PPT 자료
https://drive.google.com/file/d/1R0em5fXqs2nc6un_j1n-3hVtrHn_gApK/view?usp=sharing
세 줄 요약
- DeepFM은 1) 추천 성능이 좋은 Factorization machine과; 2) feature들 간의 상호작용을 잘 파악하는 딥러닝 모델을 활용하여 CTR 예측을 빠르고, 잘하는 모델이다.
- 기존의 Wide&Deep model과 달리, 1) feature engineering이 작업이 불필요하다는 점; 2) factorization machine과 deep learning model에 입력으로 들어가는 input feature가 같아 end-to-end 학습이 가능하다.
- 다른 모델에 비해 학습시간이 짧고 (복잡도가 낮고), 추천 성능 지표인 AUC (Area Under Curve)가 높다.
등장 배경
1) CTR (click-through ratio)
우리 모두 알다시피, 추천시스템은 특정 유저가 선호할만한 아이템을 추천해주는 시스템이다. 영화를 추천해주는 Netflix나 상품을 추천해주는 amazon 모두 추천시스템의 한 예시다. 그렇다면, 추천시스템의 성능은 어떤 지표로 평가가 가능할까? 바로 클릭수다. 추천해준 아이템의 클릭수가 많다면 추천시스템이 추천을 잘 해준다고 볼 수 있다.

하지만, 단순히 클릭수로 판단하면 안 된다. 예를 들어, 아이템 1은 유저들에게 1,000번 노출(impression)되어 100번 클릭된 반면, 아이템 2은 유저들에게 100번 노출되어 20번 클릭되었다고 보자. 클릭수는 아이템 1이 아이템 2에 비해 5배 많지만, 노출수 또한 10배 많다. 만약, 노출수 대비 클릭수로 본다면 아이템 1은 100/1000 = 0.1, 아이템 2는 20/100 = 0.2로 아이템 2의 효율이 더 좋다. 위의 예시를 볼 때, 아이템이 유저들에게 얼마나 노출되었는지도 고려해야 한다. 따라서, CTR(click-through ratio)는 다음과 정의가 된다.
2) CTR 예측을 잘 하는 법
추천을 잘 해주기 위해서는 CTR 예측을 잘 하는 것이 중요하다. CTR은 클릭할 확률로 해석할 수 있기 때문에 CTR 예측을 잘 하여 높은 CTR값의 아이템을 추천해준다면 추천 성능은 향상될 것이다. 그렇다면, CTR은 어떠한 변수에 영향을 받을까? 바로 유저와 관련된 특징들의 상관관계(feature interaction)이다. 여기서 특징 유저, 아이템와 관련된 성질이 될 수 있다 (예: 유저의 나이, 거주 위치). Feature interaction 예시는 다음과 같다.
저녁 시간에 배달 앱을 많이 다운로드 한다
시간대 (특징 1)와 앱 카테고리 (특징 2) 사이에 상관관계가 있다
서로 상관관계에 있는 특징의 개수에 따라 저차원, 혹은 고차원 특징 상호작용로 분류할 수 있다.
(1) 저차원 특징 상호작용 (low order feature interaction)
위의 예시는 시간대, 앱 카테고리 두 개의 특징이 고려되었기 때문에 2차원 특징 상호작용이라 할 수 있다. 저차원 특징 상호작용은 주로 linear model에 의해 파악된다. DeepFM은
(2) 고차원 특징 상호작용 (high order feature interaction)
남자 (성별) 청소년 (나이)을 RPG 게임 (앱 카테고리)을 많이 다운로드 한다
위의 예제는 3개의 특징이 상호작용하는 3차원 특징 상호작용(three-order feature interaction)의 예시다.
위의 예시는 크게 어렵지 않지만, 일반적으로 고차원 특징 상호작용은 복잡하기 때문에 linear 모델에 의해 파악되기 힘들다. 따라서, non-linear 모델을 많이 사용하고 특히 성능이 좋은 deep learning 모델이 사용된다.
