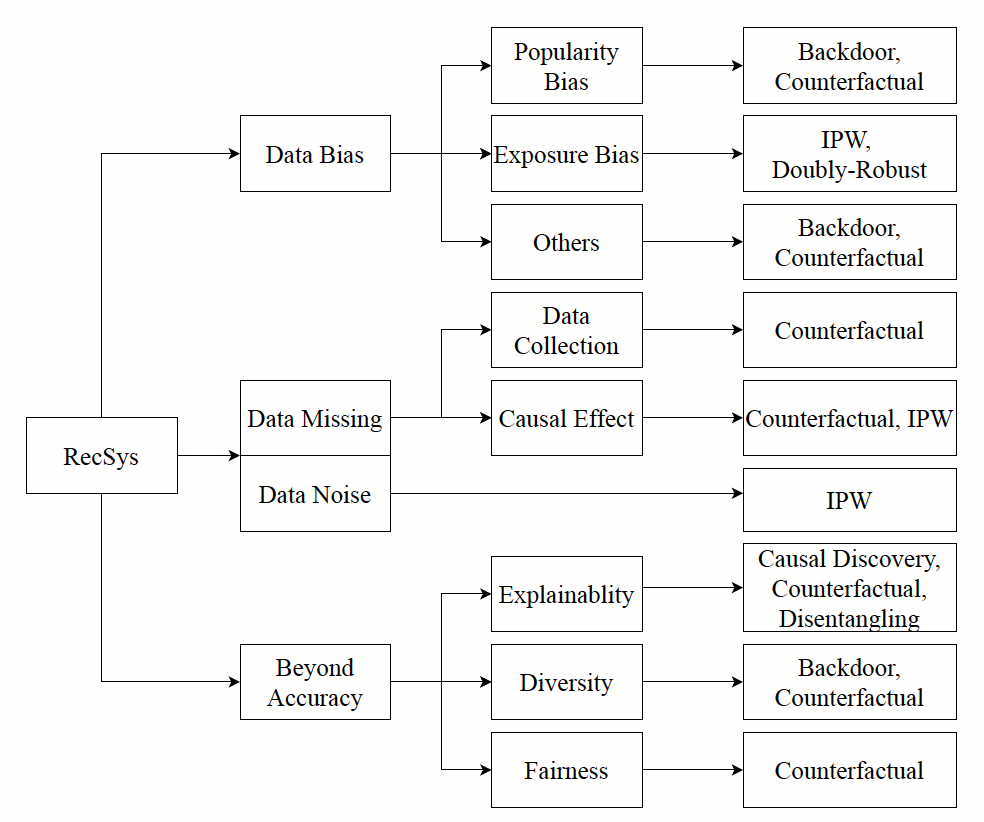
이번 포스팅에서는 인과추론을 추천시스템에 적용 방법에 대해서 알아보겠다. 이에 관련해서 최근에 많은 방법들이 제시되고 있고 방법론들을 정리한 표가 아래와 같다.
1. 데이터 편향 제거
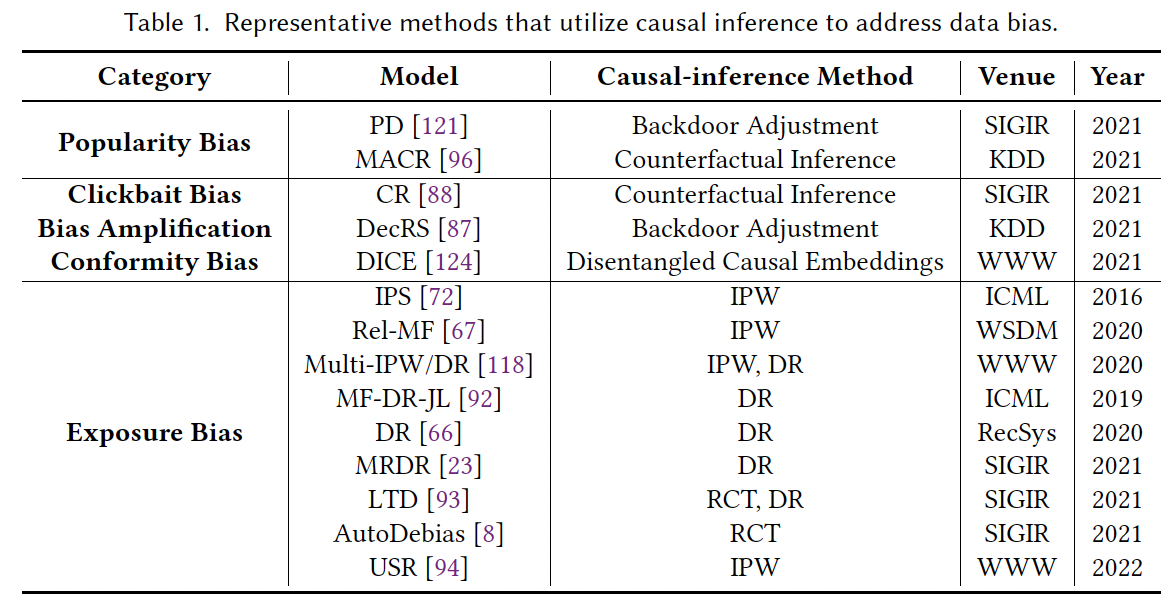
현존하는 방법은 3 개의 카테고리화할 수 있다: confounding effect, colliding effect, counterfactual inference.
