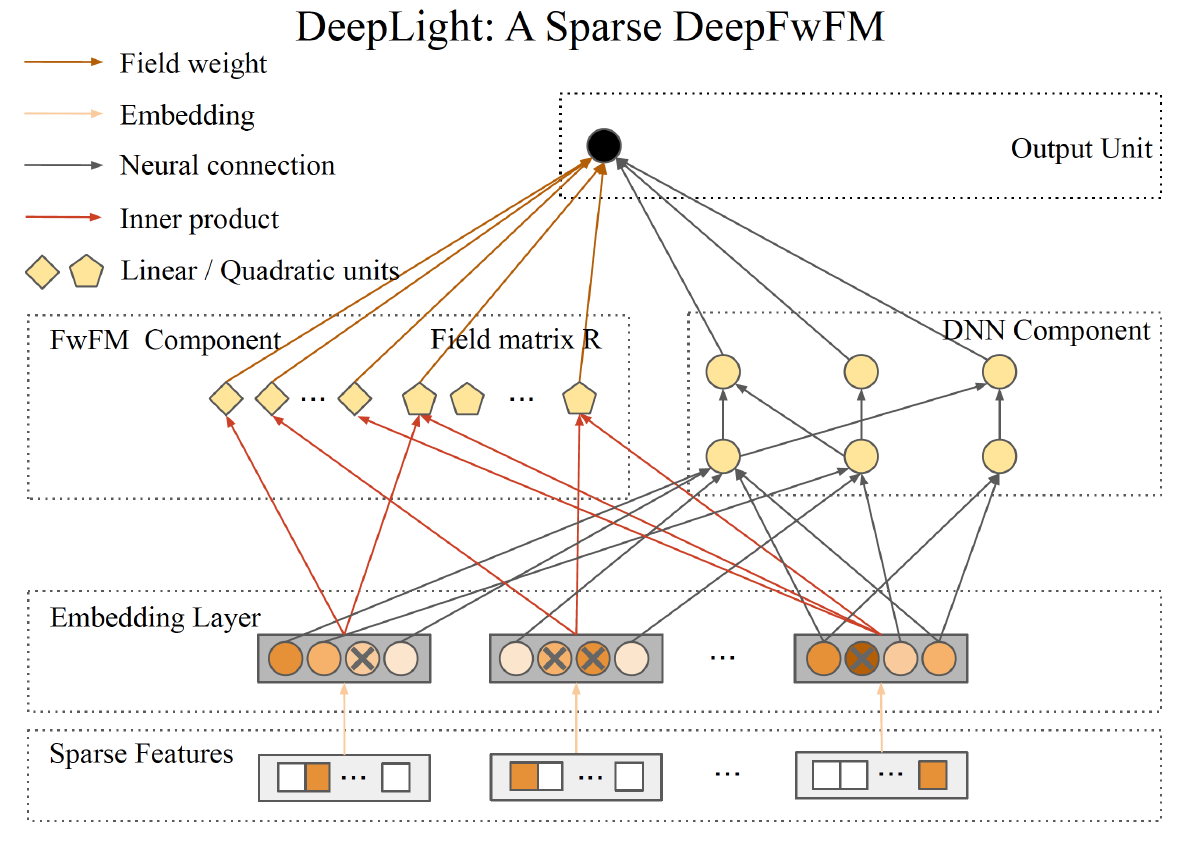
1. DeepFwFM
DeepFwFM는 또 한 줄로 설명하면 다음과 같다.