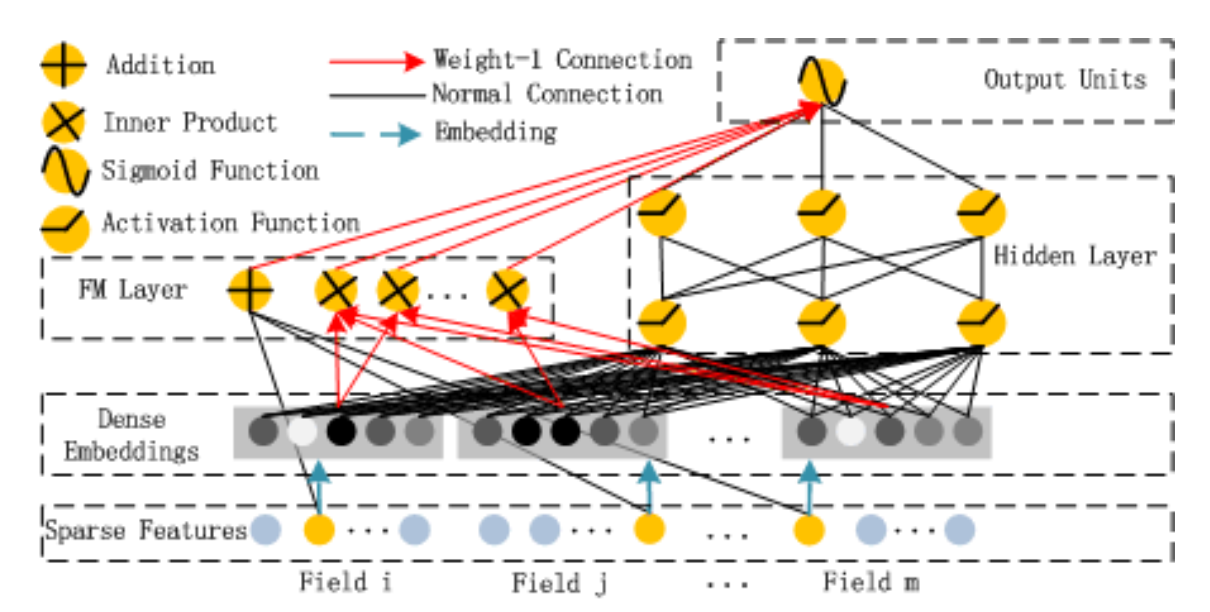
구조 (Architecture)
앞서 말했던 것처럼, DeepFM은 1) Factorization machine component; 2) deep component로 이루어져 있다.
1. Factorization machine component
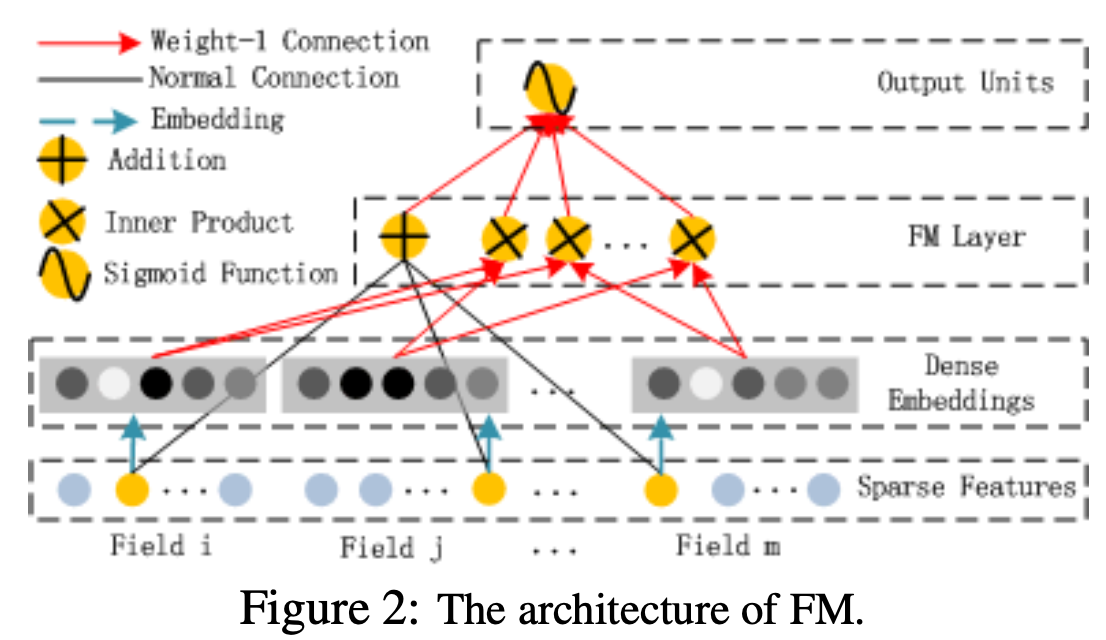
자세한 내용은 < Factorization machines >을 참고하면 된다.