1) Confounding effect
대다수의 경우에 편향은 혼란변수(confounder)에 의해 발생된다. 이를 제거하기 위해서 2 가지의 인과추론 프레임워크 하에서 많은 연구들이 진행되고 있다.
(1) Structure Causal Model (SCM)
SCM 프레임워크에서는 backdoor와 frontdoor adjustment를 통해 편향을 제거한다. Backdoor adjustment란, 개입(intervention)을 통해 혼란변수가 treatment에 끼치는 영향을 막는 기법이다. Data generating process (DGP)에서 인과관계를 그래프로 그리고, 혼란변수을 밝혀내고, backdoor adjustment 기법을 통해 인과적 효과를 추정한다.
이를 활용한 논문은 "Causal Intervention for Leveraging Popularity Bias in Recommendation (SIGIR'21) 이다. 위 테이블에서 PD[121]에 해당하는 논문이다. 해당 논문에서는 아이템의 인기정도가 아이템 노출정도와 우리가 관측하는 데이터에 동시에 영향을 줘서 인기편향을 발생시킨다고 주장한다.
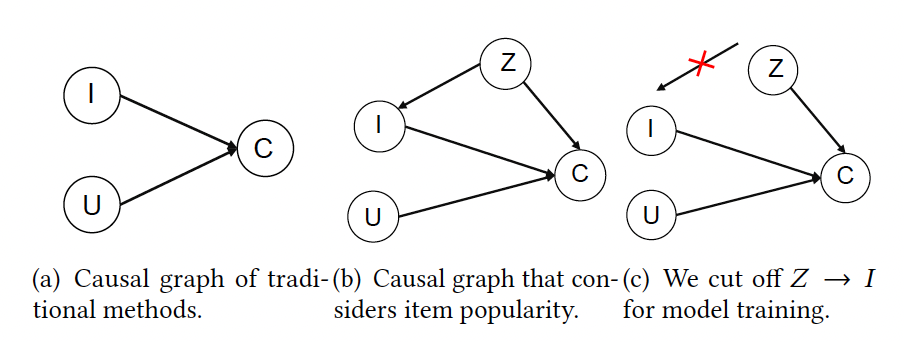
그래서, backdoor adjustment를 통해 아이템의 인기 정도(Z)가 아이템(I) 노드에 주는 영향을 끊어내고 모델을 학습한다. (위에서 그림 c)
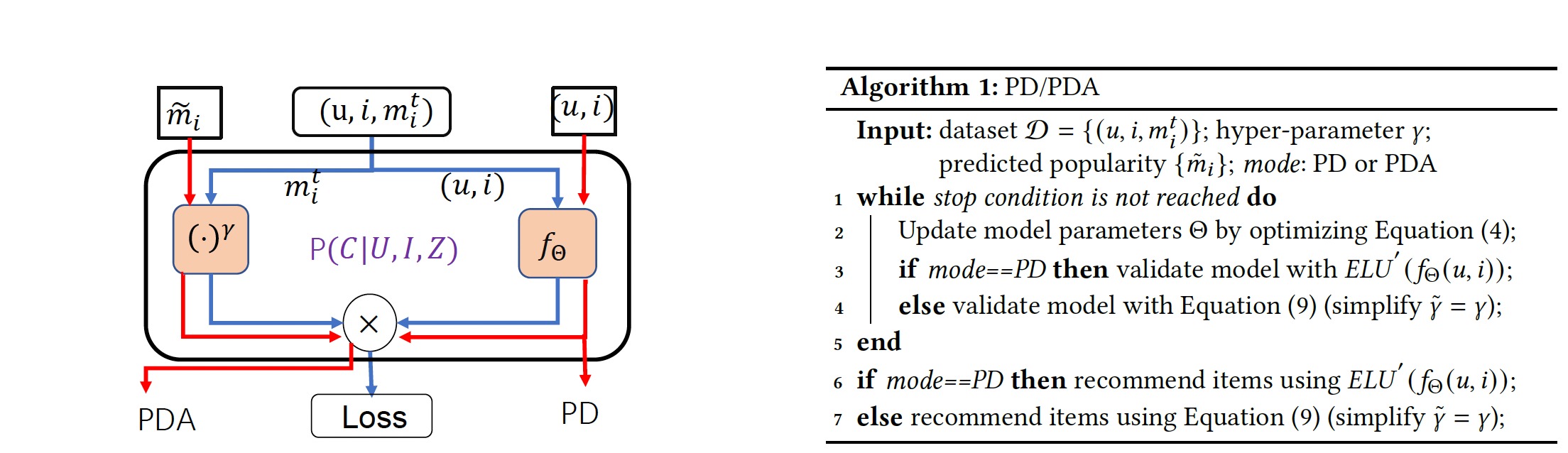
(2) Potential Outcome (PO)
PO 프레임워크에서는 unbiased leaerning을 목표로 한다. 약간의 수학기호를 도입해서 설명하자면, 를 노출여부를 나타내는 확률변수라고 정의하고 을 아이템 가 유저 에 추천되었다는 걸 뜻하자고 하자. 우선, 인과추론에서 유명한 "Inverse propensity weighting (IPW)" 기법을 설명하자면, 목적 함수는 아래와 같다:
여기서, 은 propensity score로 유저-아이템 피드백 를 관측할 확률을 뜻한다.
하지만, 이 기법의 단점이라고 하면 propensity score를 추정하기 힘들 뿐더러, score가 매우 작은 값이 되어버리면 전체 목적함수가 매우 커지기 때문에 variance가 높다는 점이다. 이를 보완하기 위해서 제안된 인과추론에서의 또 다른 기법인 "Doubly Robust (DR)" 기법을 설명하자면, 목적 함수는 아래와 같다:
여기서, 은 imputation (결측값 대체) 모델의 출력값이다. 이 imputation 모델을 학습하기 위해서, joint learning을 통해 아래의 목적 함수도 동시에 최소화시킨다:
최종 목적 함수는 아래와 같다:
2) Colliding effect
인과 관계를 조사하여 상호 작용 생성 과정에서 많은 collider 구조를 발견할 수 있다. 대표적인 경우는 여러 가지 다른 변수가 관찰된 상호 작용에 영향을 미치는 것이다. 사용자 관심사와 순응과 같이 수집된 사용자 상호 작용에 대한 조건을 설정하면 사용자 관심사와 순응 사이의 상관 관계가 발생한다. 순응에 의해 유발된 상호 작용은 무관심할 확률이 더 높다. 순응 편향을 완화하기 위해 "Disentangling User Interest and
Conformity for Recommendation with Causal Embedding" (WWW'21) 논문에서는 원인별 데이터를 사용하여 관심사와 순응 표현을 분리(disentangle)하며 이로써 사용자 표현의 견고성과 해석 가능성을 향상시킨다.
3) Counterfactual inference
편향 제거를 위해 사용된 또 다른 SCM 기반 기법은 반사실적 추론 (counterfactual inference)이다. 이는 추천의 편향을 줄이기 위해 경로 특정 인과효과를 제거하는 데 사용된다. 특히, 일부 사용자/아이템 특성은 상호 작용 예측을 위한 편향을 일으킬 수 있으며, 정확한 선호도 추정을 방해할 수 있다. 반사실적 추론은 경로 특정 인과 효과를 추정하고 부분적인 사용자/아이템 특성의 인과 효과를 제거할 수 있다. 구체적으로 이는 특정 경로를 따라 이러한 특성 없이 반사실적적인 세계를 상상하고, 그 후 사실적인 세계와 반사실적적인 세계를 비교하여 경로 특정 인과 효과를 추정한다. 관련된 연구를 한 논문은 "Clicks can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue." (SIGIR'21)와 "Model-agnostic counterfactual reasoning for eliminating popularity bias in recommender system" (SIGKDD'21)이 있다.