DeepFwFM = FwFM + DNN
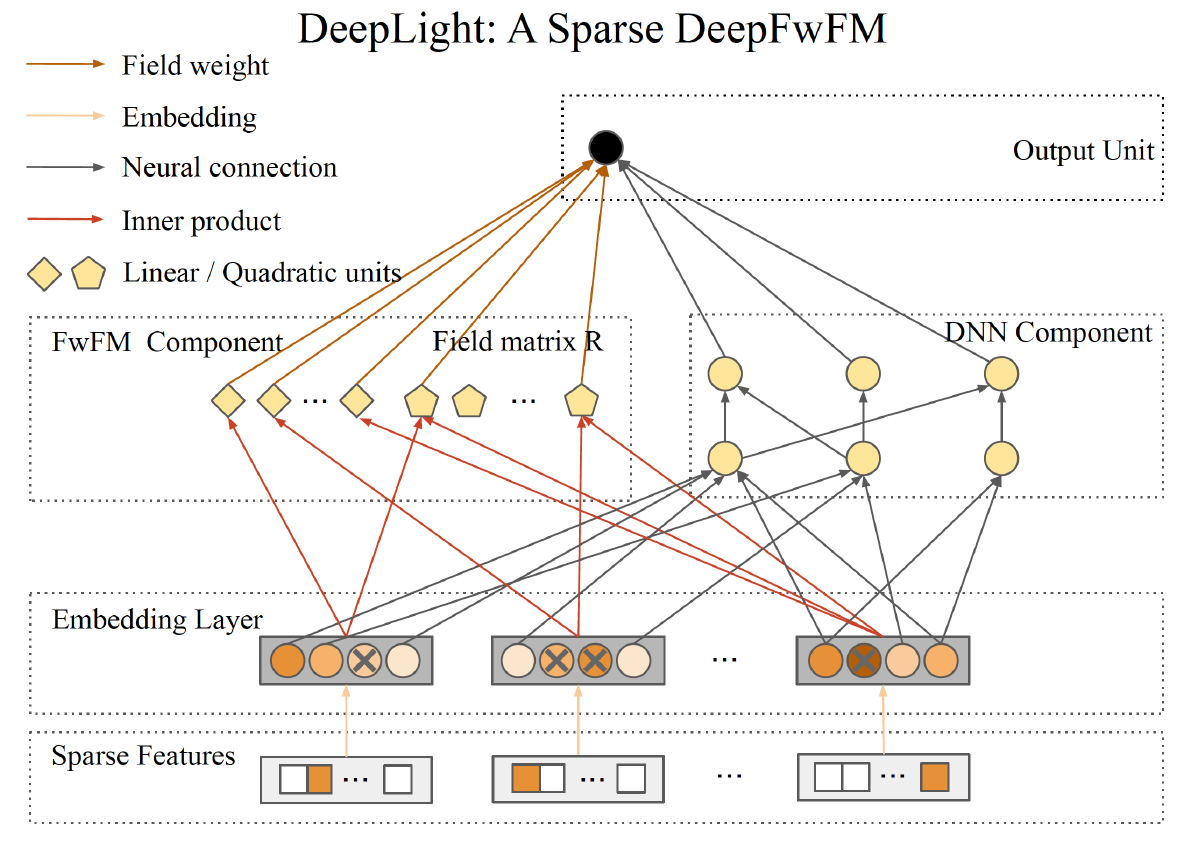
2. Pruning 알고리즘
DeepFWFM 모델에서 pruning을 할 수 있는 모델은 3가지가 있다: 1) DNN; 2) FwFM에서의 field pair Matrix; 그리고 3) Embedding 층이다. 이 3가지 구조의 weight를 pruning 하여 모델의 복잡도를 감소시킨다. 논문에서 제시한 pruning 알고리즘은 다음과 같다.

- 먼저, 얼마만큼의 weight를 지울지 (sparse rate ), 그리고 damping ratio ()를 설정한다.
- Warm up 용도로 첫 몇 epoch동안 모델을 학습한다.
- 다음과 같은 작업을 반복한다: 1) 모델을 한 iteration 동안 학습시키고; 2) sparse rate()를 damping ratio만큼 감소시키고; 3) 모델의 weight 중 하위 크기를 가진 weight를 pruning한다.
실험 결과 (Experimental results)
해당 논문에서는 Criteo, Company dataset 이 두 개의 데이터셋에 대해서 실험을 진행한다. 평가지표로는 AUC와 log loss로 삼았다. 아래 표는 pruning하기 전인 DeepFwFM의 성능을 보여주고 AUC는 높고, log loss는 낮은 것을 알 수 있다.

다음은 sparse 비율에 따른 모델의 성능을 측정했다. [그림 1]은 DNN component에 pruning을 적용시켰을 때의 성능으로, 98%를 지워도 AUC 저하는 없었으며, latency는 16배 빠른 것을 보여준다.