2. Deep component
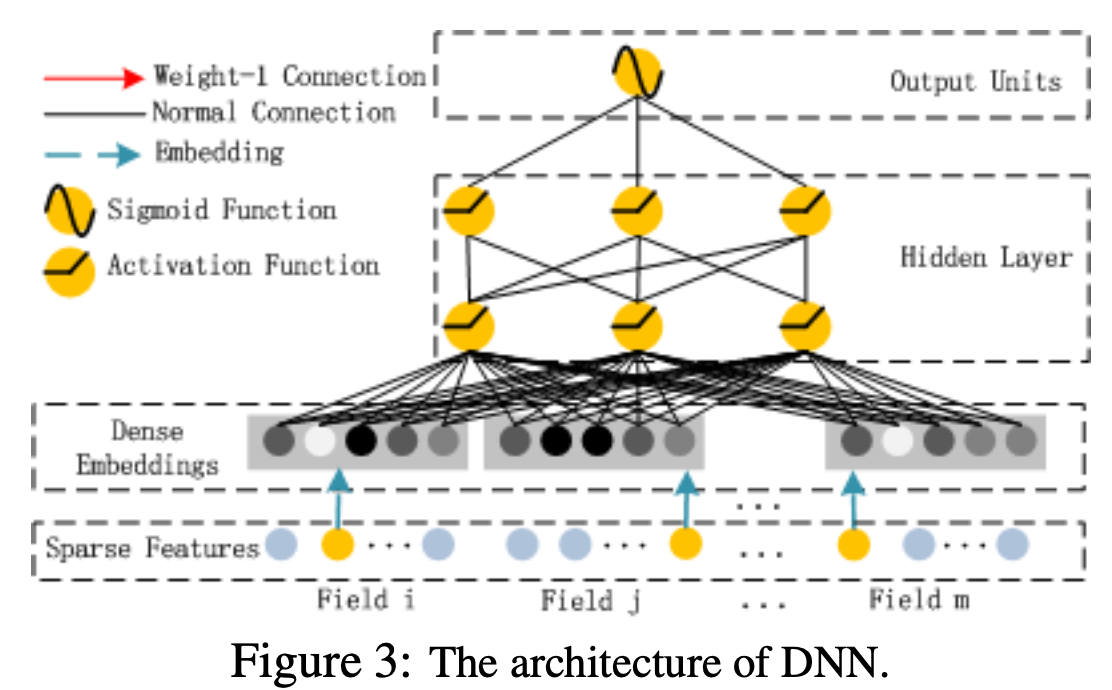
Deep component는 간단하다. FM component에서 만든 임베딩 벡터들을 DNN에 입력으로 넣고 스칼라 값을 output 하는 게 전부다. Wide&Deep 모델과의 차이점은
(여기서 알 수 있다시피, 임베딩 벡터들의 모든 요소들을 모두 DNN에 넣기 때문에 모델 parameter가 매우 많다. 논문에서는 다른 모델들에 비해서 학습시간이 짧다하고 얘기하지만 개선 여지가 보인다. 이를 보완한 논문은 추후에 정리하겠다.)
3. FM + Deep component
위의 두 모델로부터 나오는 output을 각각 와 이라 할 때, DeepFM은 이를 더해 sigmoid 함수에 넣은 값을 output으로 출력한다.