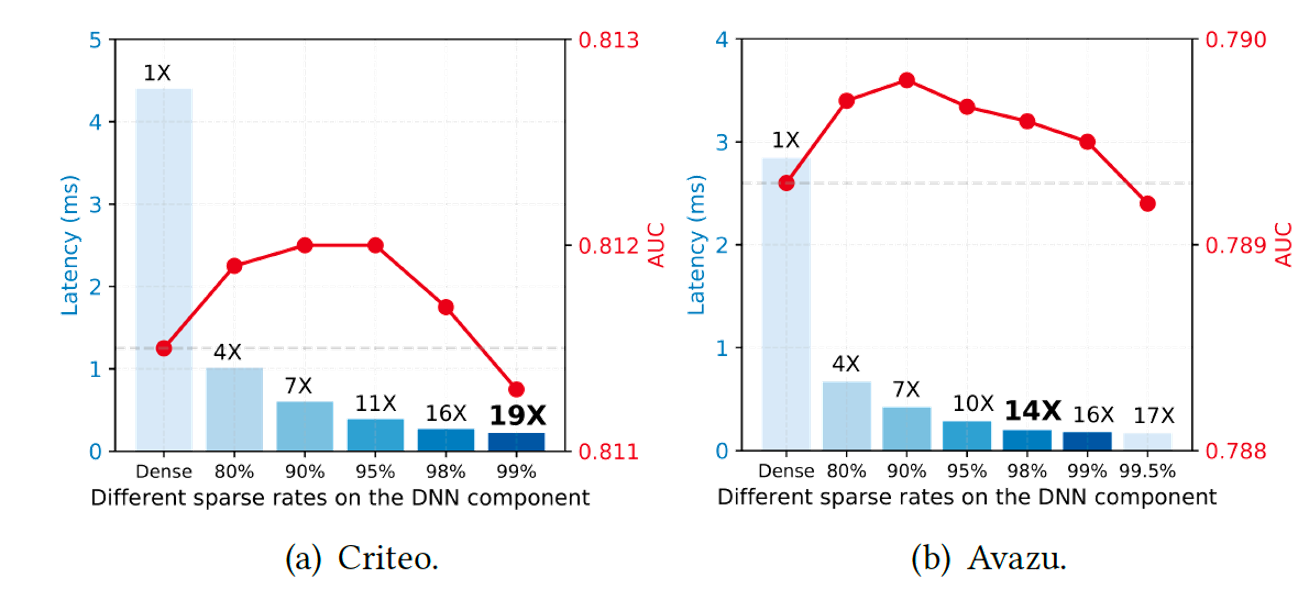 [그림 1]. DNN component에서 sparse 비율에 따른 AUC 및 latency 비교
[그림 1]. DNN component에서 sparse 비율에 따른 AUC 및 latency 비교
[그림 2], [그림 3]은 각각 field pair 행렬, 임베딩 벡터에 pruning을 적용시켰을 때의 성능 측정한 그림이다. 각각 95%, 40~60%를 지워도 성능에 저하가 없다는 걸 알 수 있다.