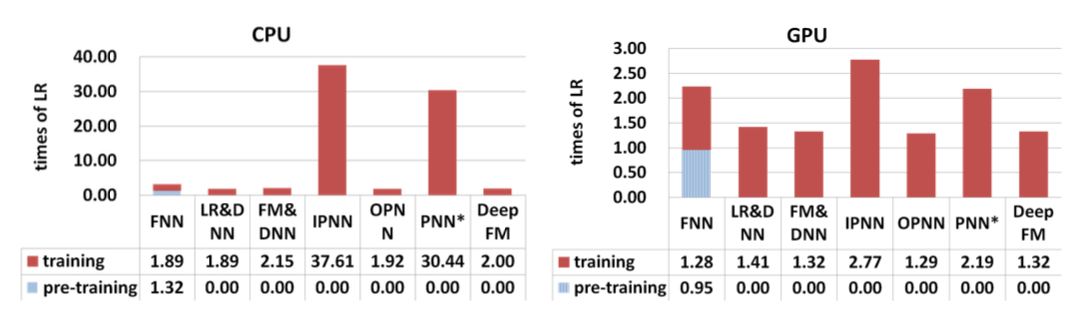
실험 결과 (Experimental results)
해당 논문에서는 Criteo, Company dataset 이 두 개의 데이터셋에 대해서 실험을 진행한다. 평가지표로는 AUC와 log loss로 삼아 AUC는 높고, log loss는 낮다는 것을 보였다. (아래 표 참고)
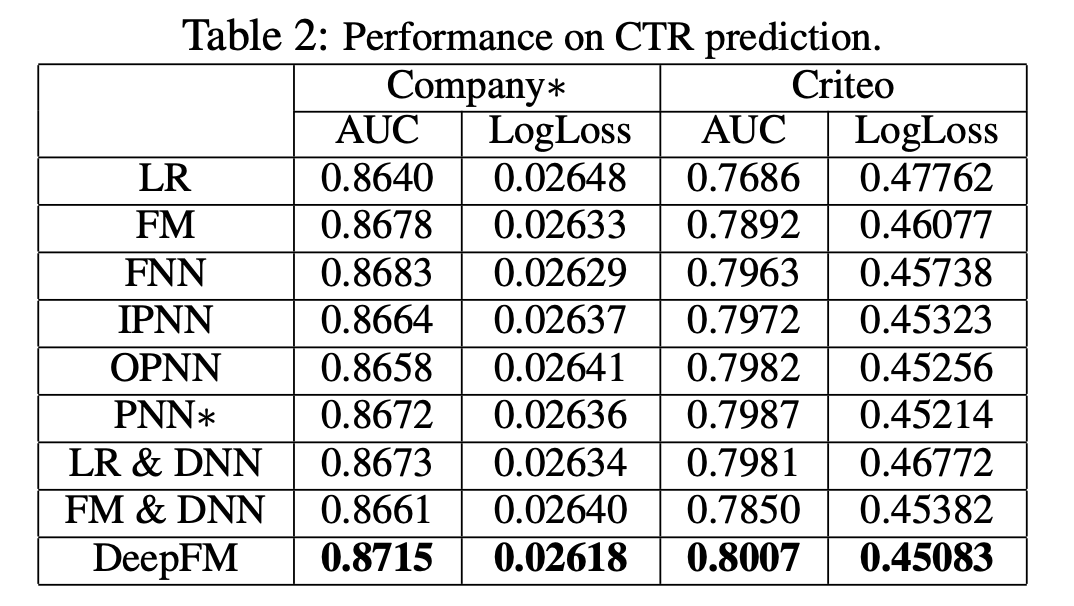
또한, cpu와 gpu를 사용하여 학습 시간을 측정하여 다른 모델들에 비해 월등한 성능을 보였다.
정리 (Conclusion)
DeepFM은 다음과 같은 장점이 있다.
-
Pre-training이 필요없어 end-to-end 학습이 가능하다.
-
FM component와 deep component을 동시에 학습함으로써, 저차원 및 고차원 특징 상호작용을 동시에 학습할 수 있다.
-
Feature 임베딩 벡터를 도입함으로써 feature engineering 작업이 불필요하다.