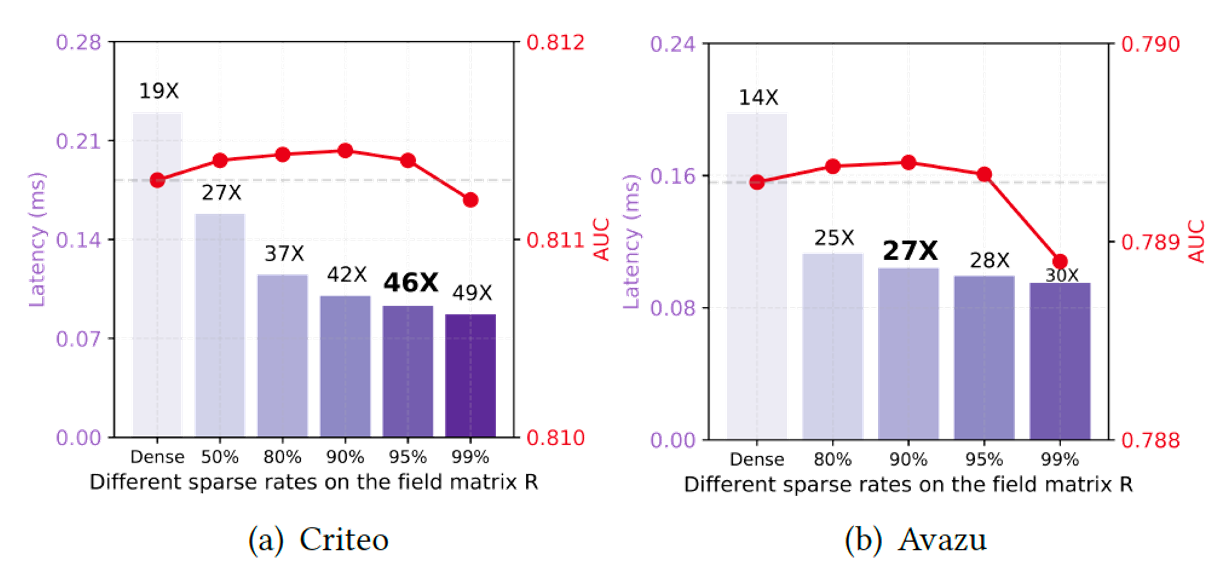 [그림 2]. Field pair 행렬에서 sparse 비율에 따른 AUC 및 latency 비교
[그림 2]. Field pair 행렬에서 sparse 비율에 따른 AUC 및 latency 비교
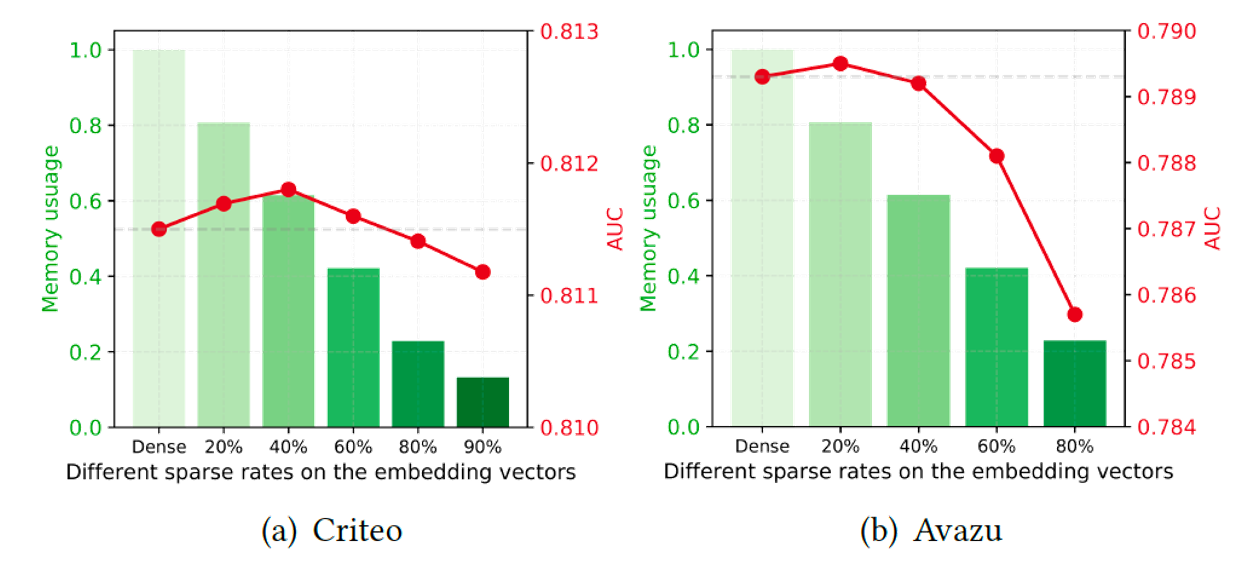 [그림 3]. 임베딩 벡터에서 sparse 비율에 따른 AUC 및 latency 비교
[그림 3]. 임베딩 벡터에서 sparse 비율에 따른 AUC 및 latency 비교
